 夜雨聆风
夜雨聆风





AI基础设施全景投资指南
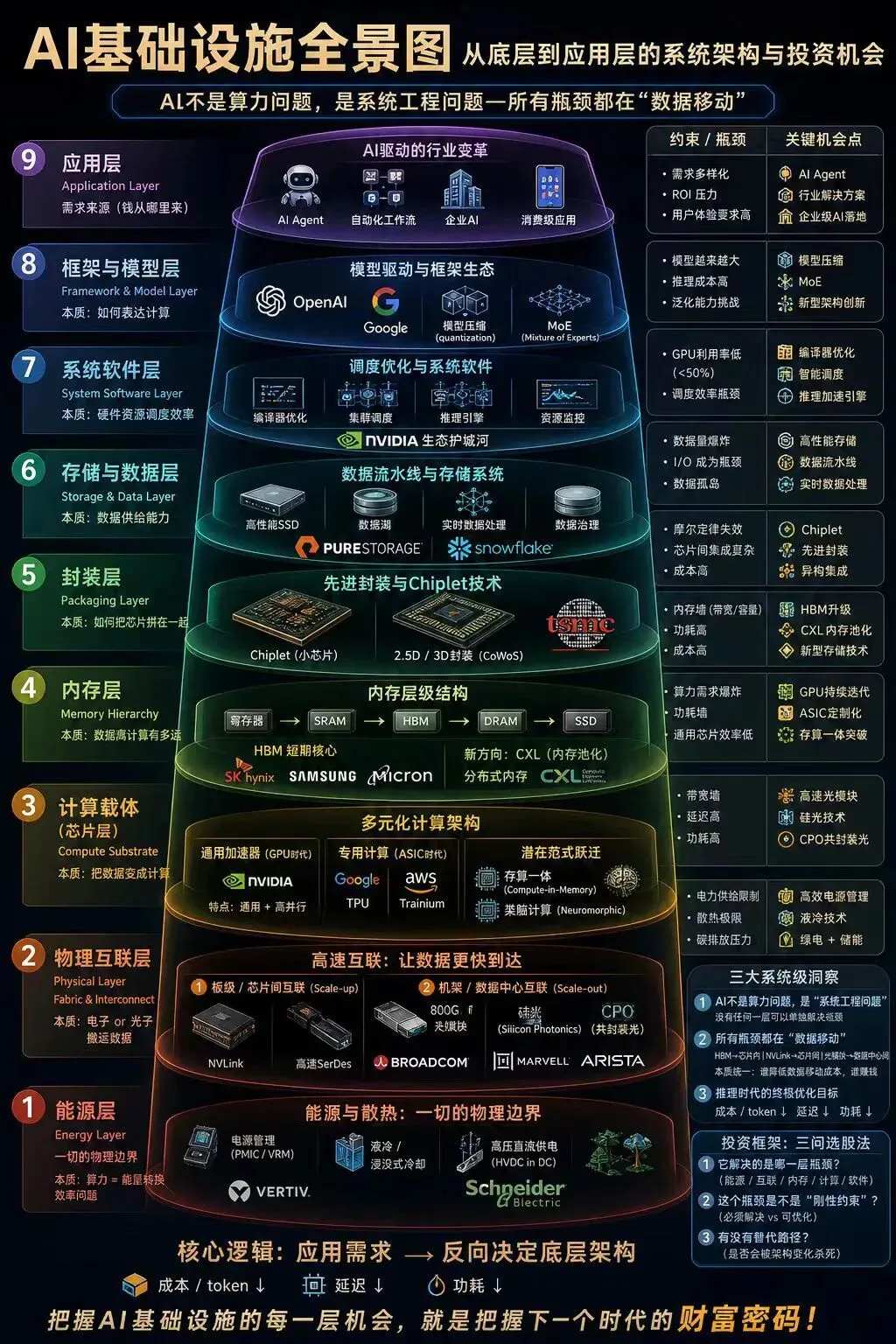
开篇:AI 不是算力问题,是系统工程问题
2026 年的今天,当我们谈论 AI 投资时,绝大多数人还在盯着 “算力” 这个词。英伟达的财报一出来,整个市场就像打了鸡血一样狂欢。但如果你真的看懂了这张 AI 基础设施全景图,你会发现一个颠覆性的真相:
AI 不是算力问题,是系统工程问题 —— 所有瓶颈都在 “数据移动”
这不是一句空洞的口号,而是整个 AI 产业最底层的商业逻辑。当一颗 GPU 芯片的算力每两年翻 5 倍的时候,数据在芯片之间、芯片与内存之间、内存与存储之间移动的速度,却只提升了不到 30%。这就像你给一辆跑车换上了 F1 的发动机,却还在用自行车的链条传动。
今天,我们就沿着这张全景图的 9 个层级,从最底层的能源开始,一路向上攀登到应用层,逐一拆解每一层的投资逻辑、技术瓶颈、发展趋势和具体标的。记住这句话:把握 AI 基础设施的每一层机会,就是把握下一个时代的财富密码。
第 1 层:能源层 —— 一切的物理边界
核心逻辑与本质
如果说 AI 是数字世界的蒸汽机,那么能源就是烧蒸汽机的煤。这一层的本质非常简单:AI 算力的物理边界,最终由电力和散热决定。
想象一下,一个拥有 10 万张 H100 的智算中心,一年的耗电量相当于一个中等城市。当芯片功耗从 A100 的 400W,到 B200 的 1200W,再到 2026 年 Rubin 架构的 2300W,传统的风冷技术已经彻底失效了。
这一层的核心逻辑是:算力密度提升 → 功耗指数级增长 → 传统散热技术失效 → 液冷成为刚需。
当前面临的瓶颈与挑战
-
功耗墙的极限挑战:英伟达路线图显示,芯片热设计功耗(TDP)每两年翻一番。2026 年 Rubin 架构单卡功耗将突破 2300W,传统风冷的散热极限大约在 500W 左右,早已望尘莫及。
-
PUE 红线的政策约束:国内双碳目标与 “东数西算” 政策持续加码,国家明确要求新建大型 / 超大型数据中心 PUE≤1.25,国家枢纽节点 PUE≤1.2。传统风冷数据中心 PUE 普遍在 1.4 以上,根本达不到要求。
-
水资源约束成为新变量:2026 年液冷渗透率突破 60%,但大规模液冷集群对水资源的消耗巨大,闭环水处理变得至关重要。
-
电力基础设施的瓶颈:单个智算集群的用电负荷动辄几十万千瓦,对电网的承载能力提出了严峻挑战。
关键技术节点与发展趋势
技术路线演进:
|
技术路线
|
散热效率
|
适用场景
|
2026 年渗透率
|
|
传统风冷
|
1x
|
低密算力
|
~20%
|
|
冷板式液冷
|
3-5x
|
中高密算力
|
~65%
|
|
浸没式液冷
|
8-10x
|
超高密算力
|
~15%
|
2026 年关键节点:
-
冷板式液冷成为 AI 服务器标配,渗透率超 50%
-
微通道水冷板(MLCP)技术成熟,散热能力突破 4000W
-
浸没式液冷开始规模化试点,单柜功耗突破 200kW
-
源网荷储一体化项目加速落地,智算中心变身虚拟电厂
具体的投资机会与标的方向
投资主线一:冷板式液冷核心部件(短期高弹性)
-
冷板:技术壁垒高,价值量占比约 30%
-
CDU(冷却液分配单元):算法优化替代欧美厂商
-
快接头:防泄漏精密连接器,切入 GB300 供应链
-
冷却液:特种绝缘冷却液,国产化替代空间大
投资主线二:浸没式液冷技术突破(长期潜力)
-
单相浸没式技术成熟度高,率先规模化
-
两相浸没式散热效率更高,适合超算场景
-
冷却液回收与处理技术
投资主线三:电力基础设施与节能设备
-
高端 UPS 与高压直流供电
-
智能配电与能源管理系统
-
虚拟电厂与源网荷储一体化
代表性企业分析
美股龙头:Vertiv(VRT)
-
全球液冷绝对龙头,市占率超 40%
-
2026 年液冷业务收入预计突破 80 亿美元,同比增长 120%
-
深度绑定英伟达、微软、亚马逊等核心客户
-
毛利率持续提升至 35% 以上,盈利能力强劲
A 股核心标的:英维克
-
国内液冷技术领军者,冷板 + CDU 全链条布局
-
适配英伟达 Rubin 架构的液冷方案已批量交付
-
2026Q1 液冷业务收入同比增长 215%,订单饱满
-
算法优化的 CDU 产品成功替代欧美厂商,性价比优势明显
其他重点关注:
-
高澜股份:浸没式液冷技术领先,订单持续增长
-
中科曙光:全液冷智算中心解决方案提供商
-
同飞股份:CDU 领域核心供应商,算法优化能力强
-
中航光电:快接头技术壁垒高,切入英伟达供应链
-
朗新科技:算力调度和虚拟电厂领域核心服务商
市场空间测算:
汇丰预计 2026 年全球数据中心电力和冷却设备的总可寻址市场规模将达到 1560 亿美元,较 2025 年的 930 亿美元同比增长约 67%。国内液冷市场规模突破 700 亿元,行业年增速超 70%。
汇丰预计 2026 年全球数据中心电力和冷却设备的总可寻址市场规模将达到 1560 亿美元,较 2025 年的 930 亿美元同比增长约 67%。国内液冷市场规模突破 700 亿元,行业年增速超 70%。
第 2 层:物理互联层 —— 让数据更快到达
核心逻辑与本质
这一层的本质是:解决数据移动的第一公里问题。
如果说算力是 AI 的发动机,那么互联就是 AI 的血管。当你有 10 万张 GPU 要协同工作时,数据在这些芯片之间移动的速度,直接决定了整个集群的实际算力利用率。这就是为什么全景图把 “光” 和 “电” 放在这一层 —— 它们是数据移动的载体。
这一层的核心洞察是:算力越强,对互联带宽的需求就越饥渴。当算力增长 10 倍时,互联带宽需要增长 100 倍才能匹配。
当前面临的瓶颈与挑战
-
铜缆的物理极限:传统电互联在 800G 速率下就遇到了功耗墙和距离限制,1.6T 以上基本不可行。
-
可插拔光模块的瓶颈:插入损耗大、功耗高,在 1.6T 速率上面临严峻挑战。
