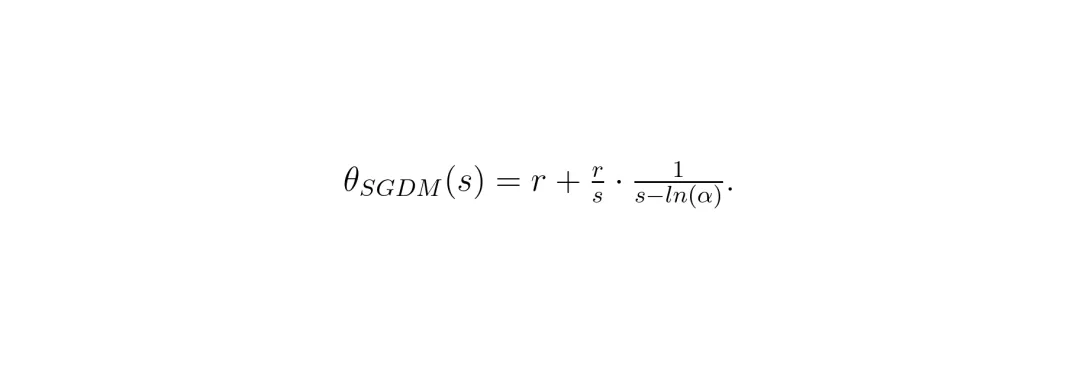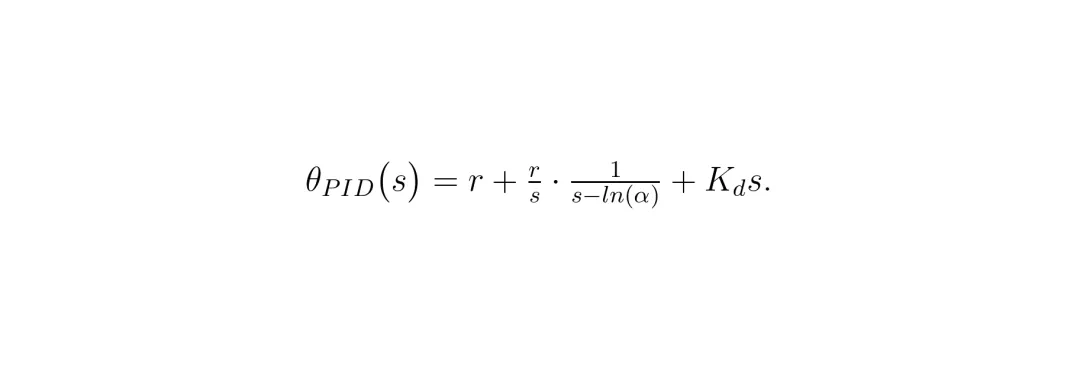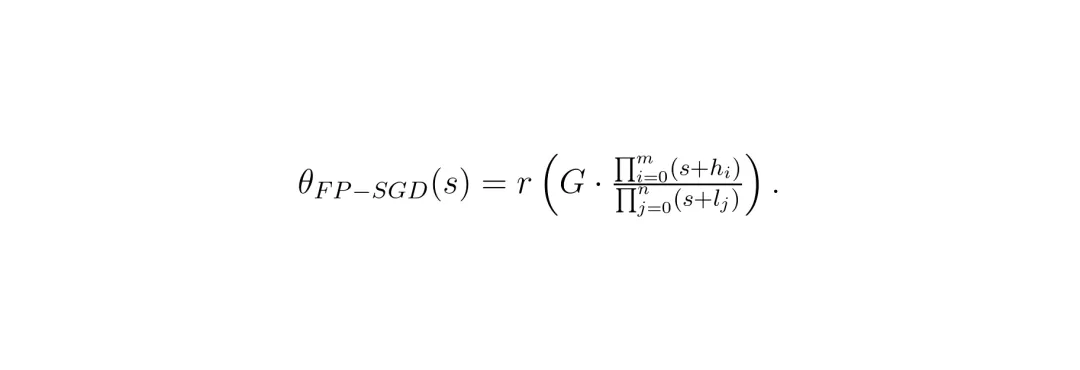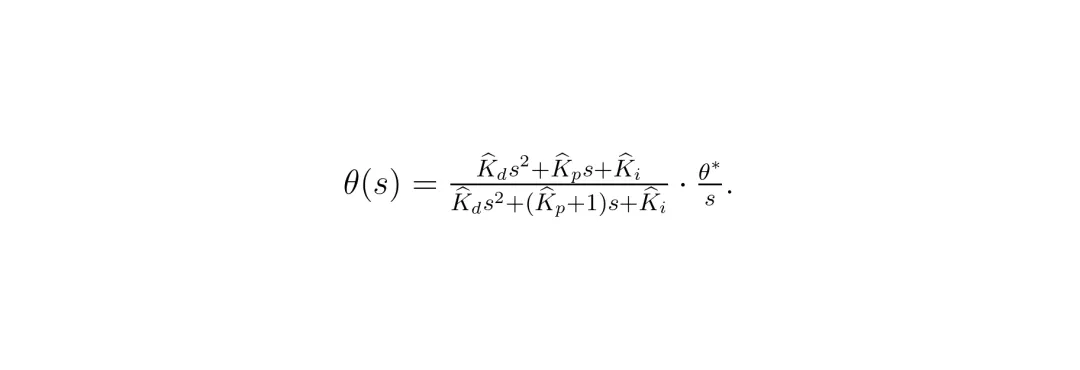AI大模型天天胡编乱造?用“拉普拉斯变换”治它!
🐉 今天聊个硬的! AI生成内容老是胡编乱造?深层原因终于被扒出来了! 用控制论的“拉普拉斯变换”一分析, 才发现原来是优化器没选对! 👇扫码加入「龙哥读论文」知识星球,一起用上帝视角看透AI本质~
龙哥推荐理由:
原论文信息如下:
论文标题:
发表日期:
发表单位:
原文链接:
图10:DDPM在不同优化器下的生成样本(从上到下依次为SGD、SGDM、Adam、PID、LPF-SGD、HPF-SGD、FuzzyPID)。
你看,只有Adam系列的优化器能让DDPM输出像模像样的数字,其他优化器(尤其是SGD、SGDM)生成的几乎全是噪声!这背后藏着什么玄机?且听龙哥慢慢道来。
生成模型的“幻觉”从何而来? 咱们先来聊聊最前沿的AI模型——大语言模型(LLM,Large Language Model)如ChatGPT、大型视觉生成模型(LVGM,Large Vision Generation Model)如Stable Diffusion,它们经常出现一个让人头疼的问题:幻觉(Hallucination)
