谷歌开始卖 TPU:AI 算力战争,从租云进入卖芯片
这两天看到一则很有分量的行业新闻:谷歌打破了 TPU 长期以来主要“只租不卖”的商业边界,开始向一部分精选大客户直接销售自研 AI 芯片。叠加强劲财报和谷歌云的高增长表现,谷歌的股价也在市场上明显走强。
单看标题,这似乎只是 AI 芯片市场里又多了一条动态。但在我看来,真正重要的地方不是谷歌短期能卖出多少 TPU,也不是它会不会立刻撼动英伟达,而是它透露出一个更深层的变化:云厂商的自研芯片,正在从内部降本工具,变成可以对外输出的基础设施产品。
过去几年,AI 算力的主流叙事一直是“上云”。企业不必自建昂贵的数据中心,也不必自己采购复杂的硬件,只要租用云厂商提供的 GPU 或 TPU 算力,就能快速启动模型训练和推理服务。云厂商负责机房、电力、网络、服务器和运维,客户只需要为使用量付费。
但 AI 进入大模型时代之后,情况开始变化。对于普通企业来说,租云依然是最方便、最经济的选择;可对于 AI 实验室、头部金融机构、高性能计算团队,以及那些长期、大规模消耗 AI 算力的组织而言,算力已经不再是一个普通成本项,而是决定长期竞争力的战略资产。
这类客户关心的不只是“有没有算力”,还包括数据放在哪里、延迟能不能控制、集群调度是否可控、故障兜底如何设计、合规边界是否清晰。对于他们来说,完全依赖外部云资源,有时并不能满足业务和战略上的全部要求。谷歌这次把 TPU 交付到客户自有数据中心,本质上就是对这类需求的回应。
过去,谷歌 TPU 的角色边界非常清晰:对内,它支撑搜索、广告、DeepMind、Gemini 等核心业务;对外,它主要通过谷歌云以云服务形式提供,客户可以使用 TPU 算力,但硬件本身仍然留在谷歌的数据中心里。现在,谷歌把这条边界往外推了一步。客户不只是“租用”TPU,而是有机会把 TPU 放进自己的基础设施体系。
这一步看似只是销售方式的变化,其实会改变云厂商和大客户之间的关系。过去云厂商像是算力房东,客户租用资源;现在,云厂商正在变成基础设施总包商,把芯片、网络、软件栈和集群管理能力,一并向客户输出。AI 时代的云,不再只是远程数据中心,而是在向客户自己的机房延伸。
这里有一个容易被忽视的前提:谷歌不是 AI 芯片赛道的新玩家。TPU 从诞生之初,就是为机器学习工作负载设计的专用芯片。它的优势不在于像 GPU 那样追求广泛通用性,而在于能够围绕谷歌自己的模型、编译器、网络、存储和数据中心架构,进行端到端的协同优化。
我更愿意把 TPU 理解成机器学习工厂里,一条经过全链路验证的专用生产线。它不是一颗孤零零的芯片,而是嵌在谷歌整个 AI 系统里的关键部件。谷歌有真实而庞大的 AI 应用场景,有持续迭代的 Gemini 和 DeepMind,有成熟的云平台,也有数据中心网络和大规模集群调度经验。这些能力叠在一起,才构成了 TPU 的特殊价值。
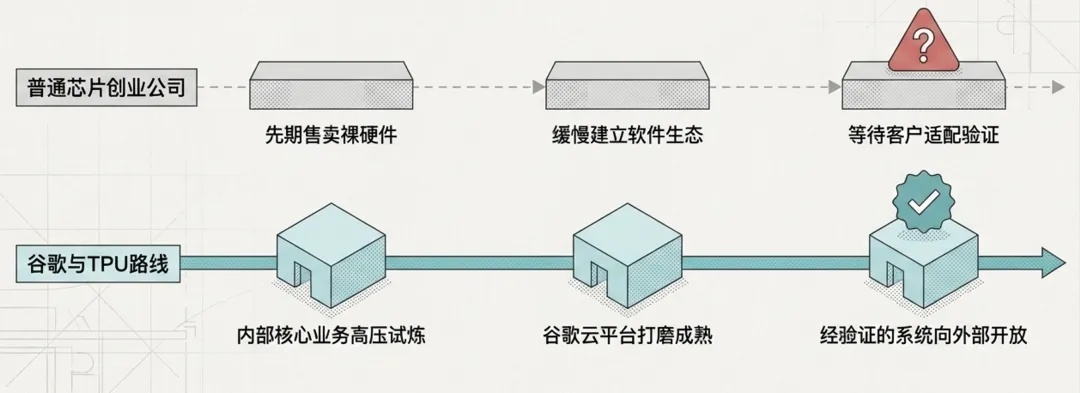
这也是谷歌和很多芯片创业公司不同的地方。普通芯片公司通常要先卖硬件,再慢慢建立软件生态,再等待客户适配;谷歌则反过来,它先在自己的业务和云平台里把 TPU 用起来,再把已经验证过的能力向外部客户开放。这条路径更慢,但一旦跑通,可信度也更高。
当然,这并不意味着英伟达的护城河会被快速冲垮。英伟达真正强的地方,不只是 GPU 的硬件性能,而是 CUDA、开发库、调试工具、训练框架适配、开发者习惯和供应链能力共同组成的生态。对一家 AI 公司而言,从英伟达迁移到另一套芯片体系,不是换一张卡那么简单,而是要对模型代码、训练流程、推理服务和运维体系做一整套改造。
所以,我不会把谷歌卖 TPU 解读成“正面取代英伟达”。更准确的说法是,谷歌正在给行业开辟第二条路线。未来的 AI 算力市场,大概率不会由单一架构通吃,而会变成分层结构:有些大规模训练继续依赖 GPU 集群,有些稳定推理任务会转向专用 ASIC,有些高频调用、模型相对固定、对成本敏感的场景,会更关注能效、供应稳定性和长期总成本。
有意思的是,谷歌并没有停止和英伟达合作。它一边在谷歌云中继续提供英伟达 GPU 实例,一边强化 TPU 的全栈能力。这种“两条腿走路”的策略很现实:主流客户仍然离不开英伟达生态,谷歌不能放弃这部分需求;但在可控场景里,它也需要用 TPU 建立差异化,降低对外部芯片供应的依赖,并把成本和性能优势转化为云业务的竞争壁垒。
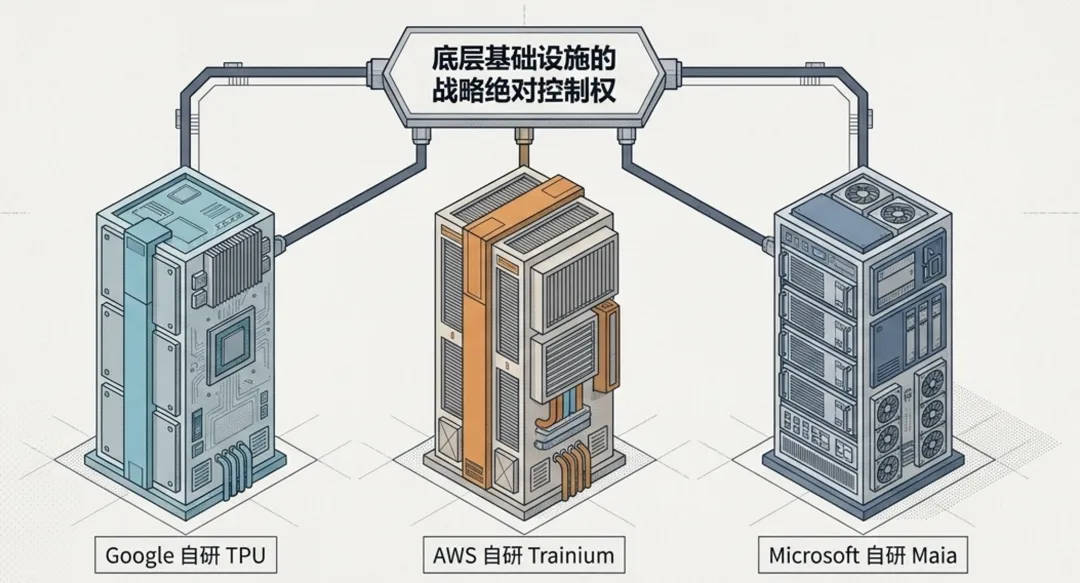
把视角放大,亚马逊在做 Trainium,微软也在推进自研 AI 芯片,背后的逻辑很相似:云巨头不可能把 AI 时代最核心的成本中心,完全交给外部供应商。GPU 仍然不可或缺,但当模型训练和推理成为长期基础设施开支,自研芯片就不只是技术探索,而是关乎财务成本、供应链安全和战略控制权的问题。
这也让英伟达处在一个微妙的位置。它最重要的大客户,正在变成它的“半个竞争对手”。云巨头还会继续大规模采购英伟达 GPU,但也会在适合的场景里推广自研芯片。短期内,这不会改变英伟达的中心地位;长期看,它会推动 AI 算力市场从高度集中,走向更多架构并存。
