 夜雨聆风
夜雨聆风





跟我学 AI Agent : 第 10 课 — Memory Management:让Agent拥有记忆
模块: 模块三:高级编排与规划 | 难度: ⭐⭐⭐ | 预计时长: 3.0 小时参考: Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systemspi-mono API: AgentState, transformContext()
🧠 “记忆是智慧之母。”— 埃斯库罗斯
1. 开篇故事:每天重新认识你的朋友
想象你有这样一个朋友——
每天早上见面,他都不记得你是谁。
“你好,请问你叫什么名字?”“我叫Jack啊,我们昨天聊了一整天……”“是吗?那请问你是做什么工作的?”“我是程序员,昨天跟你说过三遍了。”“哦,那你用什么操作系统?”“macOS。我昨天还帮你调试了一个shell脚本……”
你每次对话,都要从零开始:重新介绍自己、重新解释背景、重新说明偏好。一天下来,你花了80%的时间在重复昨天说过的话,只有20%在做真正有意义的事。
这个”健忘的朋友”,就是没有记忆的 Agent。
现在换一个场景:你有一个同事,你们合作了三年。他知道你用 macOS、偏好 TypeScript、讨厌深嵌套的代码、最近在做一个 Agent 课程项目。你只需说”继续昨天的进度”,他就能从上次断点无缝接上。
这个”默契的老搭档”,就是拥有记忆的 Agent。
从”健忘的朋友”到”默契的老搭档”,中间差的不是智商,而是记忆。
💡 核心问题: LLM 本身是无状态的——同样的 prompt 永远给出同样的回答。Agent 如何跨越”无状态”的鸿沟,获得持续记忆的能力?
2. 为什么记忆对 LLM Agent 至关重要
在深入技术细节之前,我们需要先理解一个根本性的矛盾:LLM 的能力很强,但持续性为零。
2.1 LLM 的”无状态”本质
LLM 是一个纯函数:输入 prompt,输出 completion。它没有内部状态,没有”上次对话”的概念。
你: "我叫Jack"LLM: "你好Jack!很高兴认识你!"(新对话)你: "我叫什么名字?"LLM: "抱歉,我不知道你的名字。"这不是 bug,而是 LLM 的设计本质。每次调用都是独立的,模型权重在两次调用之间不会改变。就像一个超级博学但每次见面都失忆的教授——他什么都知道,就是不记得跟你说过什么。
那现有的 Agent 是怎么”记住”对话的?靠的是把历史消息拼进 prompt:
[System] 你是一个助手[User] 我叫Jack[Assistant] 你好Jack![User] 我叫什么名字? ← LLM 能回答,因为历史消息在 prompt 里[Assistant] 你叫Jack。这就是所谓的短期记忆——把对话历史塞进 Context Window。它有效,但有致命的限制。
2.2 短期记忆的天花板
Context Window 就像一个固定大小的白板:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
看起来很大?但现实是:
问题一:Token 成本
每轮对话都要把全部历史重新发给 LLM。对话越长,token 消耗越大。一个 100 轮的对话,第 100 轮要付 100 轮的 token 费用。
第1轮: [System] + [User1] + [Asst1] → 500 tokens第10轮: [System] + [User1-10] + [Asst1-10] → 5,000 tokens第50轮: [System] + [User1-50] + [Asst1-50] → 25,000 tokens第100轮: [System] + [User1-100] + [Asst1-100] → 50,000 tokens ↑ 成本线性增长问题二:信息稀释(Lost in the Middle)
研究表明(Context Engineering:长上下文是如何失效的?),LLM 对超长上下文中的信息提取能力并非均匀分布。它对开头和结尾的信息关注度高,对中间的信息经常”视而不见”。斯坦福大学 2023 年的研究 “Lost in the Middle” 发现:当上下文中有大量文档时,放在中间位置的文档被正确引用的概率显著下降。
这意味着:往 Context Window 塞太多信息,不仅没有帮助,反而会降低回答质量。
问题三:会话结束即遗忘
Context Window 是临时的。会话一旦结束,白板被擦干净。下次新对话,一切从零开始。
会话A(周一): 你: "我喜欢TypeScript,用macOS" Agent: "记住了!" (会话结束 → 历史消失)会话B(周三): 你: "帮我写一个脚本" Agent: "好的,你用什么语言?什么系统?" ← 完全不记得了这三个问题叠加在一起,揭示了一个核心矛盾:Context Window 是必要的短期记忆,但它远远不够。
2.3 没有记忆的 Agent 到底差在哪里?
让我们用具体场景来感受差异:
场景一:客服机器人
没有记忆:
用户: "我的订单 #12345 还没到"Agent: "让我查一下……订单 #12345,状态:运输中,预计明天到达。"用户: "那我明天不在家怎么办?"Agent: "您是说要改配送地址吗?请问您的订单号是多少?" ← 忘了有记忆(短期):
用户: "我的订单 #12345 还没到"Agent: "订单 #12345 运输中,预计明天到。"用户: "那我明天不在家怎么办?"Agent: "您要改配送时间或地址吗?我可以帮您安排后天配送。"有记忆(长期):
用户: "我的订单还没到"Agent: "您是说订单 #12345 吗?按您之前的偏好,我帮您安排放在门口快递柜。需要我联系快递员吗?" ↑ 记住了订单号 + 配送偏好场景二:编程助手
没有记忆:
程序员: "我的项目用 TypeScript + Node.js,包管理器是 pnpm"Agent: "了解了!"(新会话)程序员: "帮我加一个新 API 端点"Agent: "好的,请问你的项目用什么语言?包管理器是npm还是yarn?测试框架用的什么?" ← 每次都要重新交代项目背景有记忆:
程序员: "帮我加一个新 API 端点"Agent: "基于你的 TypeScript + pnpm 项目结构,我建议在 src/routes/ 下新增文件。 要不要我按照你之前偏好的模式:Zod schema 验证 + Express Router?" ↑ 记住了技术栈 + 编码风格偏好场景三:多步骤任务
一个数据分析 Agent 需要完成:获取数据 → 清洗 → 分析 → 生成报告。
没有记忆:
步骤1完成 → 结果丢失步骤2: "请问数据源在哪里?格式是什么?" ← 不记得步骤1的输出有短期记忆(但任务跨会话):
周一:完成数据获取和清洗(会话结束)周二:继续分析 → "上次清洗的中间结果呢?" ← 会话间没有记忆传递有长期记忆:
周一:完成获取和清洗,中间结果存入记忆周二:Agent 自动调取上次的清洗结果,从分析步骤继续2.4 记忆:从”工具”到”伙伴”的分水岭
把上面的观察归纳起来,记忆对 Agent 的影响不只是”方便”,而是质变:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Antonio Gulli 用一句话概括了这个洞察:
“Without a memory mechanism, agents are stateless, unable to maintain conversational context, learn from experience, or personalize responses for users. This fundamentally limits them to simple, one-shot interactions.”