现有的研究都在微观层面下功夫:比如用检索增强生成(RAG,Retrieval Augmented Generation)给LLM喂外部知识库的数据;或者改进模型结构、加各种loss函数来减少幻觉。但问题是,这些方法都像“头痛医头、脚痛医脚”,没有从根源上解释为什么模型会产生幻觉。
那么,有没有一个更宏观、更底层的视角来理解这件事?这篇论文的作者们想到了一个经典的工具——控制理论(Control Theory)
用“控制论”火眼金睛看透幻觉本质 作者把生成模型(GM,Generation Model)的训练过程类比成一个随机动态系统
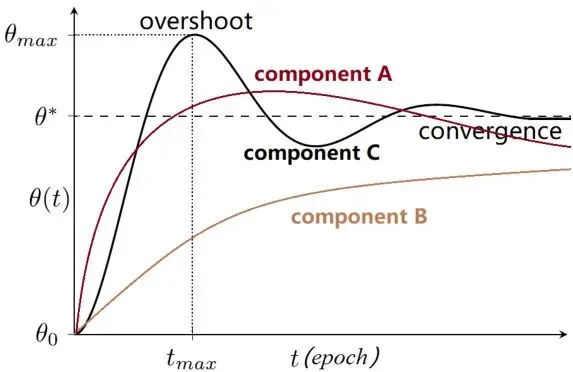
而“幻觉”对应的是什么?对应的是系统的超调量(overshoot)和振动(vibration)
图1:生成任务中每个组件权重θ(t)的演化过程。图中标记了最大超调量θ_max和达到最大振动的时间t_max。最优的学习过程应该有一个适当的振动(太小则学习慢,太大则不稳定),且最终收敛到最优解θ*。
从控制论的角度看,一个“健康”的生成模型应该满足:系统稳定 快速收敛
拉普拉斯变换:优化器的“照妖镜” 要分析一个动态系统的稳定性,工程师们最常用的工具就是拉普拉斯变换(Laplace Transform)
这篇论文的核心贡献就是对多种常用优化器进行拉普拉斯变换,得到它们的系统函数
SGD(随机梯度下降) P控制器(比例控制器) SGDM(带动量的SGD) PI控制器(比例-积分控制器)
这里r是学习率,α是动量系数(通常0.9),s是复频率变量。
PID优化器
其中K_d是微分增益。注意这里还有一个来源于动量累积的积分项。
Adam(自适应矩估计) 滤波器处理的SGD(LPF-SGD / HPF-SGD)
这里G是滤波器增益,h_i和l_j分别是零点和极点。