从商业模式看,TPU 对外售卖还释放了另一个信号:云计算的边界正在被重新定义。过去云厂商反复强调“不要自建,来用我的云”;但在 AI 时代,越来越多超级客户会因为数据主权、长期成本、延迟控制和安全要求,重新建设或强化自己的私有算力集群。如果云厂商只坚持把客户锁在自己的数据中心里,反而可能错过这批最有价值的客户。
当然,这条路不会轻松。首先,TPU 目前只面向精选客户,不会像普通服务器或消费级显卡一样开放购买;其次,软件生态仍然是最大门槛,开发者从熟悉的 GPU 体系迁移到 TPU,需要时间、工具和工程经验;最后,硬件销售和云订阅服务不同,收入会受到交付周期影响,不会像云服务那样平滑稳定。
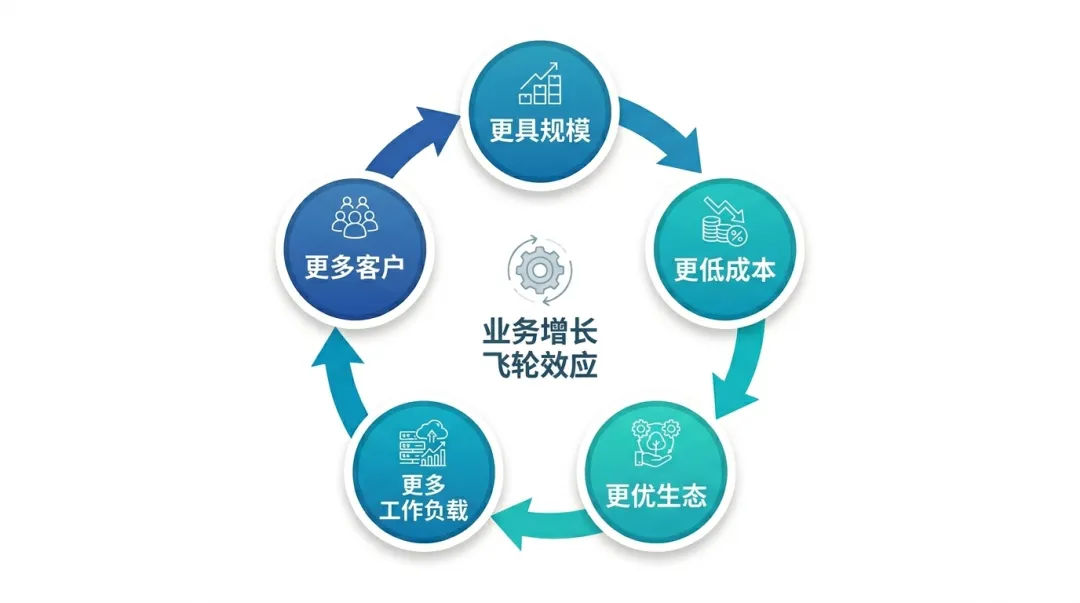
我判断,谷歌真正看重的,不是 TPU 硬件销售在短期内贡献多少收入,而是能否转动一个长期飞轮:更多客户使用 TPU,带来更大出货规模;更大规模摊薄研发和制造成本;成本下降与软件生态改善,又吸引更多 AI 负载迁移;更多负载落地,再反过来强化谷歌云在 AI 基础设施领域的形象。
如果这个飞轮转起来,谷歌卖的就不只是一颗芯片,而是一套 AI 算力生态。它的价值也不只体现在硬件收入上,还会体现在客户绑定、云业务增长、模型服务成本优化,以及对未来 AI 应用形态的控制力上。
这件事对国内科技公司同样有参考意义。AI 的长期竞争,不能只盯着模型榜单和应用热度。真正决定持续竞争力的,是底层基础设施能不能稳定支撑业务扩张:芯片供应是否可控,训练成本能否下降,推理成本能否支撑大规模商业化,软件栈能不能让开发者低成本迁移。模型是前台演员,算力系统才是托举一切的后台舞台。
把时间拉长看,AI 芯片市场可能会形成三类玩家并存的格局:第一类是英伟达这样的通用加速平台,继续占据生态核心位置;第二类是谷歌、亚马逊、微软这样的云巨头,用自研芯片服务自身云业务和超级客户;第三类是面向特定场景的定制 ASIC,在推理、边缘计算和行业专用任务中找到空间。AI 算力不会只有一个答案。
所以,谷歌卖 TPU 这件事,值得记住的不是一句简单的“挑战英伟达”,而是 AI 基础设施竞争维度正在变宽。过去我们比云规模,后来比模型效果,如今还要比芯片、网络、电力、机房和软件生态的整合能力。AI 进入深水区之后,竞争已经不再是单项冲刺,而是一场全栈系统工程的耐力赛。
在我看来,这才是新闻背后的长期意义。谷歌把 TPU 从自家机房推向客户的数据中心,是在告诉市场:AI 时代的云厂商,不再只是出租服务器的房东,而是要成为从芯片到模型、从数据中心到开发工具的基础设施总包商。接下来真正值得观察的,是有多少客户愿意把自己的 AI 战略,押注在英伟达之外的这条新路线上。
 夜雨聆风
夜雨聆风