 夜雨聆风
夜雨聆风





从源码读懂nanobot的运行原理(2):上下文管理机制
如果说大模型是智能体的大脑,那么上下文就是大脑当下的全部“工作记忆”,它承载着任务目标、用户消息以及大模型的中间推理过程,对于智能体准确理解意图和持续推理起着至关重要的作用。
本文通过对nanobot源代码的分析来全面解读其上下文管理机制。nanobot的上下文主要由三部分组成(如下图所示):系统提示词、会话历史(短期记忆)和当前用户消息。每当用户发送一条新消息,智能体就会动态组装这三部分,拼接成一条完整的上下文,再送入 nanobot 的 ReAct 循环进行处理。
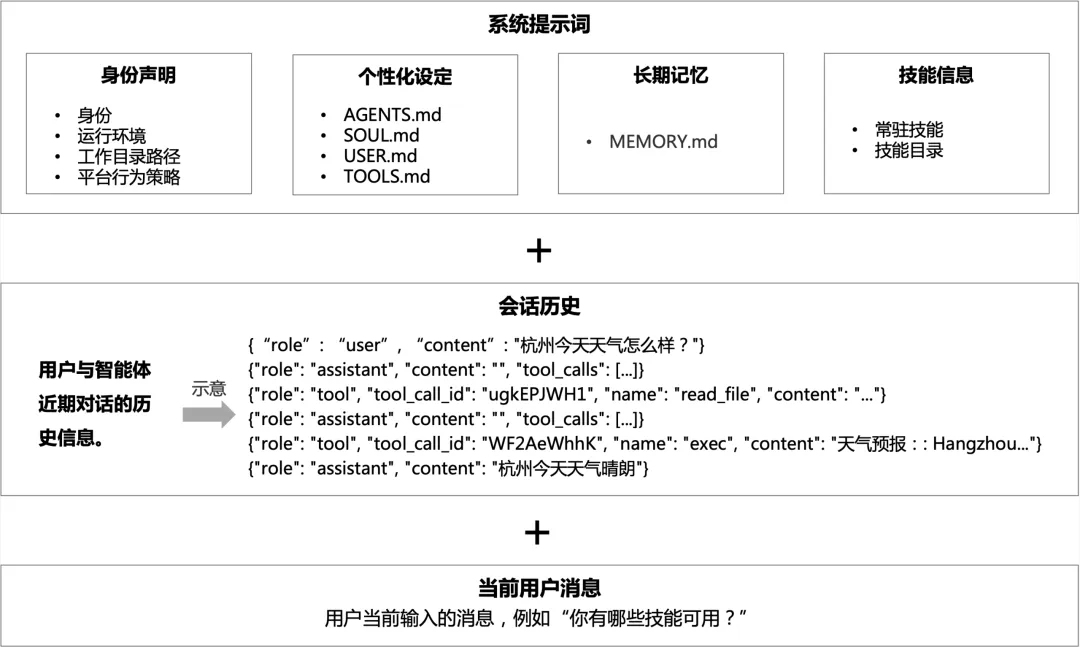
系统提示词由四部分内容组成
nanobot 的系统提示词并非固定文本,而是在每次处理用户消息时,由四部分内容动态组合而成,包括:智能体身份声明、智能体个性化设定、长期记忆和技能信息。
智能体身份声明
这部分提示词是对智能体自己身份的声明,描述了智能体“是谁”、运行在什么样的环境中,有哪些基本约束等。其中运行环境(例如操作系统类型、Python版本、工作目录路径)、工作目录路径等相关信息会根据所在机器的实际情况动态生成,其余身份声明则通过硬编码固化在系统中。
|
内容 |
用途 |
示例 |
|
身份 |
智能体的角色设定,告诉大模型它叫什么,它的定位是什么等。 |
You are nanobot, a helpful AI assistant. |
|
运行环境 |
描述智能体的运行环境。 |
macOS arm64, Python 3.11.5 |
|
工作目录路径 |
定义智能体的工作目录,以及长期记忆、技能等相关文件路径。 |
Your workspace is at: ~/.nanobot/workspace -Long-termmemory: ~/.nanobot/workspace/memory/MEMORY.md (write important facts here) |
|
平台行为策略 |
定义平台相关的行为策略,例如在Windows系统、类Unix系统上的基本策略。 |
You are running on a POSIX system. Prefer UTF-8 and standard shell tools. |
|
基本行为准则 |
定义模型调用工具时的一些基本规范。 |
Ask for clarification when the request is ambiguous. |
智能体个性化设定
主要包括四个文件:AGENTS.md、SOUL.md、USER.md 和 TOOLS.md。它们共同定义了智能体的完整人格与行为准则,统一存放在 ~/.nanobot/workspace/ 目录下。用户可以按需修改这四个文件,每次会话时,它们都会被动态加载进系统提示词,从而让智能体展现出持续且一致的个性。
|
文件 |
用途 |
示例 |
|
AGENTS.md |
定制智能体的行为规则。 |
强调行为准则,例如:You are a helpful AI assistant. Be concise, accurate, and friendly. |
|
SOUL.md |
定义智能体的“性格与灵魂”,决定其价值观和说话风格。 |
价值观:保护用户隐私和安全 沟通风格:简洁专业,短句为主。 |
|
USER.md |
用户档案和偏好,这是智能体对使用者的认知档案,记录用户身份、偏好等信息。 |
