 夜雨聆风
夜雨聆风





一文带你学透词嵌入Word Embedding
学习大模型时总是会遇到“词嵌入”,到底什么是词嵌入呢?本文带你揭秘。
01
词嵌入定义
词嵌入(Word Embedding):
自然语言处理是一种(NLP)中,将高维数据(如文本或图像)转换为较低维度的向量表示的技术。
人话版:
文本本身是离散孤立的符号,大模型无法对它做数学运算。
就像我们没法算出「cat + man」等于什么,模型也完全没有概念。
所以必须把文字,转换成可计算、可度量的向量格式。
02
词嵌入有啥用?

将高维且稀疏的单词索引转化为低维且连续的向量:
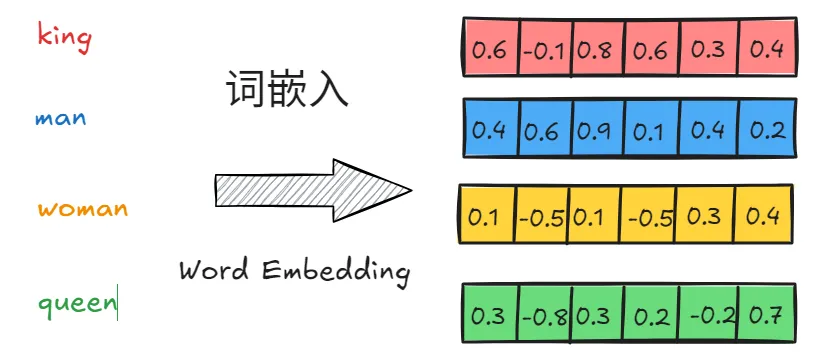
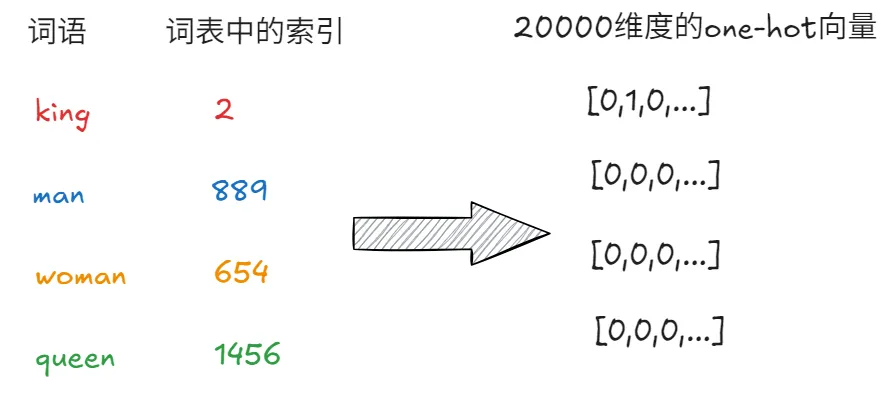
假设词汇表中有20000个单词,此时表示下图的4个词就需要4个20000维度的one-hot向量。
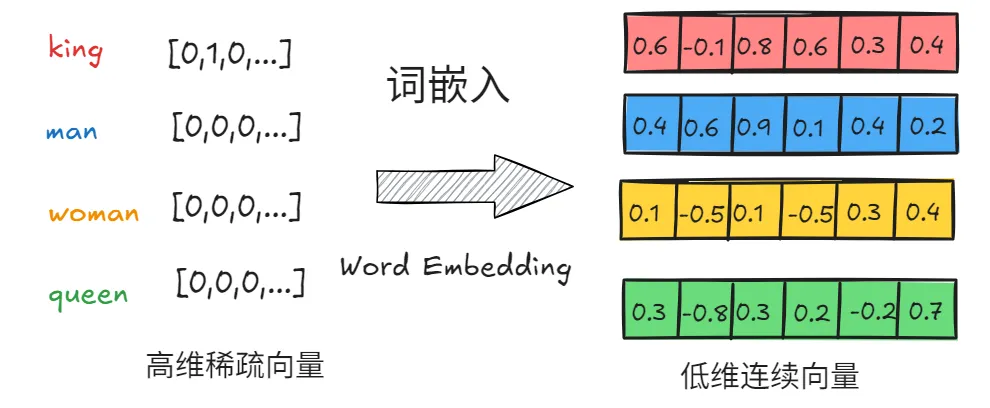
通过词嵌入技术可以把20000维度的one-hot向量在转化为低维连续向量。此时将每个单词映射到一个6维的空间中。