-
算力集群的通信墙:大规模 AI 训练集群中,通信时间占比高达 60%,GPU 实际利用率不到 40%。
-
成本压力:光模块在 AI 服务器 BOM 成本中占比已达 25%,且还在持续上升。
关键技术节点与发展趋势
技术路线演进:
|
技术路线
|
代表速率
|
插入损耗
|
系统光功率效率
|
2026 年状态
|
|
可插拔光模块
|
800G/1.6T
|
~22dB
|
1x
|
主流放量
|
|
CPO(共封装光学)
|
1.6T/3.2T
|
~4dB
|
提升 5 倍
|
规模化商用
|
|
OCS(光电路交换)
|
N/A
|
极低
|
提升 10 倍
|
爆发元年
|
2026 年关键节点:
-
CPO 量产元年:英伟达新旗舰算力平台全系搭载 CPO 方案,微软、亚马逊、阿里云等头部云厂商完成小批量试点
-
1.6T 光模块放量:全球 1.6T 光模块出货量突破 500 万只
-
3.2T CPO 原型机落地:进入客户测试环节
-
OCS 技术爆发:光电路交换开始大规模部署,大幅降低功耗
具体的投资机会与标的方向
投资主线一:CPO 产业链核心环节
-
核心光器件:激光芯片、硅光芯片、调制器
-
封装配套:先进封装技术与测试设备
-
材料与辅料:特种光纤、连接器、热管理材料
投资主线二:高端光模块持续放量
-
800G 光模块仍在快速上量,2026 年仍是主力
-
1.6T 光模块开始规模化交付
-
数通光模块需求持续超预期
投资主线三:光芯片国产化替代
-
25G/50G EML 芯片国产化突破
-
100G 以上高端光芯片技术攻关
-
硅光芯片技术路线崛起
代表性企业分析
全球格局:中国厂商绝对主导
目前全球光模块市场由中国厂商绝对主导,中际旭创、新易盛、天孚通信组成的 “易中天” 组合为产业核心支柱,2026 年纯 CPO 业务合计营收潜力超 300 亿元,全球市场份额占比超 30%。
目前全球光模块市场由中国厂商绝对主导,中际旭创、新易盛、天孚通信组成的 “易中天” 组合为产业核心支柱,2026 年纯 CPO 业务合计营收潜力超 300 亿元,全球市场份额占比超 30%。
中际旭创
-
全球光模块龙头,1.6T CPO 量产良率 90%+
-
3.2T CPO 已落地,技术领先全球
-
深度绑定英伟达、微软、Meta 等核心客户
-
2026 年光模块收入预计突破 200 亿元,CPO 业务贡献超 50 亿元
新易盛
-
海外市场拓展强劲,亚马逊、Meta 核心供应商
-
CPO 技术路线布局完善,客户验证进展顺利
-
毛利率持续提升,盈利能力行业领先
天孚通信
-
光器件平台型公司,CPO 核心器件核心供应商
-
产品覆盖光引擎全链条,价值量持续提升
-
技术壁垒高,客户粘性强
其他重点关注:
-
博创科技:硅光技术领先,CPO 布局早
-
光迅科技:光芯片国产化核心标的
-
中瓷电子:陶瓷封装核心供应商
市场空间测算:
高盛预计,2026 年、2027 年全球光模块市场规模将分别达到 510 亿美元、730 亿美元。2026 年全球 CPO 市场规模有望突破 80 亿美元,2027 年将达 400 亿美元量级。
高盛预计,2026 年、2027 年全球光模块市场规模将分别达到 510 亿美元、730 亿美元。2026 年全球 CPO 市场规模有望突破 80 亿美元,2027 年将达 400 亿美元量级。
第 3 层:计算载体(芯片层)—— 多元化计算架构
核心逻辑与本质
这一层的本质是:从 “通用计算” 到 “专用计算” 的范式转移。
过去,要跑 AI,首选英伟达的 GPU,这是默认选项。但现在,市场正在发生深刻的分化。AI 应用正从耗资巨大的训练阶段,转向大规模落地的推理阶段。推理场景对成本、功耗、延迟的敏感度,远远超过了对 “通用性” 的要求。
这一层的核心逻辑是:没有最好的芯片,只有最适合的芯片。不同的场景,需要不同的计算架构。
当前面临的瓶颈与挑战
-
通用 GPU 的性价比瓶颈:GPU 虽然编程灵活,但功耗大、成本高,在推理场景能效比不占优势。
-
定制化 ASIC 的生态壁垒:专用芯片虽然能效比高,但编程难度大、生态不完善,开发者门槛高。
-
先进制程的物理极限:3nm 以下制程成本飙升,良率下降,单纯靠制程提升性能的边际效益递减。
-
内存墙的制约:芯片算力再强,如果内存带宽跟不上,也是 “有劲使不出”。
关键技术节点与发展趋势
多元化计算架构三分天下:
|
架构类型
|
代表产品
|
核心优势
|
核心劣势
|
适用场景
|
2026 年市场份额
|
|
通用 GPU
|
NVIDIA H200/Rubin, AMD MI455X
|
编程灵活,生态完善
|
功耗大,成本高
|
训练 + 通用推理
|
~70%
|
|
定制 ASIC
|
Google TPU, AWS Trainium, Groq
|
能效比高,成本低
|
编程难,生态弱
|
大规模推理
|
~20%
|
|
潜在跃迁
|
存算一体,光计算,量子 – 经典混合
|
颠覆性潜力
|
成熟度低
|
特定场景
|
~10%
|
2026 年关键节点:
-
英伟达 Rubin 平台量产:Vera Rubin 平台下半年量产,整合六大关键组件,推理性能暴涨 5 倍
-
AMD 强势追赶:MI455X 基于 CDNA 5 架构,12 颗 Chiplet 混合设计,内存带宽优势明显
-
ASIC 爆发增长:ASIC 年复合增长率高达 65%,谷歌、亚马逊、Meta 等云厂商定制芯片快速放量
-
LPU 架构崛起:Groq 为代表的确定性数据流架构,推理速度达 GPU 十倍、能耗仅十分之一
具体的投资机会与标的方向
投资主线一:通用 GPU 生态链
-
英伟达供应链核心标的
-
AMD 供应链受益标的
-
GPU 服务器整机厂商
投资主线二:定制化 ASIC 芯片
-
云厂商定制芯片供应商
-
推理专用芯片设计公司
-
RISC-V 架构 AI 芯片
投资主线三:国产替代机会
-
国产 GPU 技术突破
