 夜雨聆风
夜雨聆风





当AI开始“住进”文档工作流

2026年5月21日,tcworld China 2026 技术传播大会在上海苏宁环球万怡酒店正式开幕。
在“XX行业已死”的噪音满天飞的今天,技术传播的同行们聚在一起,认认真真聊了一件事:我们的职业,到底往哪走?
进会场前,小编看了一眼两天的议程,心想:嗯,又是一堆AI工具和实践展示吧。
出来之后小编承认,我错了。
这哪是工具展示,这是一场关于 “我们这群人以后到底干嘛” 的深度对话,正如大会主题“智聚同行,共解新局”描述的那样。
Day 1 的议题看起来有点散:欧盟生态设计法规、简化英语、AI智能体、开源文档、消费品文档……
但坐下来听完,有一条线串起了所有东西:文档工作者,正在从“内容生产者”变成“知识运营者”。而且这个转变,比小编想的快得多。
下面是小编觉得最值得记下来的几个片段。

一、AI 智能体在交付文档的探索
演讲者:薛静(中兴通讯,系统产品文档总监)

薛静的分享从AI互动趋势及传统文档交付的痛点出发。
她把 AI 互动趋势分成四类:
-
问答式(P1):最基础,类似 chat,人与AI在工作流外交互
-
沉浸式(P2):类似 copilot,人和 AI 在现有工作上交流,辅助人工完成任务
-
流程再造式(P3):类似 workspace,工作流基于 AI 编排构造
-
共生式(P4):端到端自动执行
ZTE 的实践是多智能体协同框架:Planner + Executors,覆盖规划、执行、质控、翻译、发布五个阶段。
最值得关注的是她提出的四个对抗幻觉的文档生成技术:
-
事实性校验智能体 (Fact-Checking Agent):生成与校验分离,检查每个关键内容的原始出处,进行交叉验证,确保有据可依。
-
上下文工程与引用闭环:强制模型“仅根据提供的上下文生成答案”,并精确标注信息来源,杜绝无中生有。
-
拒识机制:信息不足时主动拒绝回答,而非编造事实。全流程评测闭环:建立覆盖关键场景的自动化评测体系,通过海量样本持续测试,驱动模型与工程策略的迭代优化。
这和华为蒋诗玥的锚点策略有异曲同工之处——两个来自不同公司的演讲者,却都得出了相似的结论:AI 应用的核心挑战不是能力,而是可控性。
她还提到了文档范式的三阶段演进:
-
人工写作阶段
-
AI 辅助全流程编写
-
AI 驱动全流程编写
目前大多数团队处于第一到第二阶段的过渡期,第三阶段是方向,但需要解决可控性问题才能真正落地。

二、开源文档的 AI 共建实践
演讲者:樊雅清(华为,信息技术工程师)

这个分享的角度比较特别:不是”怎么用 AI 写文档”,而是“怎么搭一个让AI和人都能高效贡献的开源文档体系”。
华为的实践包括:
-
AI 辅助目录生成:根据实际存在的 Markdown 文件自动生成 _toc.yaml,同步标题,去除无效项
-
VS Code 插件 CANN-ASSIST:支持自动生成 API 参考文档,内置写作模板和格式要求
-
VS Code 插件 Doc Tools:实时格式检查、写作辅助、效果预览,实现”写、校、查”一体化
实际效果:写作时间减少 60%,提交 PR 前可发现问题,减少反复修改。
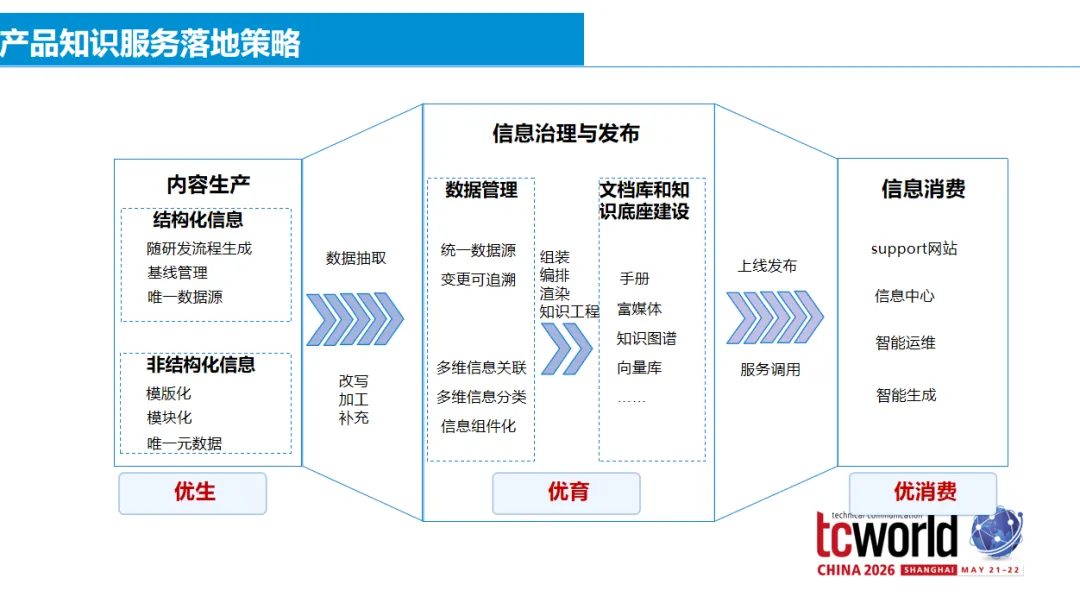
但让小编印象更深的是她对开源文档体系的整体设计思路:根据用户旅程(认知 → 初步使用 → 深入参与 → 贡献 → 布道)分层设计文档类型,每一层对应不同的用户需求和内容标准。
比如”认知阶段”需要的是 README、版本说明、架构白皮书;”初步使用”需要安装指南、用户指南、API 参考;”贡献阶段”需要贡献指南、代码规范、PR 模板……这个框架不只适用于开源项目,对任何面向开发者的文档体系都有参考价值。

三、幻觉不是玄学,是工程问题
演讲者:蒋诗玥(阿里云,技术内容工程师)