翻译过来:没有记忆,Agent 永远被锁在”一次性工具”的牢笼里。
记忆不是锦上添花的功能,而是 Agent 从”工具”进化为”伙伴”的基础设施。就像数据库之于 Web 应用——你不会说”数据库是 Web 应用的可选功能”,因为没有了它,应用连基本的用户登录都做不了。
理解了”为什么”之后,接下来的问题就是”怎么做”——如何为 Agent 构建一套完整的记忆系统?这正是下一节要回答的。
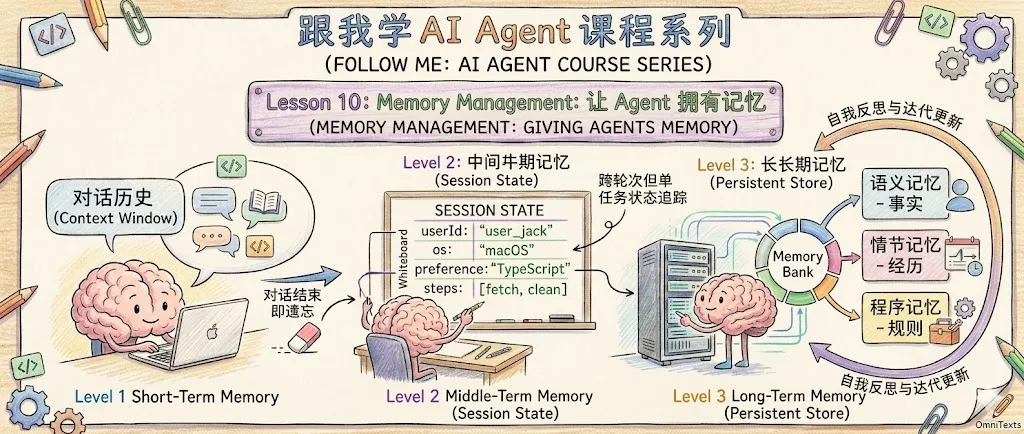
3. 记忆的三层模型
人的记忆不是一坨混沌的东西。认知科学告诉我们,人脑至少有工作记忆(你此刻在想的)、短期记忆(今天发生的事)和长期记忆(你的知识和经验)。
Agent 的记忆也可以类比为三层结构,从最临时的到最持久的:
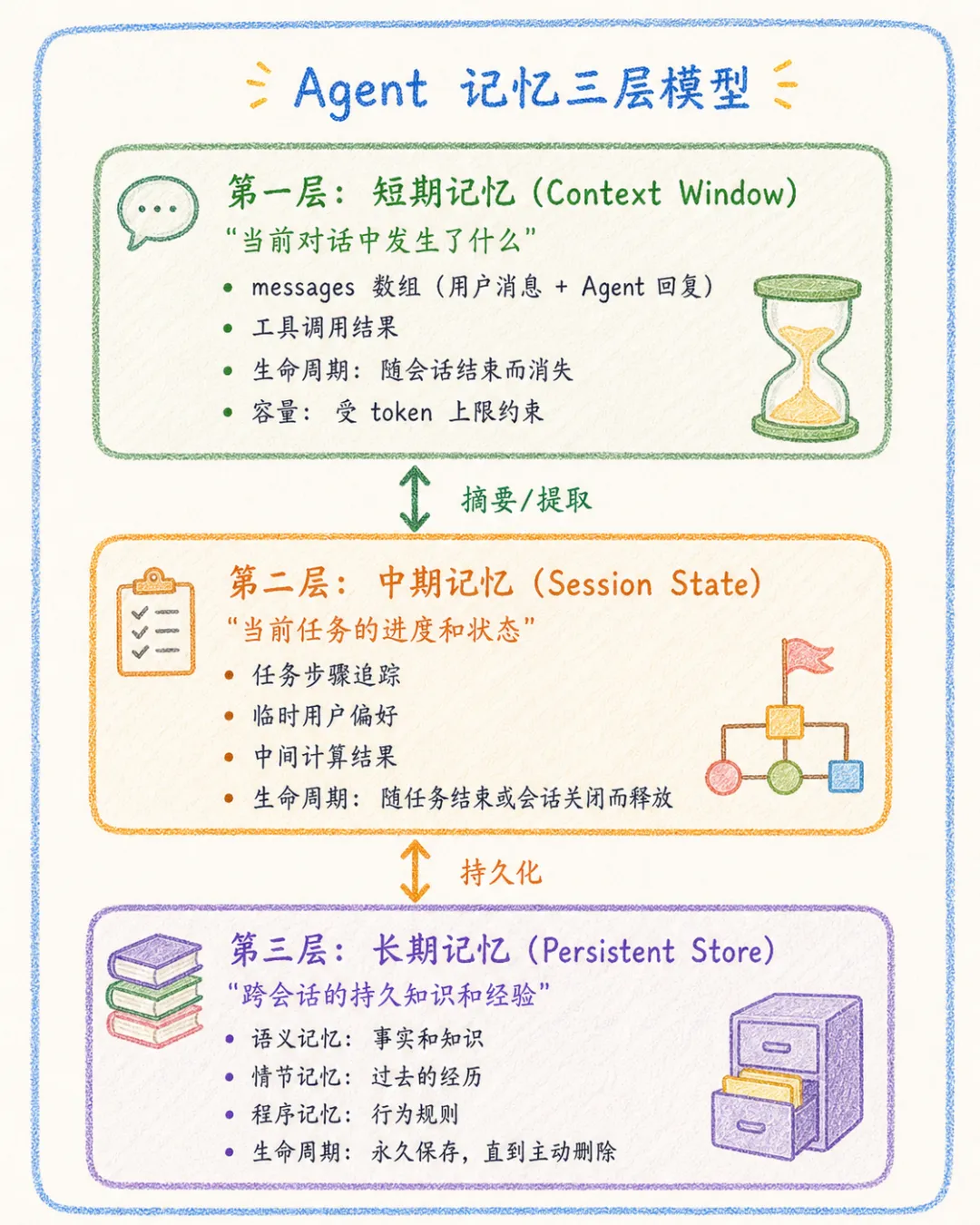
记忆可以分为短期和长期两大类,但实践中,中期记忆(Session State) 承上启下,不可或缺。下面逐层拆解。
3.1 第一层:短期记忆(Context Window)
是什么: 当前对话中所有消息的集合——用户输入、Agent 回复、工具调用和返回结果。就是 LLM 每次调用时收到的 messages 数组。
类比人脑: 工作记忆(Working Memory)。你此刻脑中能同时处理的信息量,大约 7±2 个”组块”。
核心限制:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
管理策略:
-
1. 滑动窗口(Sliding Window):只保留最近 N 轮对话,丢弃更早的。简单粗暴,但会丢失重要信息。
保留最近 10 轮:[User_11] [Asst_11] [User_12] [Asst_12] ... [User_20] [Asst_20] ↑ 最早的 10 轮被丢弃-
2. 摘要压缩(Summarization):用 LLM 把旧对话压缩成一段摘要,替代原始消息。这是最常用的策略。
压缩前(2000 tokens 的旧对话): [User] "我叫Jack" → [Asst] "你好Jack" [User] "我用macOS" → [Asst] "了解了" [User] "帮我写个脚本" → [Asst] "好的,什么语言?" ... (20轮)压缩后(200 tokens): [Summary] "用户叫Jack,使用macOS。之前讨论了编写shell脚本, 使用TypeScript + Node.js,包管理器pnpm。"当前对话: [Summary] + [最近5轮原始消息]-
3. 关键信息提取:从对话中识别并提取关键实体(人名、偏好、决策),单独存储,确保不丢失。
这三种策略不是互斥的,而是组合使用的。后面代码实战会看到具体实现。
3.2 第二层:中期记忆(Session State)
是什么: 跨多个轮次但仍在同一个任务/会话中的结构化状态。它不是对话历史的简单堆叠,而是经过组织的任务数据。
类比人脑: 你在做一道复杂数学题时,草稿纸上记的中间步骤、当前算到哪一步、用的是什么方法。
典型存储内容:
Session State(key-value 字典):{ "task_phase": "data_cleaning", // 当前任务阶段 "steps_completed": ["fetch", "parse"], // 已完成步骤 "steps_remaining": ["clean", "analyze"], // 剩余步骤 "data_source": "users.csv", // 数据源 "row_count": 15432, // 中间结果 "user_preference_lang": "python", // 临时偏好 "errors_encountered": ["encoding: utf-8 fail, fallback to latin-1"]}与短期记忆的区别:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
为什么需要中期记忆? 因为不是所有信息都适合用自然语言对话来传递。比如”当前已完成第3步,共7步”——这种结构化状态用 key-value 存取远比塞进对话历史高效且准确。
Google ADK 的 session.state 就是典型的中期记忆实现,它使用前缀来区分数据作用域:
-
• 无前缀:会话级别,仅当前对话可见 -
• user:前缀:用户级别,该用户的所有会话共享 -
• app:前缀:应用级别,所有用户共享 -
• temp:前缀:仅当前处理轮次,不持久化
3.3 第三层:长期记忆(Persistent Store)
是什么: 跨会话、跨任务的持久化知识。会话结束了它还在,下次新对话时可以调取。
类比人脑: 你的知识、经历和技能——不会因为你睡了一觉就消失。
长期记忆可以进一步分为三种类型,借用认知心理学的经典分类:
语义记忆(Semantic Memory)—— “知道什么”
记住事实和知识。就像你知道”巴黎是法国的首都”,Agent 需要知道关于用户的客观事实。
语义记忆示例:{ "user_profile": { "name": "Jack", "language": "Chinese", "os": "macOS", "tech_stack": ["TypeScript", "Node.js", "pnpm"], "preferences": { "code_style": "函数式,避免深嵌套", "response_length": "详细" } }}存储方式: 通常是 JSON 文档或向量嵌入。可以是一个持续更新的”用户档案”,也可以是一组独立的事实文档。
检索方式: 直接读取(用户档案)或语义搜索(事实集合)。
pi-mono 场景: Agent 的 persona 配置、用户 profile 文件。
情节记忆(Episodic Memory)—— “经历过什么”
记住过去的经历和事件。就像你记得”上次去巴黎吃了家很好的可丽饼店”,Agent 需要记住过去的交互经历。
情节记忆示例:{ "past_experiences": [ { "date": "2026-04-20", "task": "解析CSV文件", "approach": "使用csv-parser库,逐行处理", "outcome": "成功,但遇到编码问题", "lesson": "大文件先检测编码再读取" }, { "date": "2026-04-21", "task": "部署到Cloudflare", "approach": "wrangler deploy", "outcome": "成功", "lesson": "部署前检查wrangler.toml的compatibility_date" } ]}情节记忆在实践中经常通过Few-shot 示例来实现:Agent 回忆过去成功的交互序列,作为当前任务的参考。这与 L04(Reflection)模式天然配合——反思的结果存入情节记忆,下次遇到类似情况时调取。
存储方式: 向量数据库(按语义相似度检索相关经历)或时间序列数据库(按时间检索)。
检索方式: “当前任务与过去哪些经历最相似?” → 语义搜索 Top-K。
pi-mono 场景: 过去任务的执行记录和反思日志。
程序记忆(Procedural Memory)—— “怎么做”
记住行为规则和技能。就像你学会了骑自行车之后不需要再思考每一步怎么做,Agent 需要记住”在什么情况下应该采取什么行动”。
程序记忆示例:{ "rules": [ "当用户报告bug时,先查看日志再建议解决方案", "生成代码后自动运行lint检查", "遇到API错误时,先检查密钥是否过期", "用户说'简单说一下'时,回复控制在3句话以内" ]}程序记忆最有趣的地方在于:它可以是 Agent 自己修改的。一种强大的技术——让 Agent 通过”反思”来更新自己的行为规则:
1. Agent 用当前的程序记忆(规则集)处理任务2. 任务完成后,反思执行过程:"哪些规则有效?哪些需要修改?"3. 生成新的/修改后的规则4. 将更新后的规则存回程序记忆这其实就是 L07(Reflection)模式在记忆层面的应用——Agent 不仅反思任务结果,还反思自己的行为模式,并据此优化规则。
存储方式: 通常存放在 Agent 的 system prompt 中,或独立的规则文件。
检索方式: 每次对话开始时,加载为 Agent 的行为指令。
pi-mono 场景: Agent 的 instruction 模板 + 通过 extension 管理的行为规则。
三种长期记忆的对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三者协同工作:语义记忆告诉 Agent “用户是谁”,情节记忆告诉 Agent “之前怎么做的”,程序记忆告诉 Agent “以后应该怎么做”。
4. 记忆的写入与检索
理解了记忆的三层结构之后,关键问题来了:什么时候写?怎么检索?怎么更新?
这是记忆系统最核心的工程问题,也是区分”玩具级记忆”和”生产级记忆”的关键。
4.1 什么时候写入记忆?
记忆写入有三种时机:
策略一:每轮对话后自动写入
用户每说一句话 → Agent 回复 → 自动提取关键信息 → 写入记忆优点:不会遗漏。缺点:噪音太多。”你好”、”谢谢”这种消息也触发写入,会产生大量无用记忆。
策略二:任务完成后写入
完整任务结束 → 总结整个过程 → 提取经验教训 → 写入记忆优点:记忆质量高,都是经过提炼的。缺点:如果任务中途崩溃,什么都记不住。
策略三:检测到重要信息时写入
每轮对话 → 判断"这条信息是否值得记住" → 是则写入,否则跳过这是最常用的策略,但核心难题在于:谁来决定什么是”重要的”?
4.2 谁来决定写什么?(记忆提取策略)
这是实践中最容易被忽视、却最影响记忆质量的问题。
方案A:LLM 自己判断(In-context Extraction)
让 LLM 在每轮对话后,自己判断哪些信息值得记住:
给 LLM 的提取 prompt:"以下是一段对话。请提取出值得长期记住的信息: - 用户的事实性信息(姓名、偏好、背景) - 重要的决策或结论 - 有价值的经验教训 如果没有值得记住的信息,返回空列表。"对话内容:[User] "帮我用Python写个爬虫"[Asst] "好的,用requests还是scrapy?"[User] "我喜欢用requests,简单直接,不喜欢重框架"[Asst] "了解,那我给你写一个基于requests的..."LLM 提取结果:{ "fact": "用户偏好轻量级工具,不喜欢重框架", "tech_preference": "Python HTTP 库偏好 requests > scrapy"}优点:灵活,能捕捉隐含信息(”不喜欢重框架”这种偏好不会明确说出来,但 LLM 能理解)。缺点:不稳定——同样的对话,两次提取可能得到不同结果。成本也高(每轮额外一次 LLM 调用)。
方案B:规则驱动(Keyword/NER 提取)
用预定义的规则或命名实体识别(NER)来提取信息:
规则示例:- 检测到 "我叫XXX" / "我的名字是XXX" → 写入 user.name = XXX- 检测到 "我喜欢XXX" / "偏好XXX" → 写入 user.preferences- 检测到 "不要XXX" / "不喜欢XXX" → 写入 user.negative_preferences- 检测到错误报告 → 写入 error_log优点:可靠、可预测、成本为零。缺点:死板,无法捕捉隐含信息。”我一般用TS写后端”不会匹配任何规则,但显然是有价值的偏好信息。
方案C:混合方案(推荐)
结合两种方案的优点:
第一层(规则):快速、零成本地捕获明确的结构化信息 → "我叫Jack" → name = "Jack" → "订单号#12345" → current_order = "12345"第二层(LLM):定期(比如每5轮或任务关键节点)用 LLM 做深度提取 → 发现隐含偏好、经验教训、情绪状态写入策略: - 规则捕获的 → 立即写入,高置信度 - LLM 提取的 → 写入前校验(与现有记忆比对,避免矛盾)Google Vertex AI Memory Bank 用的就是类似的混合方案:它用 Gemini 模型异步分析对话历史,提取关键事实和偏好,然后与已有记忆比对,自动合并和解决矛盾。
4.3 怎么检索记忆?
检索是记忆的”另一半”。写了很多记忆但检索不到,等于没写。
检索方式一:关键词匹配
最简单的方式——在记忆库中搜索包含特定关键词的条目。
用户: "我上次那个CSV解析的问题解决了吗?"关键词提取: ["CSV", "解析", "问题"]记忆搜索: SELECT * FROM memories WHERE content LIKE '%CSV%' OR content LIKE '%解析%'优点:快速、简单、无额外成本。缺点:语义鸿沟——搜”解析”找不到”数据清洗”,搜”bug”找不到”错误”。
检索方式二:语义相似度搜索(向量检索)
将记忆和查询都转化为向量(embedding),按语义相似度排序返回 Top-K 条。
用户: "我上次那个CSV解析的问题解决了吗?"查询向量: embed("CSV解析问题")记忆库搜索: 1. "处理 users.csv 时遇到编码错误" → 相似度 0.92 ✓ 2. "使用 csv-parser 库逐行读取" → 相似度 0.85 ✓ 3. "部署到 Cloudflare 的步骤" → 相似度 0.31 ✗返回 Top-2推荐这种方式:”In vector databases, information is converted into numerical vectors and stored, enabling agents to retrieve data based on semantic similarity rather than exact keyword matches.”
检索参数的关键选择:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Vertex AI RAG MemoryService 的默认配置是 Top-K=5,向量距离阈值=0.7,可以作为起步参考。
4.4 检索结果怎么注入?
检索到记忆后,怎么”喂”给 Agent?注入位置对效果影响很大。
方式一:拼入 System Prompt
[System]你是一个编程助手。以下是关于用户的已知信息:- 用户名:Jack- 技术栈:TypeScript, Node.js- 偏好:函数式编程风格- 过去遇到的问题:CSV编码问题(已解决)[User] 帮我写一个文件读取函数优点:Agent 一开始就知道背景信息,贯穿整个对话。缺点:占用 System Prompt 空间;所有检索到的记忆都被同等对待,没有区分相关性。
方式二:作为独立消息注入
[System] 你是一个编程助手。[Memory] 以下记忆与当前问题相关: - 用户偏好函数式编程风格 - 过去用 fs.readFileSync 出过性能问题[User] 帮我写一个文件读取函数优点:结构清晰,可以动态调整注入内容。缺点:增加了一条额外消息,占 token。
方式三:作为 Tool 结果返回
[User] 帮我写一个文件读取函数[Tool Call] search_memory("文件读取")[Tool Result] 发现相关记忆:用户偏好函数式风格,过去用同步读取有性能问题[Assistant] 基于你的偏好,我用流式读取...优点:按需检索,不浪费 token;检索结果与当前问题高度相关。缺点:需要额外一轮 LLM 调用来决定是否检索记忆。
实践中,方式一适合少量核心记忆(用户档案),方式二适合中等规模,方式三适合大规模记忆库。可以组合使用。
4.5 记忆的衰减与更新
记忆不是一成不变的。用户说”我现在用 Python 了”,你不能还记着”用户用 TypeScript”。
三个核心问题:
问题一:旧记忆要淘汰吗?
不是所有旧记忆都应该保留。”用户今天心情不好”可能三天后就没意义了,但”用户名是 Jack”永远有效。
常见策略:
-
• 时间衰减:每条记忆带时间戳,检索时按 相似度 × 时间衰减因子排序 -
• 访问计数:经常被命中的记忆保留,长期未命中的降级或归档 -
• 手动标注有效期:写入时标记过期时间(”临时偏好” vs “永久事实”)
问题二:矛盾信息怎么处理?
现有记忆: "用户使用 TypeScript"新信息: "我不用TypeScript了,转Rust了"处理方式:
-
• 覆盖:直接用新信息替换旧信息(适合事实类) -
• 追加:两条都保留,检索时按时间排序(适合经历类) -
• 合并:LLM 自动合并两条记忆为一条综合信息
Vertex AI Memory Bank 会自动”consolidate new data and resolve contradictions”——这正是生产级记忆系统需要的能力。
问题三:记忆容量管理
长期记忆库不能无限增长。需要:
-
• 定期归档低频访问的记忆 -
• 合并重复或高度相似的记忆条目 -
• 为不同类型的记忆设置不同的容量上限
5. 记忆架构的模式
不同的应用场景需要不同的记忆架构。从简单到复杂,有四种经典模式:
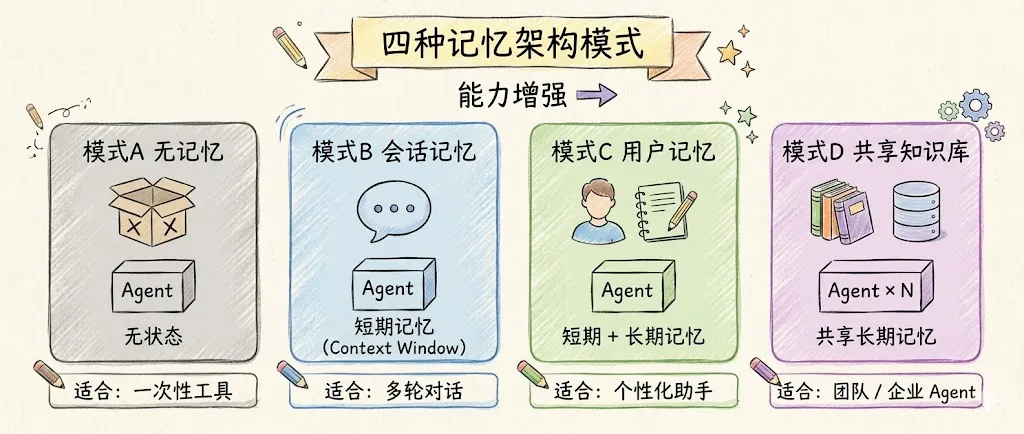
模式A:无记忆(纯函数式)
输入 → LLM → 输出每次调用独立,不保存任何状态。
适合场景: 一次性工具调用——翻译一句话、格式化一段代码、提取关键信息。用完即走,无需后续。
优点: 最简单、无状态、易测试、可水平扩展。缺点: 无法进行多轮对话。
// 模式A:无记忆的纯函数式 Agentimport { Agent } from"@mariozechner/pi-agent-core";import { getModel } from"@mariozechner/pi-ai";const translator = newAgent({name: "translator",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: "你是一个中英翻译器。直接输出翻译结果,不加解释。",});// 每次调用完全独立const result1 = await translator.prompt("翻译:今天天气不错");// "Nice weather today."const result2 = await translator.prompt("我上一句让你翻译了什么?");// "抱歉,我没有之前对话的记录。" ← 完全无状态模式B:会话记忆
保留当前会话的对话历史,但会话结束后记忆消失。
适合场景: 单次多轮对话——客服对话、一次性任务咨询、代码评审。
优点: 实现简单(框架自动管理 messages 数组),能满足大部分单次对话需求。缺点: 无法跨会话,无法积累用户知识。
// 模式B:会话记忆(messages 数组自动管理)const agent = newAgent({name: "coding-assistant",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: "你是一个编程助手。",});// pi-mono 的 Agent 自动维护 messages 历史const stream = agent.stream("我叫Jack,我用TypeScript");forawait (const event of stream) {if (event.type === "text") process.stdout.write(event.text);}// 同一个 Agent 实例内,上下文保持const stream2 = agent.stream("我叫什么名字?");// "你叫Jack。" ← 记住了,但仅限当前会话模式C:用户记忆
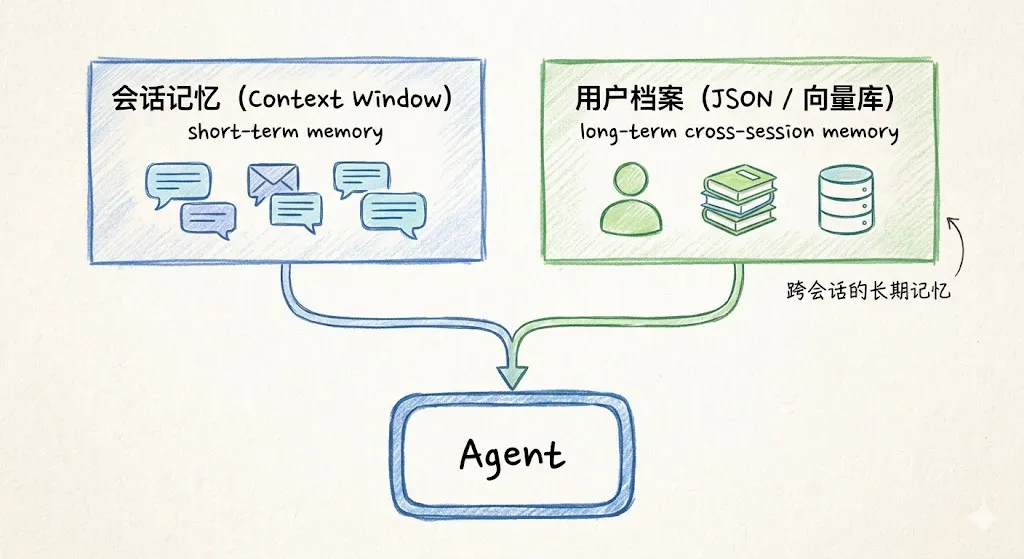
每个用户拥有独立的长期记忆档案。新会话开始时,加载用户档案注入 Agent。
适合场景: 个性化助手——私人 AI 助手、学习伴侣、健康顾问。
优点: 跨会话的个性化体验,Agent “认识”每个用户。缺点: 需要用户身份认证,需要持久化存储,隐私问题更复杂。
// 模式C:用户记忆(文件持久化)import { readFileSync, writeFileSync, existsSync } from"fs";// 用户档案路径constprofilePath = (userId: string) => `./memory/profiles/${userId}.json`;// 加载用户档案functionloadUserProfile(userId: string): Record<string, any> {if (!existsSync(profilePath(userId))) return {};returnJSON.parse(readFileSync(profilePath(userId), "utf-8"));}// 保存用户档案functionsaveUserProfile(userId: string, profile: Record<string, any>) {writeFileSync(profilePath(userId), JSON.stringify(profile, null, 2));}// 新会话时,将用户档案注入 system promptconst userId = "user_jack";const profile = loadUserProfile(userId);const agent = newAgent({name: "personal-assistant",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: `你是一个私人AI助手。以下是关于用户的已知信息:${JSON.stringify(profile, null, 2)}请基于这些信息提供个性化服务。`,});// 对话结束后,提取并更新档案// (后面代码实战会展示完整的提取逻辑)模式D:共享知识库
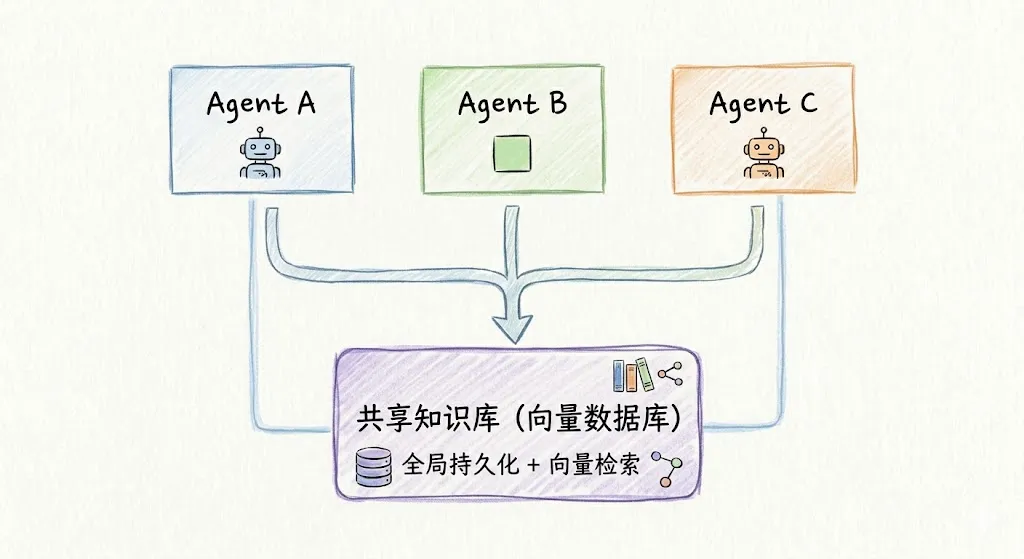
多个 Agent 共享同一个知识库,互相积累的知识可以交叉复用。
适合场景: 团队/企业 Agent——客服团队共享产品知识、研发团队共享技术文档。
优点: 知识复用效率最高,新 Agent 能立即”继承”已有知识。缺点: 权限管理复杂,记忆一致性需要额外处理(Agent A 的经验可能不适用于 Agent B 的场景)。
四种模式的选择指南
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个重要原则:从最简单的模式开始,只在有明确需求时才升级。 不要一上来就搭建模式D——大部分场景模式B或C就足够了。
6. 代码实战:用 pi-mono 构建三层记忆系统
理论讲够了,动手写代码。我们按照”先痛后爽”的教学思路,三层递进:
6.1 基础版:手动管理的对话历史 + key-value 状态
不依赖任何记忆框架,纯手写,理解底层机制。