-
信创市场 AI 芯片需求
-
产业链自主可控
代表性企业分析
英伟达(NVDA):算力帝国的守成与创新
-
高端训练芯片市占率约 70%,绝对垄断地位
-
2026 年 GTC 大会发布 Vera Rubin 平台,推出 Feynman 架构,主打推理场景
-
斥资 200 亿美元拿下 Groq LPU 架构授权,确立 “确定性数据流” 全新技术方向
-
Rubin 平台七款新芯片全面投产,市场需求直接引爆,推理 Token 成本暴降 10 倍
AMD(AMD):内存为王的赌注
-
AI 芯片市场份额升至 12%,快速追赶
-
即将推出的 MI455X 基于全新的 CDNA 5 架构,采用 12 颗 2nm 和 3nm 逻辑 Chiplet 的混合设计
-
通过先进的 3.5D 封装连接,总计 3200 亿晶体管
-
最大卖点是内存带宽和容量,目标直指英伟达的软肋
谷歌 / 亚马逊 / Meta:云厂商的垂直整合
-
谷歌 TPU v8 架构升级,CXL 内存池技术领先
-
亚马逊 Trainium/Inferentia 芯片迭代加速
-
Meta MTIA 芯片专为推荐系统优化,能效比是 GPU 的 3 倍
国产芯片代表:寒武纪、摩尔线程
-
寒武纪:国产 AI 芯片龙头,思元 590 性能对标国际一流
-
摩尔线程:适配国产大模型进展顺利,为整个赛道注入信心
市场格局:
2026 年数据中心 AI 芯片市场格局:NVIDIA \70%,AMD \12%,Intel \5%,定制 ASIC \10%,其他~3%。训练市场英伟达仍占绝对主导,推理市场多元化趋势明显。
2026 年数据中心 AI 芯片市场格局:NVIDIA \70%,AMD \12%,Intel \5%,定制 ASIC \10%,其他~3%。训练市场英伟达仍占绝对主导,推理市场多元化趋势明显。
第 4 层:内存层 —— 内存层级结构
核心逻辑与本质
这一层的本质是:解决 “内存墙” 问题,让数据离计算更近。
这是整个 AI 基础设施中最关键、也是最被低估的一层。你知道吗?现在的 AI 芯片,90% 的时间都在 “等数据”,而不是 “算数据”。一颗价值 3 万美元的 H100,真正用于计算的时间可能不到 10%,剩下的时间都在 idle—— 因为内存喂不饱它。
这一层的核心逻辑是:成本 /token → 延迟 → 功耗。内存的层级结构,直接决定了 AI 的经济模型。
当前面临的瓶颈与挑战
-
HBM 产能严重不足:HBM3 价格从 2025 年 Q2 低点约 180\220 美元涨到 2026 年 Q2 现货价约 700\850 美元,涨幅 3 倍。
-
内存容量与带宽的矛盾:模型越来越大,需要的内存容量越来越大,但 HBM 容量扩展困难且成本极高。
-
内存资源碎片化:传统架构下内存被单个芯片 “锁死”,无法自由调配,资源浪费严重。
-
功耗问题:数据在内存之间移动的功耗,远远超过计算本身的功耗。
关键技术节点与发展趋势
内存层级结构演进:
|
内存层级
|
代表技术
|
容量
|
带宽
|
延迟
|
成本
|
2026 年定位
|
|
片上缓存
|
SRAM
|
MB 级
|
最高
|
最低
|
最高
|
计算核心
|
|
近存内存
|
HBM3/HBM4
|
几十 GB
|
~1.2TB/s
|
~100ns
|
高
|
热数据处理
|
|
池化内存
|
CXL DDR5
|
几百 GB~ 几 TB
|
~100GB/s
|
~200ns
|
中
|
温数据处理
|
|
远端存储
|
SSD/HDD
|
几 TB~PB 级
|
~10GB/s
|
~ms 级
|
低
|
冷数据存储
|
2026 年关键节点:
-
HBM4 量产元年:新一代 HBM4 开始量产,带宽再提升 50%
-
CXL 3.0 落地元年:CXL 内存池化技术商业化,作为 HBM 的 “二级缓存”,成为运行多模态模型的标配
-
内存分级存储普及:Mooncake、Dynamo、UCM 等工业级方案通过以存换算、分级存储、分布式内存池等技术实现优化
具体的投资机会与标的方向
投资主线一:HBM 全产业链
-
HBM 内存接口芯片
-
HBM 前驱体材料
-
HBM 测试与封装设备
-
HBM 代理与分销
投资主线二:CXL 内存池化
-
CXL 内存扩展控制器(MXC)
-
PCIe/CXL Retimer 芯片
-
CXL 模组配套芯片(SPD/VPD)
-
CXL 交换机与管理软件
投资主线三:内存系统优化
-
内存调度与管理软件
-
KV Cache 优化技术
-
内存池化解决方案
代表性企业分析
澜起科技:全球 CXL 绝对龙头
-
全球唯一同时掌握 CXL 内存扩展控制器(MXC)、PCIe/CXL Retimer 芯片、DDR5 内存接口芯片三大核心技术
-
参与行业标准制定,通过 CXL 联盟认证
-
谷歌 TPU v8 内存池核心供货方,已送样测试
-
从单一接口芯片,拓展到系统级互联方案,价值量与行业地位迎来估值重构
三星 / 海力士 / 美光:HBM 三巨头
-
SK 海力士 HBM 市占率超 50%,技术领先
-
三星 HBM 产能快速扩张,2026 年市占率有望提升至 35%
-
美光 HBM4 技术路线激进,目标 2027 年量产
A 股核心标的:
-
香农芯创:HBM 代理商,同时布局内存接口芯片,AI 存储核心受益
-
雅克科技:HBM 前驱体材料供应商,旗下 UP Chemical 是 SK 海力士前驱体材料核心供应商
-
聚辰股份:DDR5 SPD 芯片全球市占领先,CXL 模组必备 SPD/VPD 芯片
市场空间测算:
CXL 内存设备市场预计将从 2025 年的 16.9 亿美元增长至 2028 年的 150 亿美元,其中 CXL 后端 DRAM 将超过 120 亿美元。2025 年 CXL 相关芯片市场规模已达 30 亿美元,年复合增长率超 80%。