FuzzyPID(模糊PID)
其中widehatK表示经过模糊逻辑修正后的增益。通过合理选择学习率θ(s)可以变成一个稳定系统。
有了这些系统函数,就可以像分析电路一样,用MATLAB Simulink
图3:经典GAN在不同优化器上的系统响应。可以看到,Adam的响应最终收敛并稳定,而其他优化器(SGDM、LPF-SGD、PID等)出现了明显的基线漂移,说明系统不稳定。
实验验证:系统响应与实际效果“神同步” 光说不练假把式。作者在三个经典生成模型上进行了真实训练实验:经典GAN CycleGAN DDPM
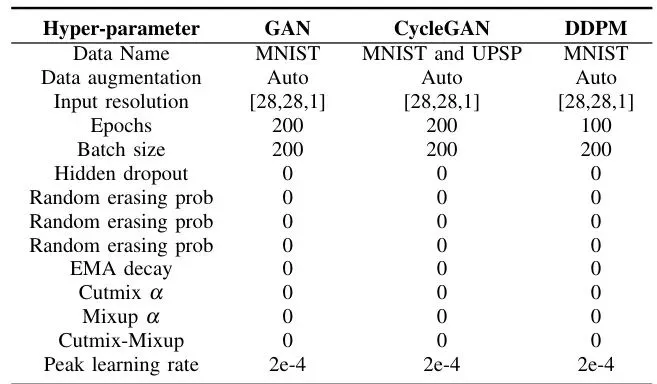
表I:图像生成任务的超参数(GAN、CycleGAN、DDPM)。注意所有优化器的峰值学习率都设为2e-4,以保证公平。
对于滤波器优化器(LPF-SGD和HPF-SGD),其滤波器系数用二阶IIR结构实现:
实验结果非常直观。下图展示了经典GAN在不同优化器下生成的MNIST样本:
图6:经典GAN在不同优化器下生成的样本。只有Adam能持续生成清晰可辨的数字(0-9),其他优化器(尤其是SGDM、PID、FuzzyPID等)在训练后期生成的样本充满了噪声,完全看不出是什么数字。这正好对应了图3的仿真结果——只有Adam的系统是收敛稳定的,其他优化器在大约200个epoch后出现了发散。
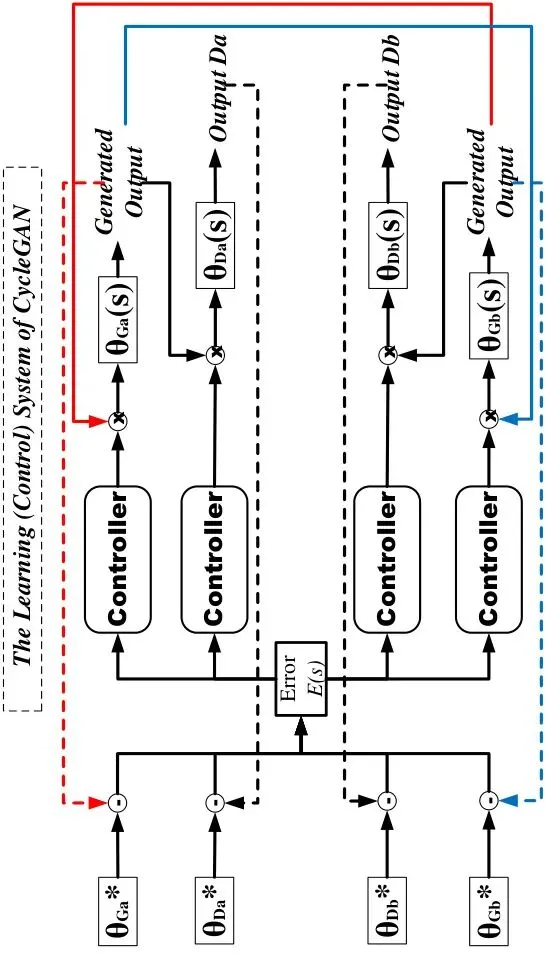
更精彩的发现来自CycleGAN。CycleGAN有双生成器(G_a和G_b)和双判别器(D_a和D_b),加上循环一致性损失。作者将其建模成更复杂的控制环路(图4),仿真结果(图5)和真实生成结果(图7)再次高度一致。