这个议题的标题是”从文档工程师到模型上下文工程师:降低 LLM 幻觉的方法探究”,听起来有点学术,但内容非常落地。
韩诗涵把文档领域的 LLM 幻觉分成四类:
-
事实捏造:生成不存在的参数、步骤
-
错误归因:把 A 产品的参数写到 B 产品
-
过度润色:内容听起来很好但与原文不符
-
逻辑不一致:前后矛盾
这些问题的根源不是模型”不够聪明”,而是缺乏现实锚点。
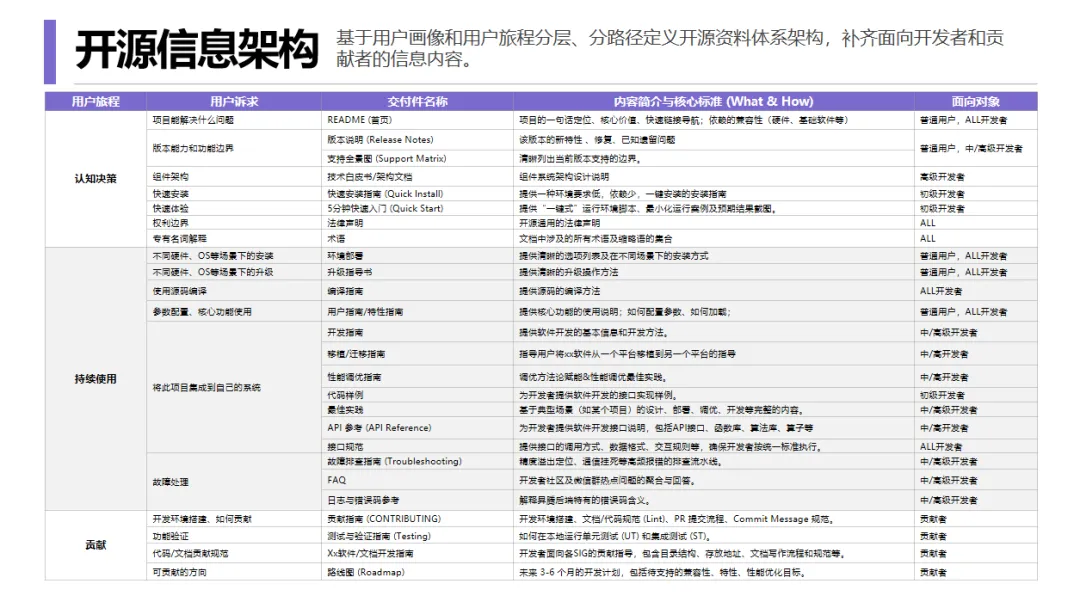
她提出的解法是锚点策略 + 硬约束,分三层:
-
知识层:构建AI-ready知识库,用Markdown + YAML frontmatter格式化,去噪去重,让模型有可靠的”现实锚点”可以引用。
-
生成层:锚点预处理 + 硬约束。核心是不让模型“记住”约束,而是让模型“调用”约束,绕不过去。用脚本强制执行每一个流程 。
-
模型层:领域微调 + 偏好训练(RLHF),针对特定文档类型优化模型行为。
她还分享了一个很实用的框架:不同类型的技术文档,需要不同的锚点来源:
-
操作类文档 → 界面截图、功能步骤、注意事项
-
参考类文档 → 参数数据库、产品素材
-
开发指南 → API 接口定义、代码
-
说明类文档 → 架构数据、PRD 文档
这个分类方式可以直接拿来用。
核心洞察:幻觉问题的本质是”模型在没有约束的情况下自由发挥”。解法不是更好的 Prompt,而是更严格的工程约束。


四、SmartBot:当文档从”信息传递”变成”任务辅助”
演讲者:Elsie Dong(西门子 SEWC 工厂,产品信息工程师)

Elsie一上来就扔了个让人扎心的数字:用户遇到一个问题,从翻文档、理解、尝试、试错,到最后搞定——平均要花30到65分钟。
这不是文档写得不好,而是文档的交付方式本身就有问题——用户需要的不是”信息”,而是”任务支持”。
西门子的产品文档体系有 6 类文档、2000 页内容,用户平均需要切换多个文档才能找到答案。脚本编程的学习门槛更高,光是熟悉 JavaScript 语法和项目对象模型就要 2 ~ 4 周。
西门子的解法是 SmartBot:一个深度嵌入产品文档体系的 AI 助手,由两个 Agent 协同工作:
-
知识库 Agent:快速定位信息、整合多文档内容、给出结构化答案,支持配置类、故障类、案例类问题(大白话翻译一下:这个 Agent 负责在知识库里快速定位、整合答案)
-
编程 Agent:解释代码、修复 bug、优化脚本,能自动识别控件名称、调用对象模型、生成碰撞检测算法(大白话翻译一下:这个 Agent 负责编程辅助:解释代码、修bug、自动生成脚本)
最让小编惊讶的是编程辅助的对比:传统方式要111行代码,SmartBot一句话描述需求就能生成。
但 Elsie 特别强调了一点,小编单独记下来:
“AI 是辅助,不是替代。文档结构清晰、信息一致、层次清楚,才是 AI 能发挥作用的前提。”
这句话不是客套话。SmartBot 的知识来源是用户文档、热线支持文档和案例库——如果这些底层内容质量差,AI 助手再聪明也没用。文档质量是 AI 能力的上限,这个逻辑在这里再次得到了验证。


五、本地 AI 审校:数据主权不是借口,是真实门槛
演讲者:Ján Štefančík(ESET,文档高级经理)