CXL 内存设备市场预计将从 2025 年的 16.9 亿美元增长至 2028 年的 150 亿美元,其中 CXL 后端 DRAM 将超过 120 亿美元。2025 年 CXL 相关芯片市场规模已达 30 亿美元,年复合增长率超 80%。
第 5 层:封装层 —— 先进封装与 Chiplet 技术
核心逻辑与本质
这一层的本质是:用封装创新,突破摩尔定律的物理极限。
当制程从 7nm 到 5nm 到 3nm,每前进一步的成本都在指数级上升,而性能提升的边际效益却在递减。这时候,人们发现:与其在一颗芯片上死磕制程,不如把多颗芯片 “打包” 在一起,用封装技术来提升整体性能。
这就是 Chiplet 的核心思想 ——”化整为零,聚沙成塔”。而封装技术,就是把这些沙子粘合成塔的胶水。
这一层的核心逻辑是:封装不再是芯片制造的 “最后一公里”,而是算力提升的 “第一生产力”。
当前面临的瓶颈与挑战
-
产能严重不足:台积电 CoWoS 产能被英伟达独占超 60%,其他厂商一 “封” 难求。
-
技术壁垒极高:混合键合、3D 堆叠等先进封装技术门槛极高,国内厂商差距明显。
-
成本压力:先进封装的成本已经接近甚至超过芯片本身的制造成本。
-
标准不统一:Chiplet 互联标准尚未完全统一,不同厂商产品兼容性差。
关键技术节点与发展趋势
先进封装技术路线:
|
封装技术
|
代表厂商
|
互联密度
|
主要应用
|
2026 年状态
|
|
CoWoS
|
台积电
|
中高
|
AI GPU/ASIC
|
绝对主流
|
|
CoWoS-L
|
台积电
|
高
|
超大规模 AI 芯片
|
快速上量
|
|
CoPoS
|
台积电
|
中
|
成本优化方案
|
成本降 20%,产能翻倍
|
|
混合键合
|
台积电 / 三星
|
极高
|
3D 堆叠
|
逐步普及
|
|
玻璃基板
|
英特尔 / 台积电
|
极高
|
下一代封装
|
技术验证
|
2026 年关键节点:
-
台积电 CoWoS 总产能在年初基础上再扩产 150%,相较 2025 年底提升超过 3 倍
-
2026 年底 CoWoS 产能预计达 12.5 万片 / 月,其中 40% CoWoS-L 产能分配给英伟达 Rubin 芯片
-
高端 AI 芯片 Chiplet 渗透率超 60%
-
混合键合技术成为标配
具体的投资机会与标的方向
投资主线一:封测代工环节
-
国内先进封装龙头
-
绑定 AI 大厂的封测企业
-
特色封装技术厂商
投资主线二:封装设备环节
-
键合设备
-
光刻设备
-
测试设备
-
清洗设备
投资主线三:封装材料环节
-
临时键合材料
-
封装基板
-
底部填充胶
-
导电胶
代表性企业分析
台积电:全球先进封装绝对霸主
-
先进封装市占率超 60%,CoWoS 市占率超 85%,3D 封装市占率超 60%,AI 芯片封装市占率超 85%
-
2026 年 4 月公布 CoPoS 技术,成本降 20%,产能翻倍,锁定高端市场
-
英伟达已预订 2026 年 80-85 万片晶圆产能,占据超 50% 份额
-
CoWoS 等先进封装平台的产品单价与盈利能力与 7nm 先进制程趋近,单位产能市值可比肩 7nm 制程
长电科技:国内封测龙头
-
国内封测技术最全面的厂商
-
2.5D/3D 封装技术量产放量
-
深度绑定国内 AI 芯片厂商
-
2026 年先进封装收入占比有望突破 40%
通富微电:AMD 核心供应商
-
AMD 最大的封测合作伙伴
-
Chiplet 技术领先,已大规模量产
-
受益于 AMD AI 芯片出货量快速增长
-
2026Q1 业绩超预期,盈利能力持续提升
设备与材料标的:
-
中微公司:刻蚀设备龙头,先进封装核心设备供应商
-
盛美上海:清洗设备领先,先进封装受益明显
-
拓荆科技:薄膜沉积设备核心厂商
-
飞凯材料:国内仅有的两家进入台积电 CoWoS 供应链的临时键合材料供应商
-
兴森科技:国内唯一能量产高端封装基板的厂商
市场数据:
2029 年先进封装市场规模达 5500 亿美元,复合增速超 60%。封装环节从产业链配套配角升级为价值核心。
2029 年先进封装市场规模达 5500 亿美元,复合增速超 60%。封装环节从产业链配套配角升级为价值核心。
第 6 层:存储与数据层 —— 数据流水线与存储系统
核心逻辑与本质
这一层的本质是:让数据像流水线一样,源源不断地喂给 GPU。
传统的存储系统是为 CPU 设计的,讲究 “数据保护” 和 “随机访问”。但 AI 时代的存储系统,核心目标完全变了 ——要让 GPU 持续获得高质量数据流,避免高成本空转。
一个价值 3 万美元的 GPU,如果因为数据跟不上而空转 1 秒钟,那就是实实在在的浪费。这就是为什么全景图说这一层的本质是 “数据供给能力”。
这一层的核心逻辑是:数据中心正在向 “Token 工厂” 演进,存储的目标从 “保存数据” 转向 “生产 Token”。
当前面临的瓶颈与挑战
-
GPU 饥饿问题:传统以 CPU 为中心的架构已难以适配 GPU 密集型 AI 负载,GPU 等待时间长、空转率高,导致整体效率低下。
-
数据洪流挑战:AI 训练需要海量数据,数据量呈指数级增长,存储容量和带宽压力巨大。
-
数据质量问题:无效或冗余数据加剧空间占用与成本压力,数据价值密度尚难评估。
-
软件栈重构:存储软件栈亟需重构与精简,企业级存储目标已从数据保护转向提升数据供给效率。
关键技术节点与发展趋势
AI 存储架构演进:
|
存储层级
|
介质类型
|
性能指标
|
数据类型
|
2026 年定位
|
|
瞬时热数据
|
HBM
|
TB/s 级带宽
|
正在计算的数据
|
计算核心
|
|
活跃温数据
|
SSD/HBF
|
GB/s 级带宽
|
即将计算的数据
|
数据流水线
|
|
海量冷数据
|
HAMR 硬盘
|
百 MB/s 级
|
待挖掘的数据
|
数据湖
|
2026 年关键节点:
-
存算分离架构普及:计算与存储资源解耦,弹性伸缩,资源利用率提升 30%+
-