// memory-basic.ts — 基础版:手动记忆管理import { Agent } from"@mariozechner/pi-agent-core";import { getModel } from"@mariozechner/pi-ai";// ========== 第一层:短期记忆(手动 messages 数组)==========constmessages: Array<{ role: string; content: string }> = [];// ========== 第二层:中期记忆(Session State)==========constsessionState: Record<string, any> = {taskPhase: "idle",stepsCompleted: [],};// ========== 第三层:长期记忆(JSON 文件模拟)==========constlongTermMemory: Array<{ content: string; timestamp: string }> = [];// 模拟向量检索:简单的关键词匹配functionsearchMemory(query: string, topK = 3): string[] {const keywords = query.toLowerCase().split(/\s+/);const scored = longTermMemory .map((m) => {const matches = keywords.filter((kw) => m.content.toLowerCase().includes(kw) ).length;return { memory: m, score: matches }; }) .filter((m) => m.score > 0) .sort((a, b) => b.score - a.score) .slice(0, topK);return scored.map((s) => s.memory.content);}// 将长期记忆注入 system promptfunctionbuildSystemPrompt(): string {const baseInstruction = `你是一个编程助手。请用中文回答。`;const recentMemories = longTermMemory.slice(-5); // 最近5条if (recentMemories.length === 0) return baseInstruction;const memorySection = recentMemories .map((m) =>`- ${m.content}`) .join("\n");return`${baseInstruction}关于用户的已知信息:${memorySection}当前任务状态:${sessionState.taskPhase}已完成步骤:${sessionState.stepsCompleted.join(", ") || "无"}`;}// 模拟对话循环asyncfunctionchat(userInput: string): Promise<string> {// 1. 构建当前 prompt(含长期记忆)const systemPrompt = buildSystemPrompt();// 2. 组装 messages(短期记忆) messages.push({ role: "user", content: userInput });const agent = newAgent({name: "memory-basic",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: systemPrompt, });// 3. 调用 Agentlet response = "";const stream = agent.stream(userInput);forawait (const event of stream) {if (event.type === "text") response += event.text; }// 4. 保存到短期记忆 messages.push({ role: "assistant", content: response });// 5. 简单的规则驱动记忆提取extractMemory(userInput, response);return response;}// 规则驱动的记忆提取functionextractMemory(userInput: string, response: string): void {construles: Array<{ pattern: RegExp; template: string }> = [ {pattern: /我叫(\S+)|我的名字是(\S+)/,template: "用户名字:{match}", }, {pattern: /我用(.*?)系统|我的系统是(\S+)/,template: "用户操作系统:{match}", }, {pattern: /我喜欢(.*?)风格|偏好(.*)/,template: "用户偏好:{match}", }, ];for (const rule of rules) {const match = userInput.match(rule.pattern);if (match) {const value = match[1] || match[2] || match[0]; longTermMemory.push({content: rule.template.replace("{match}", value),timestamp: newDate().toISOString(), });console.log(`[记忆写入] ${rule.template.replace("{match}", value)}`); } }}// ========== 测试 ==========asyncfunctionmain() {console.log("=== 基础版记忆系统测试 ===\n");// 第一轮:介绍自己let reply = awaitchat("你好,我叫Jack,我用macOS");console.log(`用户: 你好,我叫Jack,我用macOS`);console.log(`Agent: ${reply}\n`);// 第二轮:新会话模拟(清空短期记忆) messages.length = 0;console.log("--- 新会话开始(短期记忆已清空)---\n"); reply = awaitchat("帮我写一个文件读取函数");console.log(`用户: 帮我写一个文件读取函数`);console.log(`Agent: ${reply}\n`);console.log("--- 长期记忆内容 ---");console.log(JSON.stringify(longTermMemory, null, 2));}main().catch(console.error);运行结果预期:
=== 基础版记忆系统测试 ===用户: 你好,我叫Jack,我用macOS[记忆写入] 用户名字:Jack[记忆写入] 用户操作系统:macOSAgent: 你好Jack!很高兴认识你。macOS是个很棒的开发环境...--- 新会话开始(短期记忆已清空)---用户: 帮我写一个文件读取函数Agent: 好的,Jack!基于你的macOS环境,我建议...--- 长期记忆内容 ---[ { "content": "用户名字:Jack", "timestamp": "..." }, { "content": "用户操作系统:macOS", "timestamp": "..." }]关键观察: 即使短期记忆被清空(模拟新会话),长期记忆中的 “用户名字:Jack” 和 “用户操作系统:macOS” 仍然被注入了 system prompt,所以 Agent 仍然”认识”用户。
但基础版的问题很明显:记忆提取是规则驱动的,只能捕获明确说出的信息;检索是关键词匹配的,语义理解能力为零。下面进阶。
6.2 进阶版:带摘要压缩的短期记忆 + 文件持久化的长期记忆
// memory-advanced.ts — 进阶版:摘要压缩 + 文件持久化 + LLM提取import { Agent } from"@mariozechner/pi-agent-core";import { getModel } from"@mariozechner/pi-ai";import { readFileSync, writeFileSync, existsSync, mkdirSync,} from"fs";import { join } from"path";constMEMORY_DIR = "./memory";// ========== 短期记忆:带摘要压缩 ==========interfaceConversationMemory {messages: Array<{ role: string; content: string }>;summary: string;maxRoundsBeforeSummarize: number; // 触发摘要的轮数阈值}constshortTerm: ConversationMemory = {messages: [],summary: "",maxRoundsBeforeSummarize: 5,};// 摘要压缩:用 LLM 压缩旧对话asyncfunctionsummarizeOldMessages(): Promise<string> {if (shortTerm.messages.length === 0) return shortTerm.summary;const summarizer = newAgent({name: "summarizer",model: getModel("minimax-cn", "MiniMax-M2.7"), // 用便宜模型做摘要instruction: `将以下对话历史压缩为一段简洁的摘要(200字以内)。