 夜雨聆风
夜雨聆风





开源,Openclaw增强,TencentDB Agent Memory:腾讯云开源 AI 记忆框架技术解析
嗨,我是小华同学,专注解锁高效工作与前沿AI工具!每日精选开源技术、实战技巧,助你省时50%、领先他人一步。👉免费订阅,与10万+技术人共享升级秘籍!
一个让 AI 助手不再”转头就忘”的开源方案,四层记忆金字塔 + 本地零依赖,两个月狂揽 5,066+ Star。
你有没有过这种经历?花半小时告诉 AI 你的写作规范——Markdown、16 字标题、开头钩子、结尾 CTA——第二天打开新对话,一切归零。就像每天早上去公司,所有同事都不认识你了,得重新入职培训一次。
这,就是 AI Agent 的「失忆症」。而腾讯云刚刚开源的 TencentDB Agent Memory(v0.3.6),就是专门治这个病的。
背景:AI Agent 为什么容易”失忆”?
要理解这个问题,我们得先知道现在的 AI 是怎么工作的。
每次你跟 AI 对话,它看到的其实是一个「上下文窗口」——你可以理解成一页草稿纸,里面写着你当前这次对话的所有内容。这页草稿纸大小是有限的,一旦超出了,最早写的内容就会被擦掉。
过去大家为了解决这个问题,想过两种办法:
- ●第一种:把聊天记录全塞进去。 结果草稿纸很快就满了,而且越往后越贵(AI 按字数收费),最后直接爆掉。
- ●第二种:把历史对话压缩成摘要。 就像把一本书压缩成一句话,虽然省空间,但大量细节被丢了,想找之前的某个具体信息根本找不到。
这两种方案的毛病是一样的:它们把记忆当成”存东西”,而不是”理解东西”。
腾讯云的思路不一样。他们从人脑的工作方式中得到了启发。
核心原理:四层记忆金字塔,像人脑一样记忆
人的记忆不是一个大垃圾桶,什么东西都往里面丢。你不会记住今天路上看到的所有车牌号,但你会记住今天跟朋友聊了一件很有意思的事。人脑会分层——有些东西是模糊的印象,有些是清晰的画面,有些是精确的数字。
TencentDB Agent Memory 把同样的思路用在了 AI 身上,设计了一个 四层记忆结构。
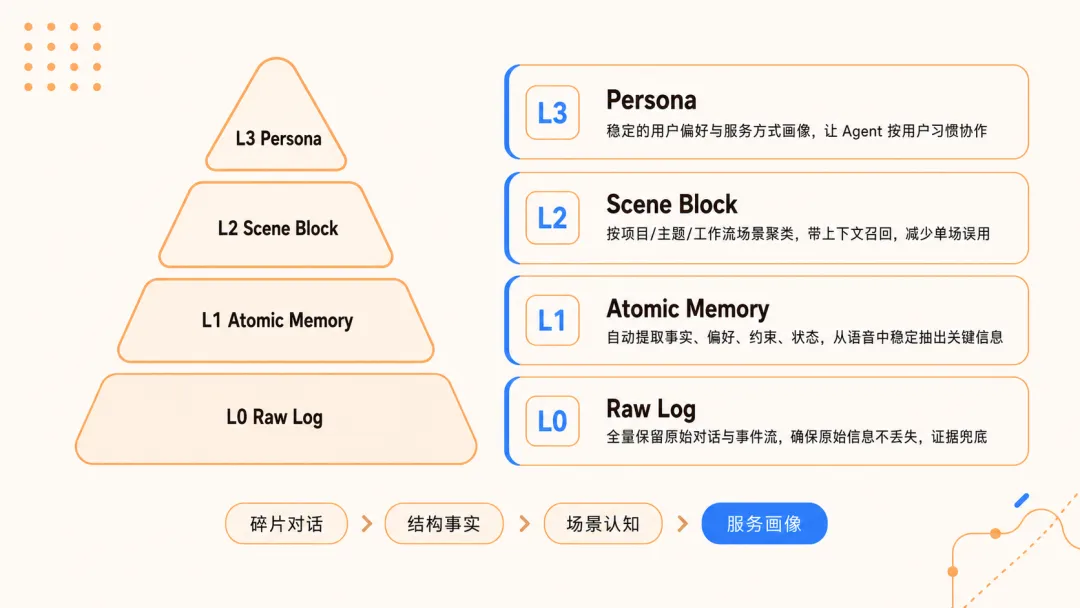
第一层(L0):原始对话记录
这是 AI 跟你说的每一句话的完整存档,就像记忆的「硬盘」。平时不翻它,但需要的时候随时可以找回来。这一层保证:任何时候,任何细节都不会丢失。
第二层(L1):原子事实
AI 会从你们的聊天中自动提取出一个个「关键事实」,就像给你整理了一张张记忆卡片。比如”用户喜欢用 Markdown 格式”、”用户是腾讯云的产品经理”、”用户在写公众号文章”。这些都是独立的小事实。
第三层(L2):场景块
把多个相关的事实拼在一起,就形成了一个完整的「场景」。举个例子:L1 里散落着”Markdown 格式””16-26 字标题””开头钩子””结尾 CTA”,L2 把它们组装成一个场景——「用户在写公众号文章,遵循特定的写作规范」。