图4:CycleGAN的控制系统框图,包含两个生成器G_a、G_b和两个判别器D_a、D_b,以及循环一致性反馈。
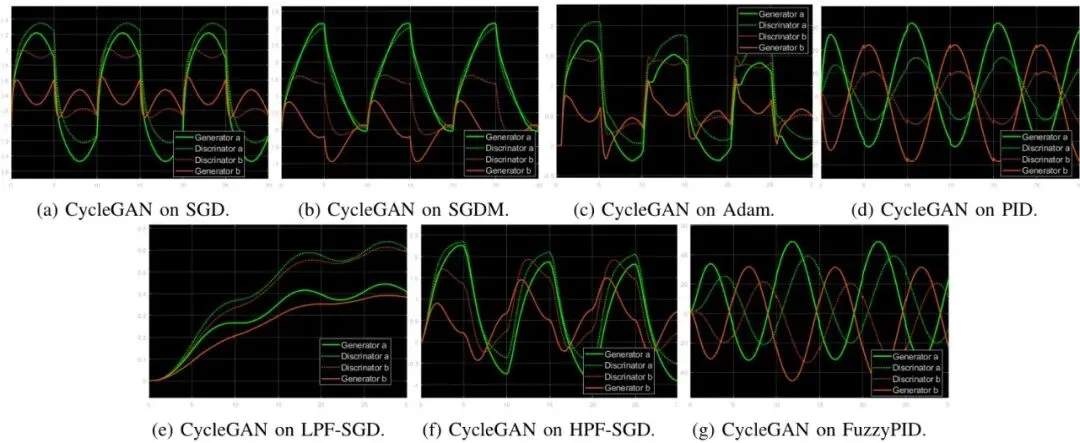
图5:CycleGAN在不同优化器上的系统响应。FuzzyPID和PID能完美复现正弦/余弦波形,而SGD、Adam虽然也有一定的波形,但幅度不稳定,有发散风险。
图7:CycleGAN真实生成的MNIST→UPSP翻译结果。FuzzyPID和PID生成的样本清晰、无错误;而SGDM和SGD等优化器生成了大量红色标记的错误(幻觉)样本。
对于DDPM,Adam同样一家独大。下图展示DDPM在100个epoch后的生成结果:
图9:DDPM的生成结果。只有Adam(以及Adam系列优化器如AdamW、RAdam等,论文中有额外实验)能输出清晰的数字,其他优化器几乎全部失效。
新思路:如何设计“对味”的优化器? 通过拉普拉斯变换分析,作者揭示了生成模型对优化器有明确的“偏好”
– GAN DDPM Adam家族
– CycleGAN PID和FuzzyPID
基于这些发现,作者提出了两种从根源上优化幻觉的方法
1. 为模型匹配合适的优化器
2. 设计更好的学习系统
这个框架的妙处在于,它不仅解释了为什么有些优化器在某些模型上工作得更好,而且提供了一个提前预测优化器效果
龙迷三问
这篇论文解决什么问题?
文章中用到的拉普拉斯变换具体是干什么的?
为什么PID和FuzzyPID在CycleGAN上表现好,而在GAN上不行?