保留关键事实、决策和偏好信息。忽略寒暄和重复内容。当前已有摘要:${shortTerm.summary}对话内容:`, });const conversationText = shortTerm.messages .map((m) =>`${m.role}: ${m.content}`) .join("\n");let summary = "";const stream = summarizer.stream(conversationText);forawait (const event of stream) {if (event.type === "text") summary += event.text; }return summary;}// ========== 长期记忆:文件持久化 + LLM提取 ==========interfaceMemoryEntry {id: string;type: "semantic" | "episodic" | "procedural";content: string;timestamp: string;accessCount: number;}classLongTermMemoryStore {privatefilePath: string;constructor(userId: string) {const dir = join(MEMORY_DIR, "longterm");if (!existsSync(dir)) mkdirSync(dir, { recursive: true });this.filePath = join(dir, `${userId}.json`); }privateload(): MemoryEntry[] {if (!existsSync(this.filePath)) return [];returnJSON.parse(readFileSync(this.filePath, "utf-8")); }privatesave(entries: MemoryEntry[]): void {writeFileSync(this.filePath, JSON.stringify(entries, null, 2)); }// 写入记忆add(entry: Omit<MemoryEntry, "id" | "timestamp" | "accessCount">): void {const entries = this.load();// 去重:检查是否已有相似记忆const isDuplicate = entries.some((e) => e.type === entry.type && e.content.toLowerCase() === entry.content.toLowerCase() );if (isDuplicate) return; entries.push({ ...entry,id: `mem_${Date.now()}`,timestamp: newDate().toISOString(),accessCount: 0, });this.save(entries);console.log(`[长期记忆写入] [${entry.type}] ${entry.content}`); }// 检索记忆(简单语义匹配)search(query: string, topK = 5): MemoryEntry[] {const entries = this.load();const queryLower = query.toLowerCase();const queryWords = queryLower.split(/\s+/);const scored = entries .map((entry) => {const contentLower = entry.content.toLowerCase();const wordMatches = queryWords.filter((w) => w.length > 1 && contentLower.includes(w) ).length;// 时间衰减:越新权重越高const ageInDays = (Date.now() - newDate(entry.timestamp).getTime()) / (1000 * 60 * 60 * 24);const timeDecay = Math.exp(-ageInDays / 30); // 30天半衰期const score = wordMatches * 0.7 + timeDecay * 0.3;return { entry, score }; }) .filter((s) => s.score > 0) .sort((a, b) => b.score - a.score) .slice(0, topK);// 更新访问计数if (scored.length > 0) {const all = this.load();for (const s of scored) {const entry = all.find((e) => e.id === s.entry.id);if (entry) entry.accessCount++; }this.save(all); }return scored.map((s) => s.entry); }// 解决矛盾:覆盖同类旧记忆resolveConflict(newContent: string, type: MemoryEntry["type"]): void {const entries = this.load();// 找到同类型的矛盾记忆(简单实现:同类型 + 关键词重叠)const keywords = newContent.toLowerCase().split(/\s+/);const conflicting = entries.filter((e) => e.type === type && keywords.some((kw) => kw.length > 2 && e.content.toLowerCase().includes(kw) ) );// 删除旧矛盾记忆const remaining = entries.filter((e) => !conflicting.includes(e)); remaining.push({id: `mem_${Date.now()}`,type,content: newContent,timestamp: newDate().toISOString(),accessCount: 0, });this.save(remaining);if (conflicting.length > 0) {console.log(`[记忆更新] 解决矛盾:${conflicting.length}条旧记忆被新记忆替代` ); } }}// LLM 驱动的记忆提取asyncfunctionextractMemoriesWithLLM(userMessage: string,assistantReply: string,store: LongTermMemoryStore): Promise<void> {const extractor = newAgent({name: "memory-extractor",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: `分析以下对话,提取值得长期记住的信息。按类型分类输出 JSON:- "semantic": 用户的事实信息(姓名、偏好、技术栈、环境)- "episodic": 经验教训(什么做法有效/无效、遇到的坑)- "procedural": 行为规则(Agent应该遵循的规则)如果没有值得记住的信息,返回空数组 []。只输出 JSON,不要解释。