ESET 是欧洲老牌网络安全公司,30 年历史,10 亿用户。Jan 带来的议题听起来很技术:本地 AI 文档审校。但他真正在讲的,是一个很多团队都在回避的问题:
你的文档数据,到底在哪里?
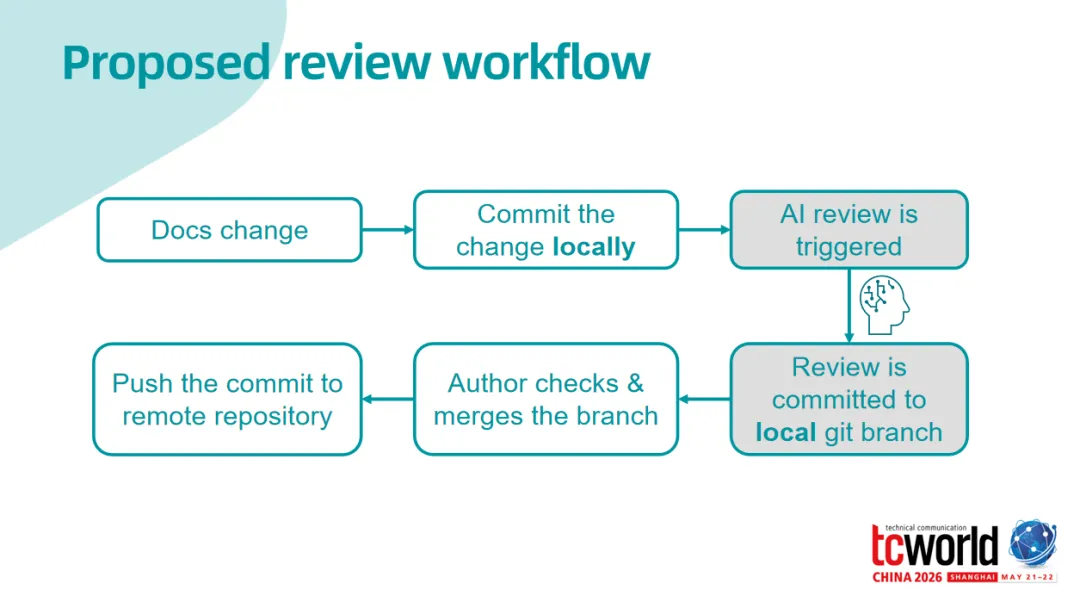
云端 AI 审校很方便,但对于安全公司来说,把内部文档发给第三方云服务,这个风险是真实存在的。Jan 的解法是:用 MCP(Model Context Protocol) 把本地小模型接入 Doc-as-Code 工作流,在本地完成 AI 审校。
整个架构是这样的:
模型选择上,Jan 分享了一个很实用的判断:小模型足够做日常审校,不需要动用大模型。他测试了 Qwen、Gemma、Liquid AI、Deepseek 等几个本地可运行的模型,关键是选择针对你的语言优化的模型——同样的信息,不同语言的 tokenizer 计数差异很大,这直接影响审校质量。
他还介绍了 Agent Skills 的概念:轻量级文本文件,用来扩展 AI Agent 的专业知识和工作流。通过把 Prompt 细节移到 Skill 文件,让 AI 在第一步就决定读取哪些 Skill,只发送 commit 的 diff 而不是整个文件——这些优化让本地小模型的审校性能大幅提升。
此外,Jan 也分享了他关注的三个未来方向:
-
动态术语注入(Dynamic Terminology Injection):通过 API 实时将最新术语库注入审校流程,解决术语更新滞后问题——对产品迭代快、术语变化频繁的团队尤其关键
-
语义护栏(Semantic Guardrails):用向量数据库构建语义边界,防止 AI 生成偏离产品语义范围的内容——这是解决幻觉问题的工程化路径,而不是依赖人工逐条审查
-
交互式信息挖掘(Interactive Elicitation):审校过程中,AI 通过 MCP 主动向作者提问,澄清模糊意图,而不是单向输出修改建议
第三个方向尤其有意思。AI就从“审校工具”升级成“协作伙伴”了,TW 的工作方式会有根本性的变化。