称呼:老板 偏好:偏好短句、观点明确 |
|
TOOLS.md |
工具使用相关说明。 |
exec工具安全限制:阻止危险命令,如rm -rf,format,shutdown等 |
长期记忆
智能体的长期记忆保存在 workspace 下的 MEMORY.md 文件中,构建系统提示词时会直接全文加载。该文件的内容由 LLM 生成并持久化,凝结了对用户画像的浓缩描述和关键事实,相当于智能体对用户的“长期印象笔记”。
技能信息
在 nanobot 中,技能的加载分为常驻加载和按需加载两种模式:
-
常驻技能:如果技能对应的 SKILL.md 文件中将 always 属性标记为 true,则表示该技能为高频使用技能,需要常驻在上下文中。此时,智能体会将 SKILL.md 的全部内容直接注入上下文,LLM 在推理过程中可以直接使用该技能。
-
按需技能:如果技能未设置 always 属性,或被标记为 false,则属于非高频技能。这种情况下,智能体在拼接上下文时只会加载技能的目录信息,而不会加载完整的 SKILL.md 文档。目录信息采用 XML 格式表示,包含技能名称、技能描述以及 SKILL.md 文件路径。当 LLM 在推理中发现需要用到该技能时,会先通过工具调用读取对应的 SKILL.md 文档,之后再根据文档内容使用这项技能。上下文中的技能目录如下图所示:
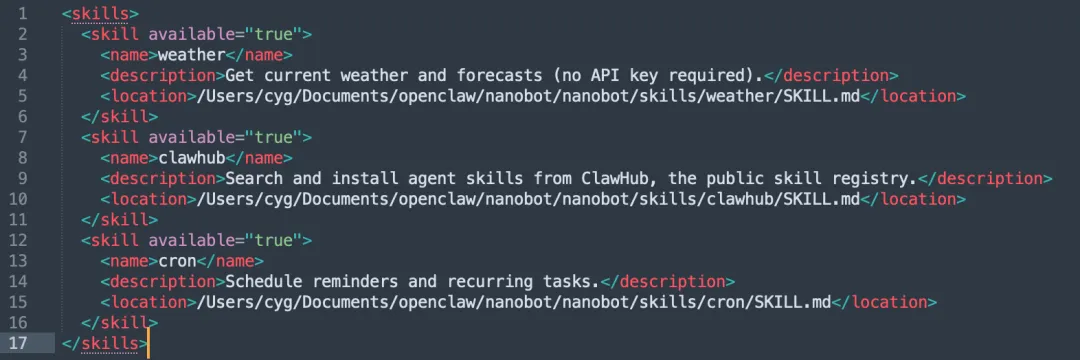
会话历史信息
每次处理用户消息时,智能体还会读取当前会话的历史记录,这些记录存储在~/.nanobot/workspace/sessions/目录下。为了避免上下文过长,nanobot 会对历史会话进行清洗和精简,每条记录只保留 LLM 最需要的6个字段(如下表所示),在保留关键信息的同时,有效控制 token 消耗。
|
字段 |
用途 |
|
role |
system、user、assistant、tool四类角色,表示这个信息是哪个角色产生的。 |
|
content |
该角色返回的消息文本。 |
|
tool_calls |
工具调用请求。 |
|
tool_call_id |
工具调用id,与 assistant 的 tool_calls.id 配对。 |
|
name |
工具名称,例如读取文件的工具名为’read_file’。 |
|
reasoning_content |
LLM的思维链。 |

随着对话增长,会话历史会不断膨胀。nanobot 采用了一套 token 驱动的压缩机制来限制上下文规模:当估算的 token 用量超出安全预算时,系统会将较早的消息交给 LLM 进行总结,提炼出的关键信息分别写入 MEMORY.md 和 HISTORY.md,并将压缩指针 last_consolidated 前推到已总结的位置。此后加载会话历史时,只会读取该指针之后的新消息,已压缩的旧内容不再重复占用上下文。
用户当前消息
用户当前输入的消息同样需要加载到上下文中,智能体同时会合并运行时相关元数据(例如时间戳,消息通道ID等),最终拼接为一条JSON格式的 user 消息。
本文对 nanobot 的上下文管理机制进行了解读。它通过动态拼接,让每次推理都建立在完整且最新的认知基础之上;通过会话历史压缩与消息精简,让对话历史在增长过程中适度“瘦身”;通过技能的分级加载,实现高频技能即时可用、低频技能按需激活。希望 nanobot 的这套设计思路,能为你在构建智能体时带来一些启发与参考。
– END –
往期内容精选: