 夜雨聆风
夜雨聆风





用AI造出1000台“合成电脑”,让智能体在长期生产力任务中自我进化
想象一个金融顾问,她的电脑上存放着多年的投资政策声明、VCMM市场模型预测、客户投资组合分析表格、季度业绩报告和与同事的协作记录。如果AI智能体要真正帮助她完成一个为期一个月的复杂项目——比如刷新模型投资组合、同时评估另类投资策略——它需要理解这些文件的历史脉络,浏览文件夹结构找到正确资料,与模拟的同事沟通协调,并反复修改交付物。
这听起来很理想,但在现实世界中,这样的训练数据几乎无法获取。用户的电脑环境是私密的,包含个人文件和企业文档,我们不能为了训练AI就去收集这些数据。长期以来,AI在长期生产力任务上的进步受到这一根本限制。
微软研究院最新提出了一种创造“合成电脑”的方法论,不仅能够大规模构建具备丰富上下文、用户专属的虚拟计算环境,还能让AI智能体在其中完成长达数月的生产力模拟,从而获得宝贵的“体验式学习信号”。
论文信息
标题:Synthetic Computers at Scale for Long-Horizon Productivity Simulation
机构:Microsoft
论文地址:https://arxiv.org/abs/2604.28181
导读
当前AI智能体正从简单的对话助手转向长期任务的执行者,例如编程、文件管理和专业交付物制作。然而,真实的生产力工作高度依赖于用户特定的计算机环境:文件目录结构、历史项目文档、以及跨文件的依赖关系。这种对私有环境的依赖使得收集真实人类轨迹用于训练变得极其困难,也让纯合成数据面临“玩具化”的风险。
本文提出的方法直击这一痛点:通过从大规模的人物画像(personal profile)出发,逐步构建出逼真的合成电脑环境,并在其上运行长时间跨度的生产力模拟。这不仅产生了一批高质量的训练轨迹,更在实验中被证明能够显著提升AI智能体在实际生产力基准上的表现。这是一个从无到有创造“工作经验”的系统性方法论。
方法:如何从零构建一台“合成电脑”并让它“工作”
整个方法论分为三个核心阶段,每一步都旨在确保合成环境的真实性和复杂度。
阶段一:从人物画像到用户档案
一切始于一个粗略的人物画像。例如:“一位关注资产配置的金融顾问。” 单凭这一句话,我们无法知道她的电脑里应该放着什么。因此,研究者首先通过大模型将这个画像扩展为详细的用户档案。
这个档案不仅包括职业背景、组织、职责和近期项目,还涵盖了极其关键的 计算机使用习惯:常用文档格式(Excel vs. Word)、文件命名风格、附件保存习惯,甚至对文件夹组织的整洁程度。这些细节决定了之后创建的文件系统结构是否符合“真人”的习惯。
阶段二:规划计算机环境
有了详细的用户档案后,下一步是为这台计算机规划文件系统。这不仅仅是随机生成一堆文件,而是一个严谨的计划过程:
1. 生成文件系统策略:根据用户习惯,制定文件系统的基本规则,比如默认存储路径、组织风格和命名偏好。
2. 规划文件清单:根据用户当前的项目和职责,推断出应该存在哪些文件。这包括文件的逻辑路径、类型、描述、时间戳,以及最重要的——文件间的依赖关系。
3. 构建依赖图:这是一个核心创新。现实世界中的文件不是孤立的。一份Excel分析表格可能依赖于一份下载的PDF报告,而后续的备忘录又基于这个Excel表格。通过构建依赖图,可以确保生成的后续文件是基于前一版本文件发展的,从而模拟出真实的工作累积过程。

