 夜雨聆风
夜雨聆风





面试被问“你怎么用AI进行软件测试提效的“,怎么答才有说服力?
“你平时是怎么用AI进行软件测试提效的?”
这个问题现在几乎出现在每一场测试工程师/测试开发工程师的面试里。问得多了,答的人也多了,但能让人眼前一亮的回答,十个里面可能挑不出一个。
大多数人的回答听起来像是产品介绍:“我用了ChatGPT帮我写用例,效果还不错。”
然后就没有然后了。
面试官内心:所以呢?你到底干了什么?提升了什么?有什么可量化的成果?
不是大家不努力,是真没意识到:AI提效是个结果,不是个概念。你能说出”我通过AI把某个环节从X小时压缩到Y分钟”和只会说”AI帮我提效了”,在面试里是完全不同的两个世界。
这篇文章不讲大道理,就教你一招:怎么把AI提效这件事说得有血有肉、有数据有方法,让面试官感受到你确实在用AI真实解决问题,而不是在背产品手册。
为什么大多数回答没有说服力
先说说我见过最多的几种”无效回答”:
第一种:泛泛而谈型
“我用AI辅助测试工作,效果还不错。”
这话说了等于没说。”还不错”是多不错?用在什么场景?解决了什么问题?面试官听不出任何有价值的信息。
第二种:堆砌工具型
“我用过ChatGPT、Copilot、Kimi、文心一言好几个AI工具。”
工具罗列不等于能力体现。就好像说”我用过Word、Excel、PPT”不代表你就会办公自动化一样。面试官关心的是你怎么用,不是你用过什么。
第三种:没有数据型
“AI帮我写测试用例快多了,效率提升很明显。”
多快?原来多久现在多久?覆盖率有变化吗?维护成本降低了吗?没有数字的”提升”都是空话。
第四种:只有感受型
“通过AI提效项目,我学到了很多新技能,对AI的应用有了更深的理解。”
过程收获不等于工作成果。面试官想听的是你做出了什么,不是你学到了什么。
第五种:只讲概念型
“我们团队在探索AI与测试的结合,目前取得了一些进展。”
“一些进展”是什么进展?你在里面承担什么角色?落地了什么功能?
面试官真正想听的是什么?
是具体的场景、真实的方法、可量化的数据、能复制的经验。说白了,就是要看到你的思考和实践,而不只是你”知道有AI这东西”。
回答框架:三层递进法
好了,说完问题说方法。我总结了一个三层递进法,帮你把AI提效的回答结构化:
第一层:场景层 — 什么场景?遇到了什么具体问题?以前怎么做的?第二层:方法层 — 用了什么AI能力?怎么用的?人机如何协作?第三层:效果层 — 效率提升了多少?质量有什么变化?沉淀了什么方法论?
每一层都要有具体内容,不能含糊。
这个框架的核心逻辑是:先让面试官理解问题的背景和价值(场景),再展示你的技术思路和实操细节(方法),最后用数据证明你的成果(效果)。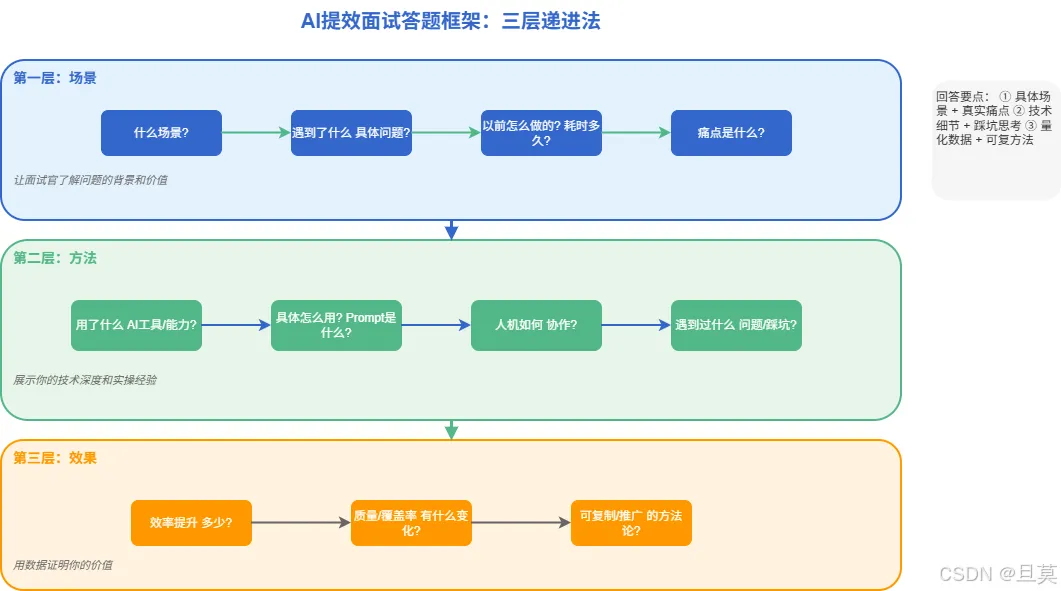
为什么要分三层?