六、彩蛋:清晰是一种安全工具
演讲者:Daniela Zambrini(eXeL8,技术写作师 / STE 培训师)

这个议题和 AI 没有直接关系,但小编觉得值得单独提一下,因为它提醒了小编一件容易被 AI 热潮淹没的事:语言本身的清晰度,是文档质量的底线。
Daniela 讲的是 ASD-STE100(简化技术英语),一套为航空航天和国防行业开发的受控语言标准。她引用了 CHIRP Maritime 对 45 份事故报告的分析:其中涉及文档问题的事故,有 20 起导致了人员受伤。
她举的例子很直接:
-
“Tighten securely.” — 多紧算紧?
-
“Install the left clamp.” — 从谁的视角看的左?
-
“Restart the system if necessary.” — 什么情况算必要?
在压力下,人会快速解读,而模糊的语言会被解读成错误的行动。
STE 的核心原则:一个词,一种词性,一个含义。53 条写作规则,覆盖词汇选择、句子结构、程序写作、安全说明……
这个标准在 AI 时代有了新的意义:结构清晰、语义明确的内容,不只是人类读者需要,也是 AI 系统能够正确理解和调用的前提。

小结
Day 1 的三条主线
把今天的议题放在一起看,小编看到了三条交织的主线:
主线一:AI 落地的前提是”内容工程化”
无论是 SmartBot、本地审校还是幻觉控制,底层都指向同一个需求:结构化内容、清晰的元数据、可追溯的知识来源。没有这个基础,AI 工具再强大也是空中楼阁。
主线二:可控性比能力更重要
薛静和蒋诗玥的分享都在强调同一件事:AI 智能体的挑战不是”会不会”,而是”能不能被管住”。硬约束、锚点策略、事实核查——这些都是在给 AI 加”护栏”,而不是给它更多自由。
主线三:TW 的角色在向”工程师”迁移
从”写文档”到”构建让 AI 能正确理解和调用内容的知识架构”,从”审校内容”到”训练和管理模型”——这个迁移不是未来时,是现在进行时。
可以从这几件事开始
AI时代以来,与其整日担心被替代,不如从今天开始琢磨怎么跟 AI 共事。
-
盘一下现有文档的“AI可读性”:结构化程度、元数据覆盖率、术语一致性
-
挑一个具体场景试点本地AI审校:参考ESET的架构,从最小可行的 Doc-as-Code + 本地模型开始,数据不出内网
-
建立幻觉控制的工程意识:不要只靠提示词软约束,要设计可强制执行的锚点机制
-
关注Skills/MCP生态:它正在成为AI跟工作流集成的标准协议,值得提前了解

更多精彩,小编带你云逛大会现场
Day 1 的精彩远不止上面分享的几个议题,小编只恨分身乏术,难以听全所有嘉宾的精彩演讲。想要一览 Day 1 都讲了啥,以下就是第一天的完整 Program 安排。

现场就更热闹了,接下来就让小编带你云逛逛,直击大会现场各处精彩!
清早的签到处,志愿者们忙碌地帮助与会者完成签到和资料领取。

“智聚同行,共解新局”,大会主题展板前一如既往是热门拍照打卡机位。




tcworld China 组委会核心成员唐玉婷女士携手 tekom 首席执行官 Micheal Fritz 先生联袂开场致辞,正式拉开大会帷幕。


新增 TC 灵感花园,吐槽还是灵感,都等着你来。

茶歇期间,沟通不停,思想碰撞不间断。

最后,衷心感谢语言桥为本场大会全程提供专业高效的同传字幕支持,助力会议顺畅圆满开展。

点击 “阅读原文”,一键获取大会两天的完整安排。同时,敬请期待下一篇大会第二天的报道!
文案:本文由碳基小编与硅基伙伴共同生成
审核:碳基小编