图:文件依赖图,清晰展示了文件之间的衍生和引用关系,例如PDF来源、衍生出的Excel工作表和进一步合成出的演示文稿。
阶段三:实例化人造物
基于依赖图,模型开始按顺序创建内容丰富的文件。如果某文件是公开可下载的PDF,模型会优先从网络获取,否则才进行合成。对于用户自创的文件(如Word文档、Excel表格、PPT演示稿),智能体被配备专门的工具(如minimax-docx、minimax-xlsx)来生成内容,确保其格式和专业度。
通过这种方式,一台初始拥有约112个文件的“合成电脑”就诞生了,其文件类型分布如下:
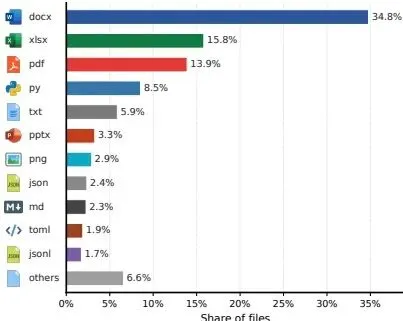
图:文件类型分布。DOCX、XLSX、PDF和PPTX占了绝大部分,这与真实生产力环境中办公文档为主的特征相匹配。
阶段四:长期生产力模拟
电脑创建好之后,就进入最关键的模拟阶段。这个阶段包含了两个不同角色的AI智能体:
设置智能体 (Setup Agent)
它的任务是“定制任务”和“创建协作圈”。
• 制定生产力目标:基于用户档案和电脑现状,黑体制定出具体、有挑战性且大致相当于一个月人类工作量的一系列交付物。例如,对于那位金融顾问,任务可能包括:“完成VCMM模型投资组合刷新”、“为另类资产整合撰写最终投资委员会建议”。
• 创建模拟协作者:为了模拟真实工作中的协作,设置智能体还会创建一系列的模拟协作者,如老板、同事、客户、合规官等。每个协作者都被赋予详细的背景、沟通风格,甚至保密的参考文件。比如,一位严厉的老板会要求“任何模型波动超过150个基点都需要敏感性分析”,而这些信息只有在智能体主动沟通时才会被分享。
工作智能体 (Work Agent)
这是模拟中的“主角”。它扮演电脑的使用者,接收生产力目标,然后被“放进”合成电脑中,开始为期一个月的工作。
• 周计划与日执行:模拟以周和天为周期运行。工作智能体需要制定周计划,并每天执行计划中的具体活动。这些活动包括:阅读现有文件、创建/修改文件、发送邮件给模拟协作者。
• 关键能力:导航、交互与迭代:与协作者的互动是关键。例如,智能体可能需要向同事要一份老旧数据,或者在提交初稿后收到合规官的反馈并据此修改。
这个模拟过程会持续数千轮对话(平均2272轮),耗时超过8小时。最终,合成电脑里的文件从约112个增长到约197个,智能体也完成了一系列专业的交付物。
实验和结果:从模拟中提取“经验”并验证其价值
研究团队创建了1000台合成电脑,并运行了相同的模拟。但真正的实验在于验证从这些模拟中提取的经验是否能帮助AI变得更好。
提取“职业技能”
研究者从900个模拟的回顾报告中提取频率最高的教训和成功模式,然后由一个大模型将这些总结成 “职业技能”(Occupation-specific skill) 。例如,针对金融顾问职业的技能可能包含:
• “敏感性分析:任何敏感性表格必须逻辑自洽,坏的情况产生更坏的结果。”
• “版本纪律:一旦版本被分享,就成为了那个审查周期的官方记录。不要重用版本号,错误修复必须是v1.2,而不是修改v1.1。”
这些技能就像一种可以注入AI智能体的“记忆”或“提示词”。
领域内评价 (In-Domain Evaluation)
在100台保留的合成电脑上,研究者比较了: (1) 基础版工作智能体 vs. (2) 装备了提取到的“职业技能”的增强版。结果如图:

图:领域内评价结果。装备了职业技能(经验信号)的智能体,在100台测试电脑上的平均得分从61.6%提升到了68.6%,并在83台电脑上表现优于基础版。
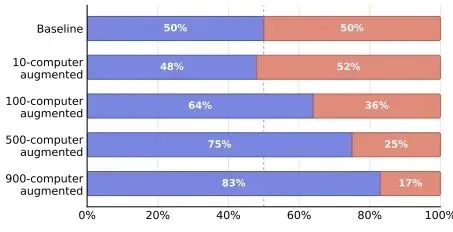
图:随着用于提取经验的训练电脑数量(N)增加,技能增强版的表现也稳步提升。这证明该方法的扩展性:数据越多,经验越“结实”,效果越好。
领域外评价 (Out-of-Domain Evaluation)
更令人兴奋的是,这些技能不仅在自己的合成世界里有效,还能迁移到其他完全不同的生产力基准测试(GDPVal)上。GDPVal包含220个真实世界的生产力任务,形式与本文的模拟大相径庭。结果图显示,装备了从合成电脑模拟中提取出的技能的智能体,在各种模型(Sonnet, Haiku, Opus)上都普遍胜出,尤其是在主力模型Sonnet上,取得了105胜67负的显著成绩。
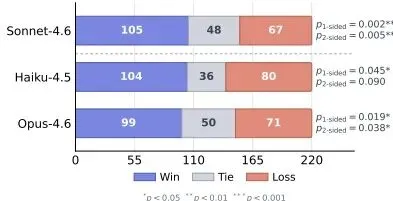
图:领域外(GDPVal基准)评价结果。在220个任务中,装备技能的Sonnet智能体显著胜出,证明了技能的强泛化性。
结论
这项工作展示了一个极其有前景的前景:我们不再需要等待真实世界中的用户行为数据来训练生产力AI。通过“合成电脑”这个高保真的“沙盒”,我们可以让AI智能体在其中从事各种职业、完成复杂任务、与协作者互动,并从这些经历中学习。这个方法论指出了通往 “自我完善的智能体”(Self-improving Agent) 的道路:模拟产生经验,经验变成技能,技能改善行为,改善后的行为用于进行更高质量的模拟,形成一个正反馈循环。
随着我们构建的合成电脑数量从1000增长到百万、十亿级别,AI对人类复杂、长期、依赖上下文的专业生产力的模拟和理解能力,将有望发生彻底的改变。
关注「AI论文热榜」,紧跟最前沿、最硬核的AI技术进展!
如有项目开发、科研指导等需求,请联系小编,微信号: GCgcong