因为三层对应了面试官评估AI应用能力的三个维度:
- 场景判断力
:你能不能找到真正适合AI介入的场景,而不是为了用AI而用AI - 技术落地力
:你能不能把AI用起来、用好,而不是浅尝辄止 - 结果证明力
:你能不能量化你的成果,而不是自说自话
三个维度都到位了,面试官自然会对你刮目相看。
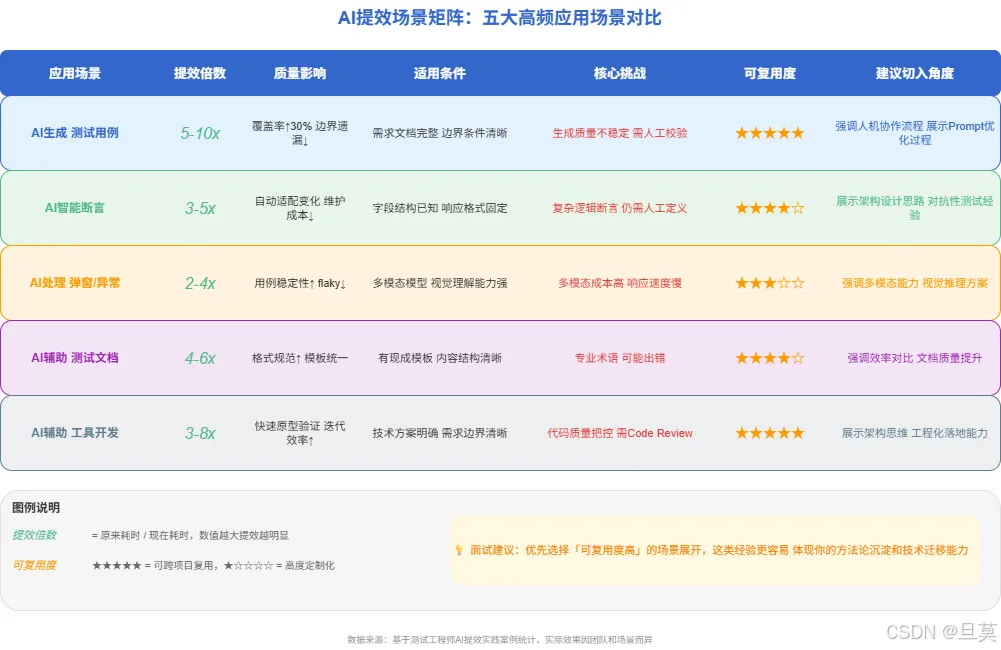
5个高频场景的高分回答
下面我结合真实经验(已脱敏),给出5个高频场景的具体回答示例。每个场景都包含:问题→思路→具体做法→量化效果。
场景一:AI生成测试用例
问题背景
每次需求迭代,测试用例补充是最大的工作量瓶颈。拿一个功能模块的回归测试来说,需求变更后手工补充用例要2天时间,而且边界条件容易遗漏。
回答思路
不要简单说”用AI生成用例”,要说明白你的人机协作流程。AI生成是起点,人工校验和优化才是关键。
具体做法
我的做法是分三步走:
第一步:需求分析。把产品需求文档整理成结构化的输入,提取功能点、输入输出、边界条件。
第二步:AI生成初稿。用Prompt引导AI生成测试用例。我的核心Prompt模板是:
请为以下功能模块生成测试用例:## 功能描述[粘贴需求描述]## 输入输出- 输入:- 输出:## 测试要求1. 生成用例需包含:用例ID、测试步骤、预期结果2. 覆盖正常流程、边界条件、异常流程3. 每条用例标注优先级(P0/P1/P2)4. 用例格式:Markdown表格
第三步:人工校验。重点检查三点:业务逻辑是否正确、边界条件是否完整、优先级是否合理。
量化效果
-
用例补充时间:从2天缩短到2小时,提效6倍 -
用例覆盖率:从72%提升到91%,覆盖率提升19% -
边界条件遗漏率:从28%降到9%,遗漏率降低67%
场景二:AI辅助断言
问题背景
接口测试里,响应结构的断言一直是个痛点。字段多了断言代码冗长,字段少了漏掉校验。更麻烦的是,当接口返回结构变化时(比如新增字段、字段顺序调整),旧断言不会自动适配,导致大量用例维护工作。
回答思路
展示你的架构设计思维,说明AI不是帮你写断言,而是帮你构建更智能的断言体系。
具体做法
我设计了一套”AI+规则”的智能断言方案:
# 核心断言逻辑(已脱敏)class SmartAssertion:def __init__(self, expected_schema):self.expected_schema = expected_schemaself.ai_validator = AIVulnerabilityDetector()def assert_response(self, response_data):"""智能断言主流程"""# 基础结构校验self._validate_structure(response_data)# AI辅助字段变化检测changes = self._detect_field_changes(response_data)if changes:# 智能判断:是缺陷还是正常迭代verdict = self.ai_validator.judge_change_type(changes)if verdict.is_defect:raise AssertionError(f"检测到缺陷: {verdict.description}")else:# 自动更新预期,标记需要人工确认self._flag_for_review(changes)# 业务规则校验self._validate_business_rules(response_data)
核心思路是:AI负责识别”变化”,规则负责判断”对错”。当响应结构变化时,AI先判断这是缺陷还是正常迭代,再决定是报错还是标记人工确认。
