 夜雨聆风
夜雨聆风





当 AI 巨头遇见精神基因组学:在 Hugging Face 深度挖掘 10 亿行 PGC 疾病数据
引言:不只是 Chatbot,这是生命的“代码库”
提到 Hugging Face,大部分人的第一反应是大语言模型(LLM)、Chatbot 和各种生成式 AI 的炫酷 demo。
但如果你认为它只是个“调包工具站”,那就大错特错了。
今天,我们要聊的是它在医学研究领域发起的一场 “静默革命”——
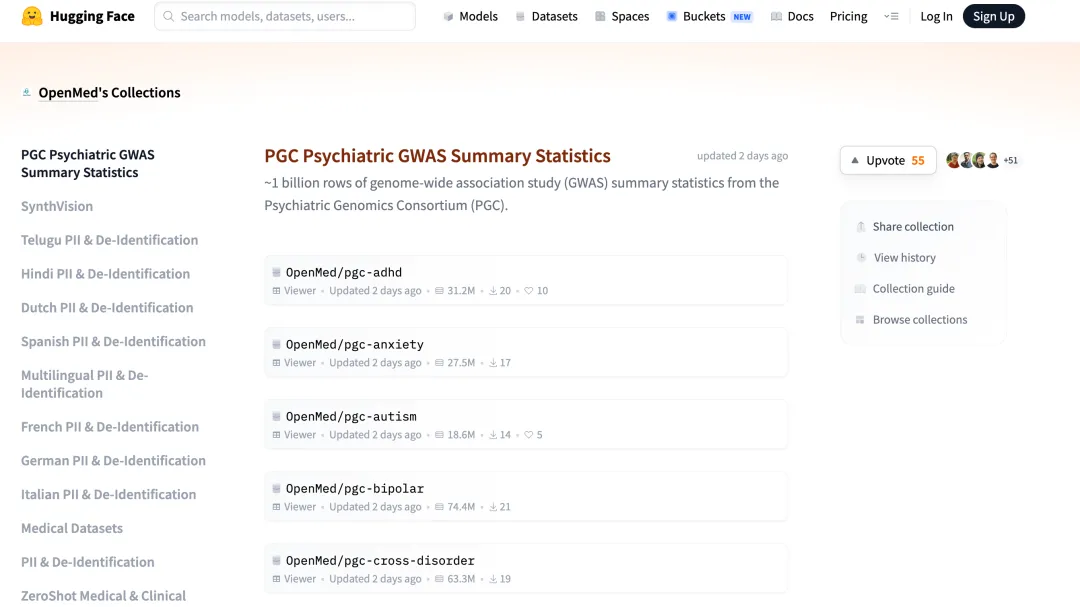
一个名为 OpenMed 的团队,刚刚在 Hugging Face 上发布了高达 10 亿行的精神疾病 GWAS 汇总统计数据。
是的,你没看错:10 亿行。而且,任何人都可以免费获取。
1. 什么是 Hugging Face?—— AI 界的“中央车站”
Hugging Face 是目前全球最活跃的开源 AI 社区,被很多开发者亲切地称为 “AI 界的 GitHub”。
但它能做的远不止托管模型:
-
不仅仅是模型:它提供了一个统一的平台,同时托管着模型(Models)、数据集(Datasets) 和演示应用(Spaces)。
-
低门槛接入:以前下载几百 GB 的科研数据,你可能要折腾复杂的 FTP 配置、填写冗长的权限申请表、等待审核……但在 Hugging Face 上,这一切被压缩成几行 Python 代码。
举个例子:
python
from datasets import load_datasetdataset = load_dataset("OpenMed/pgc-mdd", split="train")
就这么简单。全球顶尖的科研成果,直接“流”进你的实验室。
2. 为什么要在 Hugging Face 上跑医学大数据?