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数: ★★★★★
龙哥认为这一星必须拉满!把控制理论的拉普拉斯变换引入生成模型幻觉分析,这个跨界视角非常新颖且极具启发性。虽然之前有PID优化器的工作,但本文是首次系统性地对多种优化器进行拉普拉斯变换,并直接关联到生成模型的幻觉问题。
实验合理度: ★★★★☆
实验设计合理:在三个不同代表性的生成模型(GAN、CycleGAN、DDPM)上测试了七种优化器,仿真与实际训练结果一致,可信度高。扣一星是因为只用了MNIST和UPSP两个小数据集,缺乏在更大、更真实场景(如ImageNet、COCO)上的验证。
学术研究价值: ★★★★★
研究价值爆炸!为生成模型领域提供了一种全新的系统性分析框架。未来的研究者可以基于这个方法,设计出更匹配特定模型的优化器,甚至指导新的模型架构设计。将控制论与深度学习结合,打开了跨学科研究的新大门。
稳定性: ★★★☆☆
论文提出的方法本身(先用Simulink仿真再选择优化器)是稳定的,但最终生成的模型稳定性取决于选中的优化器。比如用Adam在GAN上效果稳定,但如果在CycleGAN上用Adam则效果一般。所以稳定性得分中等。
适应性以及泛化能力: ★★★★☆
通过仿真提前预测优化器效果,这个框架理论上可以应用于任何生成模型。但论文只验证了图像生成任务(MNIST和UPSP),对于大语言模型(LLM)等其他模态的生成模型尚待验证。不过由于拉普拉斯变换的通用性,龙哥认为泛化潜力很大。
硬件需求及成本: ★★★★☆
仿真过程用MATLAB Simulink,不需要GPU。实际训练时和普通生成模型训练成本一样(论文使用单张A100 40GB GPU)。额外开销仅在于训练前做的仿真,基本可忽略。扣一星是因为仿真需要对控制理论有一定了解,入门成本略高。
复现难度: ★★★★☆
论文没有提供开源代码,但给出了详细的系统和仿真设置(Simulink模型、滤波器系数等),优化器公式也清晰列出来了。对于熟悉PyTorch和MATLAB的读者,复现难度中等偏下。扣一星是因为没有开源代码,需要自己实现部分细节。
产品化成熟度: ★★★☆☆
目前更像是一种方法论指导,而非直接可用的产品。不过,对于从事生成模型训练的开发者和研究员来说,这篇论文提供了一个可操作的工具:在给定新模型后,先用仿真快速筛选优化器,避免盲目的网格搜索。对于直接落地应用,还需要在更大规模、更复杂的数据集上验证。
可能的问题: 论文假设每个生成模型可以简化为一个二阶系统,这个假设是否普适?对更复杂的模型(如ViT、Diffusion Transformer)可能需要高阶近似。另外,仿真时使用了理想化的信号源(正弦波、方波),与实际训练数据的随机性有差距。
[1] Rawte, V., Sheth, A., & Das, A. (2023). A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922. [2] Aithal, S. K., Maini, P., Lipton, Z. C., & Kolter, J. Z. (2024). Understanding hallucinations in diffusion models through mode interpolation. arXiv preprint arXiv:2406.09358. [5] Shuster, K., Poff, S., Chen, M., Kiela, D., & Weston, J. (2021). Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567. [12] Wang, H., Luo, Y., An, W., Sun, Q., Xu, J., & Zhang, L. (2020). PID controller-based stochastic optimization acceleration for deep neural networks. IEEE Trans. Neural Networks and Learning Systems, 31(12), 5079-5091. [15] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. NeurIPS. [16] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS, 33, 6840-6851. [28] Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. ICCV.
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的 “阅读原文”, 查看更多原论文细节哦!
🎯 还在被AI模型胡编乱造(幻觉)折磨?别急!这篇论文教你用拉普拉斯变换当“照妖镜”,一眼看穿哪个优化器最能镇住幻觉!想跟龙哥一起探索更多治“病”良方?快来粉丝群和高手们对线吧!
扫描下方二维码或者添加龙哥助手微信号加群 :kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥) ,根据格式备注,可更快被通过且邀请进群。『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群。
 夜雨聆风
夜雨聆风