体现单词与单词之间的语义关系:
通过PCA降维算法将6维向量降到2维,在平面空间绘制如下,可以发现语义相近的词语距离更近。
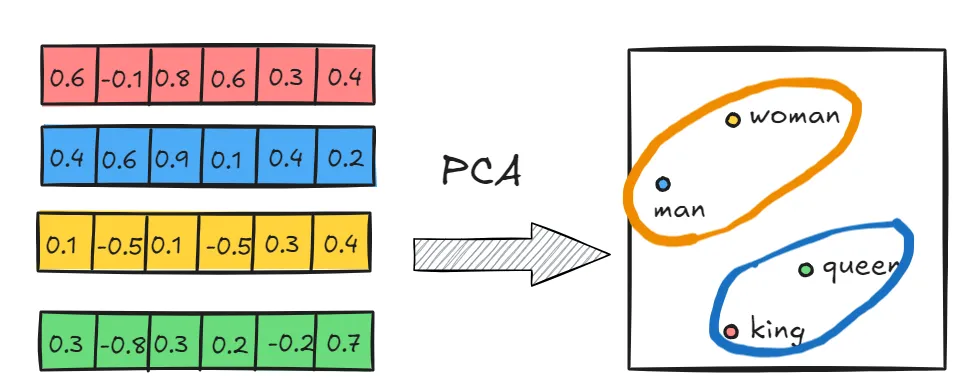

体现单词与单词之间的语义关系:
我们还可以发现「向量king – 向量queen」≈ 「向量man – 向量woman」。即可以通过词向量的数学关系来描述词语之间的语义关系。

03
如何实现词嵌入?
通过特定的词嵌入算法,如word2vec、fasttext、Glove等可以实现词嵌入。
这些算法的本质都是用海量语料库训练一个神经网络模型,从而得到嵌入矩阵。一旦训练完成,这个嵌入矩阵就可以应用于任何NLP任务中。
其中,嵌入矩阵的行是语料库的大小,下图嵌入矩阵表示对于5000个词语,每个用128维矩阵表示。
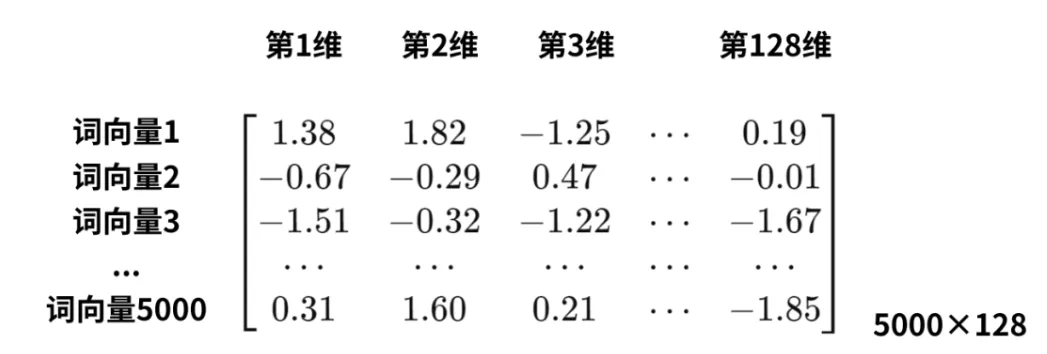
嵌入矩阵怎么用?
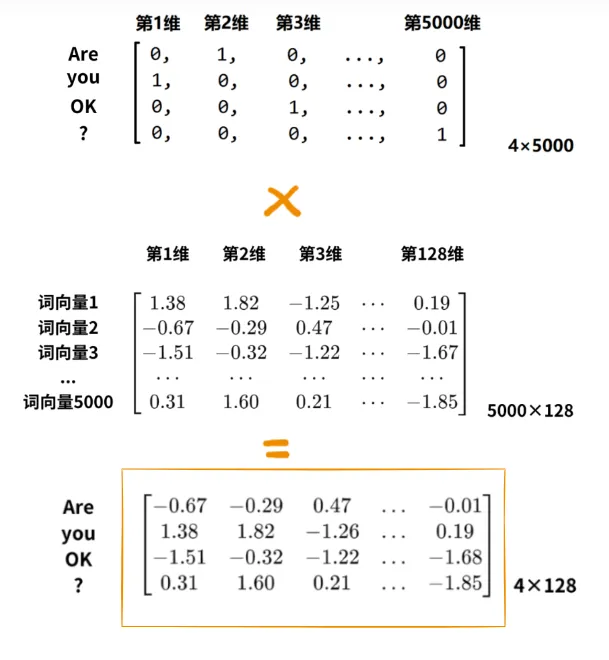
方式一:基于矩阵相乘
假如要对「Are you OK ?」进行词嵌入,则现将其基于词表的one-hot编码得到4*5000的矩阵,然后与嵌入矩阵相乘即可得到对应的嵌入向量(橙色方框的内容)。
方式二:基于索引查找
以「Are you OK ?」在词表中的ID作为索引,在嵌入矩阵查找即可,得到的嵌入向量与方式一是一致的。
04
词嵌入代码实现
下面代码利用 torchtext.vocab中的GloVe实现了词嵌入。
构建嵌入层:
构建GloVe

使用nn.Embedding创建词嵌入层

获取单词索引形式:

根据单词的索引获得词向量:

【@好好学AI笔记】【郝同学】