数据流水线自动化:从原始存储到 AI 应用的自动化数据转换,数据新鲜度问题得到解决
-
智能分层存储:基于策略实现自动化的数据分层和迁移,在性能、成本与效率之间取得平衡
-
存算一体技术突破:清华大学、华为与字节跳动联合研发的存算芯片,已在推荐系统场景中将能效提升 181 倍
具体的投资机会与标的方向
投资主线一:AI 原生存储系统
-
高性能全闪存阵列
-
并行文件系统
-
存算分离架构解决方案
投资主线二:数据流水线与管理
-
数据同步与转换引擎
-
数据质量与治理工具
-
AI 数据供应链平台
投资主线三:存储介质创新
-
高速 SSD 控制器
-
SCM 存储级内存
-
HAMR 热辅助磁记录
代表性企业分析
Pure Storage:AI 存储领军者
-
专为 AI 设计的全闪存存储架构
-
FlashBlade//S 产品深度优化 AI 工作负载
-
与英伟达生态深度整合,DGX SuperPOD 认证存储
-
2026 财年 AI 相关收入同比增长 150%+
Snowflake:数据云平台龙头
-
数据仓库与 AI 训练深度整合
-
原生支持大模型训练数据准备
-
数据共享与协作生态完善
-
企业级客户付费意愿强,ARR 持续高增长
Dell Technologies:企业级存储巨头
-
2026 年下半年正式发布 Exascale 存储架构
-
专为超大规模 AI 与高性能计算(HPC)设计的软件驱动存储架构
-
DataLoop 引擎负责连接数据流水线、AI 模型与人工
NetApp:数据供应链革新者
-
NetApp AI Data Engine(AIDE)被定义为 “AI 数据供应链” 中的智能层
-
由四个相互关联的引擎组成,实现从原始存储到 AI 应用的自动化数据转换
-
DataSync(数据同步引擎)解决 AI 工作负载中数据新鲜度的问题
国内厂商:
-
浪潮数据:提出融合存储技术战略,通过介质融合、协议融合、管理融合、应用融合四大核心方向
-
华为存储:OceanStor 系列在 AI 场景应用广泛,存算一体技术领先
行业洞察:
AI 推理日均调用量突破 140 万亿次,存储行业正在经历需求重构。一个清晰的分层存储体系正在形成:HBM 处理瞬时热数据,SSD 和 HBF 承载活跃温数据,HAMR 硬盘归档海量冷数据。
AI 推理日均调用量突破 140 万亿次,存储行业正在经历需求重构。一个清晰的分层存储体系正在形成:HBM 处理瞬时热数据,SSD 和 HBF 承载活跃温数据,HAMR 硬盘归档海量冷数据。
第 7 层:系统软件层 —— 调度优化与系统软件
核心逻辑与本质
这一层的本质是:用软件的智慧,释放硬件的潜力。
你买了 100 张 GPU,不代表你就能获得 100 倍的算力。实际上,大多数 AI 集群的 GPU 利用率不到 40%,有的甚至不到 20%。剩下的算力去哪了?都浪费在调度不合理、通信等待、资源竞争上了。
系统软件层,就是那个让 100 张 GPU 真正发挥出 100 倍算力的 “魔术师”。
这一层的核心逻辑是:硬件决定了算力的上限,软件决定了能达到这个上限的百分之几。
当前面临的瓶颈与挑战
-
GPU 利用率低下:数据中心 GPU 利用率普遍低于 50%,调度效率提升空间巨大。
-
通信开销巨大:大规模分布式训练中,通信时间占比高达 60% 以上。
-
内存资源浪费:内存碎片化、分配不合理导致宝贵的 HBM 资源浪费。
-
编译器优化不足:不同硬件平台的编译器优化程度差异大,性能差距可达数倍。
关键技术节点与发展趋势
系统软件优化方向:
|
优化方向
|
核心技术
|
预期效果
|
2026 年进展
|
|
编译器优化
|
vLLM, TensorRT, FlashAttention
|
推理吞吐量提升 2-5 倍
|
工业级方案成熟
|
|
调度优化
|
K8s AI 扩展,智能任务调度
|
资源利用率提升 30%+
|
规模化部署
|
|
通信优化
|
集合通信算法,拓扑感知
|
通信时间减少 50%
|
主流框架集成
|
|
内存优化
|
KV Cache, 内存池化,虚拟化
|
有效容量提升 2-3 倍
|
快速普及
|
2026 年关键节点:
-
推理优化编译器成熟:vLLM、TensorRT 等工业级方案广泛应用
-
智能调度普及:Kubernetes 结合 AI 预测算法,根据业务周期自动调整资源,既保证 SLA 又节省 30% 以上的云成本
-
CPU 重要性提升:AI 从训练走向推理 / Agent,GPU 负责矩阵计算,CPU 负责调度、编排、检索、多轮调用、工具链编排,高端服务器 CPU 供给弹性有限
-
Kernel 自动化优化:AI 编译器自动生成高性能算子代码,已应用于生产级推理引擎
具体的投资机会与标的方向
投资主线一:AI 编译器与推理优化
-
开源推理框架商业化
-
硬件厂商编译器工具链
-
算子自动优化技术
投资主线二:集群调度与管理
-
AI 集群调度软件
-
智能运维与监控
-
成本优化与资源管理
投资主线三:英伟达生态护城河
-
CUDA 生态核心参与者
-
英伟达认证软件合作伙伴
-
企业级 AI 软件平台
代表性企业分析
英伟达:生态护城河的构建者
-
CUDA 生态绝对垄断,开发者数量超 600 万
-
编译器持续优化,每一代硬件性能通过软件提升 30%+
-
企业级软件收入快速增长,2026 年有望突破 100 亿美元
-
AI Enterprise 软件平台,企业级客户付费意愿强
vLLM 团队:推理优化新贵
-
PagedAttention 技术革命性提升推理吞吐量
-
开源社区活跃度极高,GitHub 星标超 5 万
-
商业化进程加速,企业级客户快速增长
-
已成为大模型推理部署的事实标准
Docker AI Toolkit:Dev 到 MLOps 全链路提速
-
2026 年引入全新设计的 RealTime Inference Cache Engine(RICE)
-
专为高频低延迟 ML 推理场景优化
-