做过流行病学或公共卫生研究的朋友都懂一个“血泪规律”:
数据清理和格式统一,往往占据整个项目 80% 的时间。
不同课题组的数据格式千奇百怪,列名不统一、编码方式各异、缺失值标记混乱……光是让数据“能跑起来”,就能耗掉一个硕士生好几个月。
Hugging Face 的介入,彻底改变了游戏规则:
✅ 流式加载(Streaming)
面对 10 亿行数据,你不需要一次性把几百 GB 下载到本地硬盘。可以边读边算,像刷短视频一样“刷”数据。这意味着:
-
普通笔记本电脑也能分析海量基因组数据
-
节省大量存储成本和下载时间
✅ 版本控制
数据更新全程透明,每一版修改都有记录。谁在什么时候改了哪一行数据,一目了然。这对于科研的可重复性至关重要。
✅ 无缝对接 AI
数据格式原生支持 PyTorch 和 TensorFlow。想用深度学习模型预测多基因风险评分(PRS)?不用写一堆蹩脚的格式转换脚本,拿来就能用。
3. 重头戏:PGC 精神疾病 GWAS 汇总统计数据
这次 OpenMed 发布的 PGC(Psychiatric Genomics Consortium,精神疾病基因组学联盟) 数据集集合,堪称精神医学研究者的 “金矿”。
📊 数据亮点
覆盖广度:涵盖了从抑郁症(MDD)、精神分裂症(SCZ)到自闭症(ASD)、多动症(ADHD)等十余种主流精神疾病。
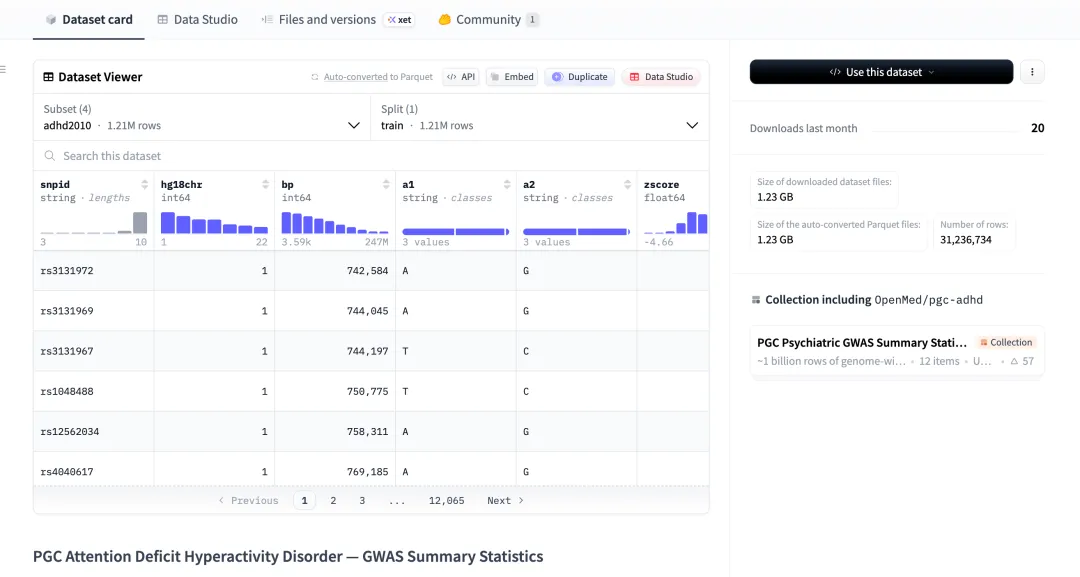
数据深度:单个抑郁症数据集(pgc-mdd)就包含超过 2.15 亿行 记录。
实战价值:这是目前全球样本量最大、公信力最高的精神疾病基因组研究成果汇编,没有之一。
📋 重点数据集一览
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这还只是冰山一角。ADHD、自闭症、双相情感障碍……你能想到的精神疾病,这里几乎都能找到。
4. 实战:如何用几行代码挖到“金矿”?
光说不练假把式。下面教你真正跑起来。
快速预览数据
python
from datasets import load_dataset# 仅加载抑郁症数据的开头部分(流式模式,不下载全量)dataset = load_dataset("OpenMed/pgc-mdd", split="train", streaming=True)# 查看第一条数据长什么样print(next(iter(dataset)))
转换成 Pandas DataFrame(适合小规模分析)
python
# 只取前 1000 行做探索性分析small_sample = dataset.take(1000)df = small_sample.to_pandas()print(df.head())
结合 PyTorch 做简单分析
python
from datasets import load_datasetimport torchdataset = load_dataset("OpenMed/pgc-mdd", split="train", streaming=True)# 假设我们要取前 10000 行的某个数值列做简单统计p_values =[]for i, example inenumerate(dataset):if i >=10000:break p_values.append(example.get("p_value",0))# 转换成 tensorp_tensor = torch.tensor(p_values)print(f"P值分布:均值 {p_tensor.mean():.4f}, 标准差 {p_tensor.std():.4f}")
💡 小贴士:完整的数据集字段说明,建议去 Hugging Face 数据集页面查看“Dataset Card”,里面有详细的列名解释和使用规范。
5. 这意味着什么?—— 数据民主化与精准医疗的未来
在过去,能接触这种规模基因组数据的,往往只有顶尖高校和药企的“大实验室”。
现在,一个学生或独立研究员,在自己的笔记本电脑上,就能调用全球最顶尖的医疗大数据。
这才是真正的 “数据民主化”。
在精准医疗的今天,我们其实并不缺少数据,而是缺少高效利用数据的工具和方法。
通过 Hugging Face 获取 PGC 数据,意味着:
-
更快的科研迭代:不用再花半年申请数据、三个月清理格式
-
更高的可重复性:每个分析步骤都有据可查
-
更低的准入门槛:让更多有想法的研究者能参与进来
结语:是时候升级你的“工具箱”了
如果你正从事生物信息学、流行病学或精神医学研究,是时候把你的 git clone 和手动下载,换成 Hugging Face 的 datasets 了。
10 亿行基因数据,一行 Python 代码。
这不是科幻,这是 2024 年就已经发生的现实。
💡 极客小贴士(For Developers)
想要快速预览这 10 亿行数据?一行命令就够了:
python
from datasets import load_dataset# 流式加载,内存友好dataset = load_dataset("OpenMed/pgc-mdd", split="train", streaming=True)# 只看第一条print(next(iter(dataset)))
推荐环境:
-
Python 3.8+
-
datasets库最新版 -
如果只想探索数据,8GB 内存的普通笔记本完全够用
作者注:本文数据来源于 Hugging Face 上的 OpenMed 组织发布的开源数据集。使用前建议阅读相应数据集的使用许可和引用规范。
