 夜雨聆风
夜雨聆风





踩坑前想清楚:为什么要本地部署 OpenClaw(2)
在(1)中,我们提出了本地化部署有A、B两种方式,主要通过拆解A方案,来说明A与B有着本质的不同。
A- 本地安装OpenClaw+使用云端的大模型
B- 本地安装OpenClaw+本地部署大模型
所以,你应该能鉴别出这种绿茶:所谓的本地部署OpenClaw不等于”数据与文件不出本地”。关键看大模型是否本地化。
由于你不仅谨慎,还很细节控…
这篇我们继续——对比本地化部署的A方案 vs 全云端版OpenClaw 的不同:(费用可忽略)
- 安装难度:⭐⭐⭐⭐(足以劝退全小白)——本文最后梳理下其他方案
- 数据隐私:与全云端使用没有多少差异——优先详细比对下差异
- 本机文件:可访问、可处理——两种方案都可以实现

依旧请出我们不太完美的图:
这次我们假设企业的业务数据在本地(如果在企业自有云环境下,可以替换为该环境),你此刻急需大模型基于内部数据表来帮你分析一个业务问题。
过程我就不讲了,请自行”看图说话“。
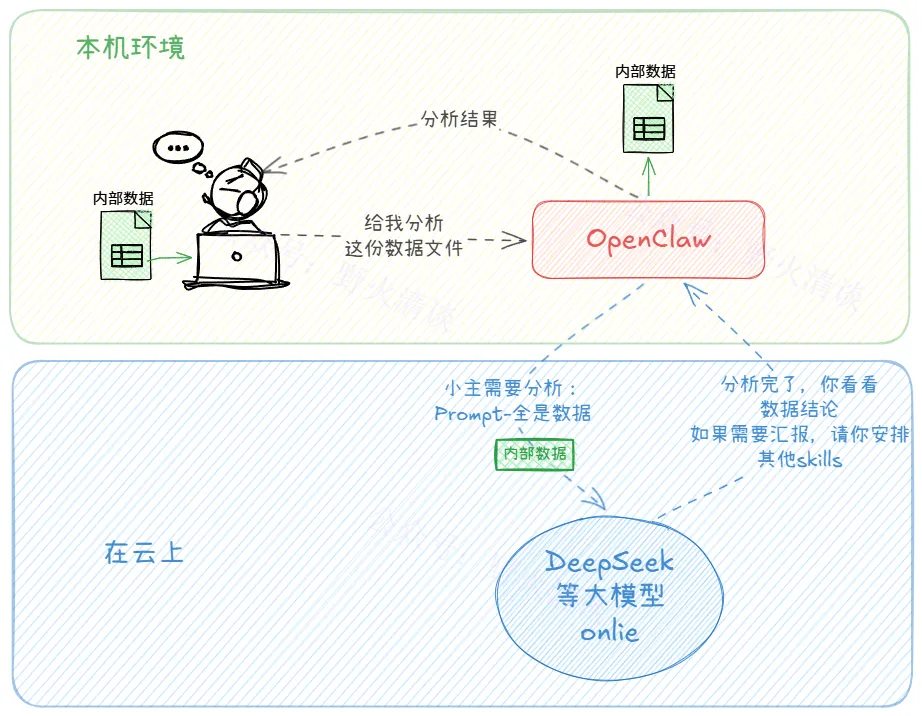
本地 OpenClaw + 云端模型不直接转移文件,只把 AI 分析所需的最小必要上下文发送给模型;全云方案则需将完整文件上传至第三方服务器。
两者模型都能”看到内容”,但数据暴露面不同。
|
对比项 |
本地 OpenCl+云端大模型 |
全云端方案 |
|
原文件 |
留你电脑 |
将上传云端 |
|
OpenClaw发出去给online大模型 |
可能只需要发文字片段(Prompt) |
完整文件到OpenClaw所在云 |
|
模型看见 |
文字片段 |
完整内容or部分内容 |
|
结束后 |
只剩聊天记录 |
文件留云端 |
|
你的控制权 |
管住发啥内容 |
管住传啥文件 |
但是我的观点,你也不知道是否能够严格理解每次任务所涉及到的数据范围,因此部分内容也不知道是哪部分。依旧需要企业从合规角度进行全套的管理设计。
我们一直试图在探究的是,如果不看安装环节的困难,A方案-OpenClaw本地化+大模型云端和完全云端的方案差异并不大。
如果你/企业确实有下面四项中某一项的需求:
- 数据隐私:数据不外流,本地存储更安全
- 成本更低:免去云端订阅、模型调用费用
- 自主可控:自由配置模型、权限、功能,支持二次改造
- 离线可用:内网 / 无公网环境也能运行
那恭喜你,你要认真考虑方案B—OpenClaw本地化+大模型本地部署了。

最后列举下安装起来不费劲的OpenClaw方案:
|
产品 |
和OpenClaw的关系 |
|
网易有道龙虾LobsterAI |
基于OpenClaw框架封装改良 |
|
腾讯云 Lighthouse OpenClaw 模板 |
在购买的云服务上部署-封装改良版龙虾 |
|
JVS Claw(阿里云无影) |
在购买的阿里云服务上部署-封装改良版龙虾 |
|
腾讯云WorkBuddy |
和OpenClaw部分近似,但其实没有血缘关系 |
作业: 翻查LobsterAI(有道龙虾)的官网及手册,判断其是否能做到完全本地化。需要怎么做?
这篇表格有点多~
下一篇,简短总结OpenClaw的坑吧,以及怎么找到指南针?

** 化繁为简 **
深度,基于核心基础
问题,是撬起AI的支点