在模型加载、预处理输入哈希、响应复用三个关键路径上实现零拷贝内存共享
-
全链路提速 4.8 倍,成为 AI 部署的标配工具
国内厂商:
-
深势科技:AI for Science 领域系统软件领先
-
一流科技:OneFlow 深度学习框架,分布式训练优化
-
第四范式:企业级 AI 平台,调度优化技术领先
行业数据:
英特尔 2026Q1 数据中心 AI 业务收入同比 + 22%。AI GPU 吃紧先进制程、封装、HBM 等关键资源,服务器 CPU 也依赖高端代工与封测能力,供给慢、需求急,价格有上行动力。
英特尔 2026Q1 数据中心 AI 业务收入同比 + 22%。AI GPU 吃紧先进制程、封装、HBM 等关键资源,服务器 CPU 也依赖高端代工与封测能力,供给慢、需求急,价格有上行动力。
第 8 层:框架与模型层 —— 模型驱动与框架生态
核心逻辑与本质
这一层的本质是:从 “堆参数” 到 “拼效率” 的范式转移。
2023 年的时候,大家还在比谁的模型参数大,万亿参数、十万亿参数… 好像参数越大就越厉害。但到了 2026 年,行业彻底告别了 “参数越大性能越强” 的认知。
现在的核心问题不是 “模型能做什么”,而是 “做这件事要花多少钱”。当 AI 应用大规模落地时,推理成本是决定商业模式能否成立的最关键因素。
这一层的核心逻辑是:模型架构创新,是降低 AI 成本的最有效手段。
当前面临的瓶颈与挑战
-
推理成本居高不下:大模型推理成本仍然是商业化的最大障碍,Token 成本需要再降一个数量级。
-
模型能力同质化:基础模型能力趋同,差异化竞争难度加大。
-
上下文窗口限制:虽然已扩展到千万级 Token,但长上下文处理效率仍然低下。
-
多模态融合困难:文本、图像、音频、视频的深度融合仍有技术瓶颈。
关键技术节点与发展趋势
模型架构演进:
|
架构类型
|
代表模型
|
核心优势
|
2026 年状态
|
|
稠密模型
|
GPT-4, Claude 3
|
实现简单,性能稳定
|
逐步退居二线
|
|
MoE 稀疏模型
|
GPT-4o, Gemini 3.0, 混元 Hy3
|
成本低,扩展性好
|
绝对主流
|
|
神经符号融合
|
下一代架构
|
推理能力强,可解释
|
技术验证
|
2026 年关键节点:
-
MoE 架构成为主流:腾讯混元 Hy3、DeepSeek V4、阿里通义千问等新模型全部采用 MoE 架构
-
上下文窗口突破:谷歌 Gemini 3.0 Ultra 支持 2000 万 Token 千万级上下文窗口
-
多模态能力跃升:能直接处理 2 小时长视频并生成结构化摘要,可将手绘草图转化为可运行的前端代码,还原度达 92% 以上
-
推理时 Scaling Law 兴起:正在重塑 AI 的一切,过程奖励模型(PRM)成为新的基础设施赛道
具体的投资机会与标的方向
投资主线一:头部大模型公司
-
拥有海量用户和数据的模型厂商
-
模型 + 应用一体化闭环公司
-
垂直领域专业大模型
投资主线二:开源模型生态
-
开源模型商业化公司
-
模型蒸馏与量化技术
-
端侧模型部署方案
投资主线三:模型开发工具链
-
MLOps 平台
-
模型评估与测试
-
微调与对齐工具
代表性企业分析
OpenAI:模型能力的天花板
-
GPT-4o 多模态能力全球领先
-
MoE 架构优化,推理成本持续下降
-
插件生态与 Agent 能力领先
-
企业级客户 ARPU 值持续提升
谷歌:技术路线的探索者
-
Gemini 3.0 Ultra 多模态评分位居全球第一
-
TPU+MoE + 定制硬件的垂直整合路线
-
2000 万 Token 上下文窗口技术突破
-
安卓 + 搜索的生态优势明显
腾讯混元:国产模型的追赶者
-
混元 Hy3 preview 采用稀疏混合专家(MoE)架构,总参数规模约 295B
-
在推理、代码与智能体能力等维度较上一代有所提升
-
已接入腾讯云及多条核心产品线
-
姚顺雨掌舵后技术路线更加务实
DeepSeek:成本优化的标杆
-
DeepSeek-V4 开创了 “芯模联动” 的新范式
-
推理成本大幅下降,有望打开人工智能规模化应用空间
-
MoE 大集群成为布局重点,跨节点 EP、PD+EP 的产业热度不断提升
-
开源社区影响力持续扩大
其他重点关注:
-
MiniMax:通用人工智能路线,多模态能力突出
-
智谱 AI:认知大模型,知识图谱融合
-
字节跳动:推荐系统 + 大模型结合,应用场景丰富
市场洞察:
2026 年成为模型推理侧需求的爆发元年。随着模型能力的成熟和差异化应用市场的打开,算力需求将从昂贵的 “模型训练” 转向高频的 “模型调用”。能够提供高效推理算力和拥有爆款应用的厂商,将成为新一轮增长的领头羊。
2026 年成为模型推理侧需求的爆发元年。随着模型能力的成熟和差异化应用市场的打开,算力需求将从昂贵的 “模型训练” 转向高频的 “模型调用”。能够提供高效推理算力和拥有爆款应用的厂商,将成为新一轮增长的领头羊。
第 9 层:应用层 ——AI 驱动的行业变革
核心逻辑与本质
这一层的本质是:从 “钱从哪里来” 到 “钱到哪里去” 的最终闭环。
前面 8 层讲的都是 “花钱” 的事 —— 买芯片、建机房、做软件、训模型。但到了这一层,终于要讲 “赚钱” 的事了。
AI 的终极价值,不在于训练出多么强大的模型,而在于用这些模型去解决真实世界的问题,创造实实在在的商业价值。这就是为什么全景图说这一层的本质是 “需求来源(钱从哪里来)”。
这一层的核心逻辑是:需求决定供给,应用反推架构。最终的商业价值,只能在这一层实现。
当前面临的瓶颈与挑战
-
ROI 验证困难:很多 AI 应用的投入产出比还不清晰,企业付费谨慎。
-
人才缺口巨大:既懂 AI 又懂行业的复合型人才严重不足。
-
数据安全与合规:企业数据上云的安全顾虑,数据隐私保护要求。
-
集成复杂度高:AI 系统与现有 IT 系统集成难度大,落地周期长。
关键技术节点与发展趋势
AI 应用演进路径:
|