量化效果
-
断言代码维护量:减少70%(结构变化时自动适配) -
漏检率:从8%降到2%(AI能识别传统规则难以覆盖的异常模式) -
用例稳定性:Flaky用例减少60%
场景三:AI处理弹窗和异常
问题背景
做UI自动化测试,最头疼的就是各种弹窗和异常场景。升级提示框、网络不稳定弹窗、实名认证弹窗……这些随机出现的弹窗会导致用例失败,而且很难穷举处理。
回答思路
展示你对多模态AI能力的理解,说明在什么场景下多模态比传统方案更有效。
具体做法
针对弹窗问题,我设计了一套基于多模态大模型的”感知-决策-执行”架构:
感知层:截图 → 多模态模型识别弹窗类型↓决策层:识别结果 → 匹配预设处理策略↓执行层:执行对应操作(如点击"关闭"、"稍后"等)
实际落地的Prompt示例:
请分析这张截图中的UI元素:1. 是否存在弹窗/提示框?2. 如果存在,识别弹窗类型(升级提示/网络异常/实名认证/广告等)3. 判断应该如何处理:- 点击"关闭"或"以后再说"按钮- 点击"确定"按钮- 等待倒计时后重试- 截图记录后跳过请输出:{"has_popup": true/false, "type": "xxx", "action": "xxx", "confidence": 0.x}
量化效果
-
用例稳定性:弹窗相关失败从每天30+次降到5次以内,减少83% -
用例可复用性:一个弹窗处理逻辑可以复用多个场景 -
维护成本:新弹窗类型只需补充识别策略,无需改核心代码
场景四:AI辅助测试文档
问题背景
测试文档是个”良心活”,写好写坏没人管,但归档和追溯时又必须要有。手工写一份测试方案要4小时,而且格式不统一、模板不规范,每次新人来都要重新培训文档规范。
回答思路
这是一个”AI提效效果最明显”的场景,因为文档写作有明确的格式规范,AI可以很好地辅助生成初稿。
具体做法
我的做法是先搭框架,再填内容:
框架生成(AI完成):
请为以下功能生成测试方案文档:## 功能信息- 功能名称:XXX- 测试类型:功能测试/接口测试/UI测试- 复杂度:高/中/低## 输出要求文档包含以下章节:1. 测试概述2. 测试范围3. 测试策略4. 测试用例设计5. 风险评估6. 测试进度安排格式要求:Markdown,使用规范标题层级,包含表格和列表
内容填充(AI+人工):框架出来后,我会在每个章节填入具体内容,AI负责生成模板化的描述语言,我负责填入技术细节。
量化效果
-
文档编写时间:从4小时压缩到40分钟,提效6倍 -
格式规范度:100%符合团队模板(AI自动遵循格式要求) -
新人上手时间:文档规范培训从2小时降到20分钟
场景五:AI辅助工具开发
问题背景
作为测试开发,我们经常需要写一些小工具提升团队效率。以前做一个工具,从设计到实现再到调试,要一周时间,很多好的想法因为开发成本太高而被搁置。
回答思路
展示你的工程化思维,说明AI如何帮助加速原型验证,以及如何保证代码质量。
具体做法
我的工作流是:
第一阶段:AI辅助设计。让AI帮我分析需求,输出技术方案和伪代码,确认思路后再动手。
第二阶段:AI辅助编码。用AI生成基础代码框架,然后自己填充核心业务逻辑。关键是要知道问AI什么、怎么用AI的输出。
第三阶段:AI辅助调试。遇到报错或异常行为,先让AI帮忙分析可能的原因,再定位具体问题。
一个实际案例是AI辅助日志分析工具:
# 核心功能:智能日志解析(已脱敏简化)def parse_error_logs(log_content: str) -> ErrorReport:"""解析错误日志,生成分析报告"""# AI辅助日志分类error_types = classify_errors(log_content)# AI辅助根因分析root_causes = analyze_root_causes(error_types)# AI辅助处理建议suggestions = generate_suggestions(root_causes)return ErrorReport(error_count=len(error_types),critical_errors=count_critical(error_types),root_causes=root_causes,suggestions=suggestions)
整个工具从需求到上线只用了3天,而以前同等复杂度的工具至少要一周。
量化效果
-
开发周期:平均缩短50%(原型验证效率大幅提升) -
代码质量:AI生成的代码经过Code Review后,缺陷密度与传统开发相当 -
功能产出:季度工具产出从3个提升到8个
进阶加分项:主动暴露局限和思考
上面五个场景是”标准答案”,能让你拿到基础分。但如果你想拿高分,还需要展示一点:你对AI的局限性有清醒的认识。
主动暴露局限不是示弱,而是展示你真正用过AI、用出问题过、思考过。
什么场景AI不适合?
业务逻辑复杂、依赖上下文理解的场景
比如涉及多系统交互的集成测试,AI很难理解业务背景和隐含规则。这种场景让AI硬上是添乱。
需要强一致性和可重复性的场景
AI输出有随机性,同一个Prompt两次运行结果可能不同。对于需要严格可重复的测试用例,这反而是负担。
涉及安全合规的场景
敏感数据处理、合规性验证等,AI的表现不一定符合企业安全要求,这类场景要慎用。
你踩过的坑是什么?
比如我踩过的一个坑:
早期用AI生成测试用例,贪图快,直接用AI生成的用例跑自动化。结果发现AI有时候会把边界条件搞错,比如把”金额>0″理解成”金额>=0″,导致用例本身就有问题。
后来我调整了策略:AI生成、人工校验、关键用例人工补充,形成完整的质量门禁。
主动说这个,面试官会觉得你用过心、踩过坑、有成长。
你对AI辅助测试的思考是什么?
可以适当展开你的方法论思考:
我的理解是,AI不会替代测试工程师,但会用AI的测试工程师会替代不会用的。核心是把AI定位成”提效工具”而不是”能力替代”,人负责判断和决策,AI负责执行和生成。
这样的思考会让你和其他候选人拉开差距。
哪些不适合说
最后列个清单,以下几点千万注意:
1. 不要说”AI帮我提效了”就结束
没有场景、没有数据、没有细节,这句话等于没说。
2. 不要过度吹嘘AI的能力
“AI生成用例准确率100%”这种话一出口,面试官就知道你没见过世面。AI确实会犯错,这是共识,不如坦诚。
3. 不要只说工具不说方法
“我用了ChatGPT、Copilot”不是答案,”我怎么用它们解决了什么问题”才是。
4. 不要回避AI的局限性
越是想掩盖,越显得心虚。主动说反而加分。
5. 不要把别人的成果说成自己的
团队项目说成个人项目,AI的功劳全往自己身上揽。面试官一深挖就露馅,得不偿失。
6. 不要只讲概念不讲落地
“我们探索了AI在测试领域的应用”这种话太虚,要有具体的功能、具体的场景、具体的产出。
总结
回到最初的问题:面试被问”你怎么用AI提效”,怎么答才有说服力?
核心就一句话:把AI提效当成一个工程项目来描述,而不是当成一个时髦概念来炫耀。
具体来说:
- 讲场景
:什么情况下想到用AI,解决了什么问题 - 讲方法
:怎么用的,人机如何协作,有没有技术细节 - 讲数据
:效率提升了多少,质量改善了什么,有没有可量化指标 - 讲反思
:踩过什么坑,AI的局限在哪里,你怎么改进的
做到了这四点,你的回答就已经超越了90%的竞争者。