`, });const dialog = `用户: ${userMessage}\n助手: ${assistantReply}`;let result = "";const stream = extractor.stream(dialog);forawait (const event of stream) {if (event.type === "text") result += event.text; }try {constextracted: Array<{ type: string; content: string }> =JSON.parse(result);for (const item of extracted) {if (["semantic", "episodic", "procedural"].includes(item.type)) {// 尝试解决矛盾 store.resolveConflict(item.content, item.typeasMemoryEntry["type"]); store.add({type: item.typeasMemoryEntry["type"],content: item.content, }); } } } catch {// LLM 输出格式异常时静默跳过console.log("[记忆提取] 格式异常,跳过本次提取"); }}// ========== 完整对话流程 ==========const ltmStore = newLongTermMemoryStore("user_jack");asyncfunctionchatAdvanced(userInput: string): Promise<string> {// 1. 检索相关长期记忆const relevantMemories = ltmStore.search(userInput);const memoryContext = relevantMemories.length > 0 ? `关于用户的已知信息:\n${relevantMemories.map((m) => `- [${m.type}] ${m.content}`).join("\n")}` : "";// 2. 构建 system prompt(摘要 + 长期记忆)const systemPrompt = `你是一个编程助手。请用中文回答。${shortTerm.summary ? `之前的对话摘要:${shortTerm.summary}\n` : ""}${memoryContext}`;// 3. 调用 Agent shortTerm.messages.push({ role: "user", content: userInput });const agent = newAgent({name: "memory-advanced",model: getModel("minimax-cn", "MiniMax-M2.7"),instruction: systemPrompt, });let response = "";const stream = agent.stream(userInput);forawait (const event of stream) {if (event.type === "text") response += event.text; } shortTerm.messages.push({ role: "assistant", content: response });// 4. LLM 驱动的记忆提取awaitextractMemoriesWithLLM(userInput, response, ltmStore);// 5. 检查是否需要摘要压缩if ( shortTerm.messages.length >= shortTerm.maxRoundsBeforeSummarize * 2 ) { shortTerm.summary = awaitsummarizeOldMessages();// 只保留最近 3 轮 shortTerm.messages = shortTerm.messages.slice(-6);console.log("[短期记忆] 已完成摘要压缩,保留最近3轮"); }return response;}关键变化(对比基础版):
-
• 短期记忆:多了摘要压缩机制,超过5轮自动压缩旧对话 -
• 长期记忆:文件持久化(重启不丢失)、三种类型分类存储、时间衰减排序、访问计数 -
• 记忆提取:从规则驱动升级为 LLM 驱动,能捕捉隐含信息 -
• 矛盾处理:写入前检测同类旧记忆,自动覆盖
6.3 生产版要点
生产环境中还需要考虑:
// 生产版需要额外处理的问题:// 1. 向量数据库替代关键词匹配// 使用 Pinecone / Weaviate / Chroma 实现真正的语义检索// import { ChromaClient } from "chromadb";// const collection = await chroma.getOrCreateCollection("memories");// await collection.add({ ids, embeddings, documents });// 2. 异步记忆提取(不阻塞对话响应)// 先给用户返回响应,后台异步提取记忆// async function backgroundExtract(dialog: string) { ... }// 3. 记忆容量管理// 定期归档 accessCount < 阈值 且 age > 90天的记忆// function archiveOldMemories() { ... }// 4. 多用户隔离// 每个用户独立的记忆空间,互不干扰// const store = new LongTermMemoryStore(userId);// 5. 隐私过滤// 检测并过滤敏感信息(密码、信用卡号、身份证号)// function sanitizeBeforeStore(content: string): string { ... }📎 完整代码:
code/L10-memory-system.ts
7. 要点总结
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8. 动手练习
练习 1: 基础 (⭐)
基于 6.1 的基础版代码,为 extractMemory 函数添加以下规则:
-
• 检测到技术相关词汇(如 “Python”, “TypeScript”, “React”)→ 记录为用户技术栈 -
• 检测到否定偏好(”不要XXX”, “别用XXX”)→ 记录为 negative_preference
练习 2: 进阶 (⭐⭐)
基于 6.2 的进阶版代码,实现”记忆衰减”功能:
-
• 每条记忆带 halfLife字段(语义记忆=永久,情节记忆=30天,程序记忆=90天) -
• 检索时计算 有效分 = 相似度 × 2^(-年龄/半衰期) -
• 超过 3 个半衰期且 accessCount < 2 的记忆自动归档
练习 3: 挑战 (⭐⭐⭐)
实现一个完整的”程序记忆自优化”循环:
-
1. Agent 用当前规则集处理 5 个任务 -
2. 收集执行结果和用户反馈 -
3. 用 LLM 反思:哪些规则有效?哪些需要修改?应该新增什么规则? -
4. 自动更新规则集并存回长期记忆 -
5. 下一轮对话使用更新后的规则
提示:这需要结合 L07(Reflection)模式的思路,让 Agent 能够审视和修改自己的行为指令。
9. 延伸阅读
-
• 🔗 Lost in the Middle[1] — LLM 长上下文信息提取的研究 -
• 🔗 LangGraph Memory[2] — LangGraph 的记忆实现参考 -
• 🔗 Google ADK Memory[3] — ADK 的 Session/State/Memory 三组件设计 -
• 🔗 pi-mono 文档: AgentState 和 transformContext() API
引用链接
[1] Lost in the Middle: https://arxiv.org/abs/2307.03172[2] LangGraph Memory: https://langchain-ai.github.io/langgraph/concepts/memory/[3] Google ADK Memory: https://google.github.io/adk-docs/sessions/memory/