应用类型
|
代表形态
|
成熟度
|
2026 年市场规模
|
|
AI Agent
|
数字员工,智能助理
|
爆发元年
|
~500 亿美元
|
|
自动化工作流
|
RPA+AI, 流程自动化
|
快速增长
|
~300 亿美元
|
|
企业 AI
|
Copilot, 知识库
|
规模化落地
|
~800 亿美元
|
|
消费级应用
|
C 端产品,内容生成
|
流量爆发
|
~600 亿美元
|
2026 年关键节点:
-
AI Agent 元年:2026 年被称为 “AI Agent(智能体)元年”,从 “被动响应的工具” 变成 “主动执行的全能管家”
-
企业 AI 规模化落地:企业级 AI 采购预算同比增长 80%+
-
C 端流量爆发:豆包 DAU 已突破 1 亿,千问 APP 公测 23 天月活超 3000 万
-
多模态内容生成:AI 短剧、漫剧工业化生产,内容变现能力爆发
具体的投资机会与标的方向
投资主线一:AI Agent 平台与应用
-
通用 Agent 平台
-
垂直行业 Agent
-
Agent 开发工具链
投资主线二:企业级 AI 应用
-
办公 AI Copilot
-
智能客服与营销
-
工业 AI 与智能制造
投资主线三:消费级 AI 产品
-
AI 内容创作平台
-
个人智能助理
-
AI + 教育 / 健康 / 娱乐
代表性企业分析
办公 AI Agent 龙头:金山办公
-
WPS AI 深度融合办公场景,文档生成 + 数据处理 + 智能协作
-
付费用户快速增长,2026Q1AI 相关收入同比增长 300%+
-
个人 + 企业全覆盖,用户粘性极强
-
国内办公软件绝对龙头,AI 转型最成功的 SaaS 公司
政务金融智能体标杆:拓尔思
-
自研拓天大模型,推出 TTAgentFlow 智能体平台
-
已落地超 40 个高价值项目,单项目最高金额达 2000 万元
-
政务 + 金融垂直领域 know-how 深厚
-
数据安全与合规能力突出,大客户付费意愿强
中文内容大模型龙头:中文在线
-
“中文逍遥” 大模型 + AI 创作智能体
-
赋能 IP、短剧、漫剧工业化生产
-
内容变现能力爆发,2026Q1 收入同比增长 150%+
-
IP 资源 + AI 技术 + 变现渠道全链条打通
安全领域智能体:三六零
-
360 智脑智能体,聚焦安全领域
-
推出企业级安全智能体,2026 年 1 月订单超 2 亿元
-
安全场景 + AI 技术深度结合
-
政企客户资源丰富
其他重点关注:
-
容联云:AI 客服 Agent,替代人工客服,降本 50%+
-
智齿科技:智能对话 Agent,金融 + 电商场景落地
-
同花顺:iFinD 智能投研,金融科技领域 AI 应用领先
-
恺英网络:AI+IP 游戏,内容生产效率革命
-
网易有道:Lobster AI,中国版 OpenClaw,个人智能助理
市场数据:
巴克莱资本预测,到 2026 年,消费者 AI 的日活跃用户将突破 10 亿。个人智能助理将成为主要增长点,覆盖健康管理、个性化教育、智能出行等场景,扮演用户 “数字分身” 的角色,自主处理各类生活事务。
巴克莱资本预测,到 2026 年,消费者 AI 的日活跃用户将突破 10 亿。个人智能助理将成为主要增长点,覆盖健康管理、个性化教育、智能出行等场景,扮演用户 “数字分身” 的角色,自主处理各类生活事务。
三大最终洞察:重新理解 AI 的本质
现在,我们已经攀登完了 AI 基础设施的 9 个层级。站在这个高度,让我们再来回顾全景图中的 “三大最终洞察”,你会有完全不同的理解。
洞察一:AI 不是算力问题,是系统工程问题
这是全景图最核心的观点,也是绝大多数人最容易犯的错误。
当你只盯着英伟达的 GPU 销量时,你看到的只是冰山一角。真正决定 AI 系统性能的,是从能源、互联、芯片、内存、封装、存储、软件、框架到应用的整个系统。任何一个环节的瓶颈,都会让整个系统的性能大打折扣。
这就像木桶效应 —— 最短的那块板,决定了木桶能装多少水。而现在,这个木桶的 9 块板,没有一块是足够长的。
投资启示:不要只盯着最耀眼的那一层,真正的超额收益,往往来自解决那些被忽视但又真实存在的系统瓶颈。
洞察二:所有瓶颈都在 “数据移动”
这是整个 AI 产业最底层的物理规律。
计算本身的功耗和成本,其实一直在快速下降。但数据在不同组件之间移动的功耗,却下降得非常慢。现在,数据移动的功耗已经占到整个 AI 系统功耗的 70% 以上,而计算本身的功耗还不到 30%。
这就是为什么我们看到:
-
光模块的需求增长比芯片还快
-
HBM 内存的价格涨了 3 倍还供不应求
-
CXL 内存池化技术突然变成了热点
-
先进封装的重要性甚至超过了制程
所有这些技术,本质上都是在解决同一个问题 ——如何让数据移动得更快、更省、更远。
投资启示:沿着 “数据移动” 的路径去找投资机会,你会发现一个又一个确定性极强的赛道。
洞察三:成本 /token → 每一层机会,功耗↓
这是 AI 的经济模型最本质的表达。
每一个 Token 的生成成本,决定了 AI 应用的商业边界。当 Token 成本是 1 美元的时候,AI 只能是实验室里的玩具;当 Token 成本降到 1 美分的时候,AI 可以服务高端客户;当 Token 成本降到 0.01 美分的时候,AI 就能走进千家万户。
而降低 Token 成本的机会,存在于 AI 基础设施的每一个层级:
-
能源层:降低每度电的成本
-
互联层:降低每比特数据移动的成本
-
芯片层:降低每一次计算的成本
-
内存层:降低每字节数据访问的成本
-
封装层:降低每毫米互联的成本
-
… 以此类推
投资启示:任何能够系统性降低 Token 成本的技术,都是值得重仓的方向。
投资框架:三问选股法
面对如此复杂的 AI 基础设施产业链,如何筛选真正有价值的投资标的?全景图给了我们一个简单但极其有效的框架 ——”三问选股法”。
第一问:这个瓶颈是不是真的?
这是最基础也是最重要的问题。
很多所谓的 “痛点”,其实是伪需求。比如前两年炒得火热的 “存算一体”,很多公司讲的故事很动听,但实际上在通用 AI 场景下,存算一体的优势并不明显,这就是伪瓶颈。
那什么是真瓶颈?
-
液冷:芯片功耗 2300W,风冷确实散不了热 —— 这是真的
-
HBM:GPU 利用率不到 40%,确实是内存喂不饱 —— 这是真的
-
CPO:1.6T 以上电互联确实走不通 —— 这是真的
-
CoWoS:台积电产能确实被抢光了 —— 这是真的
判断标准:有没有头部客户愿意为这个解决方案付溢价,并且真金白银地下订单。
第二问:这个瓶颈是不是结构性的?
真瓶颈也分两种:临时性的和结构性的。
临时性的瓶颈,比如某款芯片的产能不足,扩产几个季度就解决了,这种机会的持续性就很差。
结构性的瓶颈,是那种由物理规律或者产业格局决定的,短期之内根本解决不了的问题。比如:
-
先进封装的产能建设周期是 18-24 个月
-
HBM 的产能扩张需要新的晶圆厂,周期是 2-3 年
-
光芯片的技术积累需要 5-10 年
-
CUDA 生态的壁垒是几百万开发者的网络效应
判断标准:这个瓶颈的解决周期是不是超过 18 个月?如果是,那就是结构性的。
第三问:这个瓶颈有没有最佳解法?
即使是真的、结构性的瓶颈,也可能有多种解决方案。我们要找的,是那个已经成为行业共识的 “最佳解法”。
比如散热的最佳解法是液冷,不是什么其他黑科技;
比如高速互联的最佳解法是 CPO,不是什么其他新协议;
比如内存扩展的最佳解法是 CXL,不是什么其他私有标准;
比如先进封装的最佳解法是 CoWoS,不是什么其他封装技术。
比如高速互联的最佳解法是 CPO,不是什么其他新协议;
比如内存扩展的最佳解法是 CXL,不是什么其他私有标准;
比如先进封装的最佳解法是 CoWoS,不是什么其他封装技术。
最佳解法意味着:
-
英伟达 / 微软 / 亚马逊等头部客户已经选择了这个路线
-
行业标准已经基本统一
-
供应链已经开始规模化备货
判断标准:英伟达的路线图上有没有这个技术?如果有,那大概率就是最佳解法。
总结:2026 年 AI 投资的行动指南
站在 2026 年这个时间点,我们正处在 AI 基础设施建设的黄金窗口期。基于全景图的分析,我给大家总结出以下投资建议:
一、优先级排序:从下往上,越底层越确定
第一梯队(确定性最高):
-
能源与散热:液冷是 2026 年最确定的赛道,没有之一
-
高速互联:光模块 + CPO,需求持续超预期
-
先进封装:CoWoS 产能缺口至少持续到 2027 年底
第二梯队(高成长性):
-
HBM 与 CXL:内存墙问题的解决方案,价值量持续提升
-
AI 存储:数据流水线重构,存储向 Token 工厂演进
-
系统软件:GPU 利用率提升空间巨大,软件定义算力
第三梯队(弹性最大):
-
AI 芯片:多元化架构趋势,ASIC 和国产替代有机会
-
大模型:头部效应明显,关注成本优化能力
-
AI 应用:Agent 元年,关注有场景壁垒的垂直应用
二、时间节奏:2026 年是硬件大年,2027 年是应用大年
-
2026 年 H1:液冷、光模块、先进封装产能紧张,业绩超预期是主旋律
-
2026 年 H2:Rubin 平台量产,CPO 规模化商用,CXL 落地
-
2027 年:AI Agent 大规模落地,应用层业绩开始兑现
三、风险提示:需要警惕的几个坑
-
不要追逐概念:凡是英伟达路线图上没有的 “黑科技”,大概率是割韭菜
-
不要忽视估值:再好的赛道,估值贵了也不是好投资
-
不要线性外推:AI 技术迭代极快,今天的龙头明天可能就被颠覆
-
不要忽视地缘政治风险:半导体产业链的全球化正在逆转
四、最后的话
AI 基础设施的建设,就像当年修建铁路一样。
150 年前,没有人知道铁路最终会用来运什么,但大家都知道铁路一定会改变世界。于是,那些投资修建铁路、生产钢轨、制造火车头的人,都获得了巨大的财富。
今天也是一样。我们可能还不知道 AI 的杀手级应用是什么,但我们确切地知道,支撑 AI 运行的这 9 层基础设施,一定会被海量的需求填满。
把握 AI 基础设施的每一层机会,就是把握下一个时代的财富密码。
愿我们都能在这场百年一遇的技术革命中,找到属于自己的位置。
(全文完)
本文字数:约 15,000 字