第四层(L3):用户画像
这是最上层,也是最智能的一层。它会根据你长期的行为,生成一个持续更新的「用户画像」。你写作习惯用什么风格、你更偏好简洁还是详细、你目前的长期目标是什么——这些不用你反复说,AI 自己就知道了。
用人话总结就是:L3 画像让 AI 知道”你是什么样的人”,L2 场景让它知道”我们在做什么事”,L1 事实是”为什么这么做的证据”,L0 原始对话是”证据从哪里来的”。
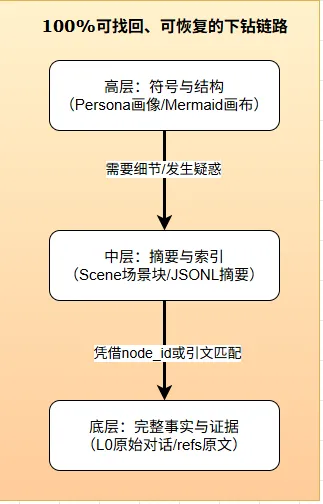
而且最关键的一点——这四个层次之间可以双向追溯。你想知道 AI 为什么认为你喜欢 Markdown?从 L3 画像往下追,经过 L2 场景、L1 事实,一路追到 L0 里你某天发的那条消息。全程透明,没有黑盒。
应用场景:这套记忆系统能用在哪儿?
说了这么多原理,这套系统在实际业务中到底能做什么?以下是最典型的 4 个场景:
个人 AI 助手 — 长期对话记忆。 你每天用 AI 处理写作、调研、日程管理,随着对话轮次增多,AI 越用越懂你——不再需要每次重复你的工作流程和输出偏好。比如你坚持用 Markdown 写周报,两周后 AI 自动准备好格式,你只需填内容。
企业客服智能体 — 客户画像沉淀。 客服 AI 对接数百个客户,每个客户的诉求、沟通风格、历史问题各不相同。记忆系统自动为每个客户构建独立画像,下次客户开口,AI 就知道他是”产品 B 的老用户,上次为接口文档问题咨询过”。
代码开发协作 — 项目上下文保持。 一个项目可能跨度数月,中间经历多次需求变更和技术选型。记忆系统持续记录每次讨论的关键决策和原因,下次打开新对话,AI 直接基于完整的项目记忆继续推进。
长期调研项目 — 跨会话信息积累。 写行业调研报告可能需要反复搜索、对比、迭代修改。记忆系统把每次对话的关键发现沉淀为结构化记忆,避免重复搜索和信息遗漏。
两大特色:Mermaid 任务地图 + 白盒可调试
除了四层金字塔,这套系统还有两个让人眼前一亮的创新点。
特色一:Mermaid 任务地图
AI 执行长任务时(比如修复 50 个 Bug),会产生海量的工具日志——搜索结果、报错信息、代码片段……这些日志加起来可能比一本书还厚,全部堆在”草稿纸”里,AI 直接就”撑死了”。
TencentDB Agent Memory 的解法很巧妙:把繁琐的日志卸载到外部文件,只留一张轻量级”任务地图”在上下文里。
这张地图用的是 Mermaid——一种画流程图的语法。你可以把它理解成一张施工图:上面只有关键节点和箭头,简洁明了。AI 看图就能知道任务到哪一步了,需要验证具体细节时,再根据节点编号找回原文。
这就像你搬家的时候,不是把所有家具都塞进车里,而是列一张清单贴在车上,具体家具需要时再从仓库调。

特色二:白盒可调试
很多 AI 记忆系统是”黑盒”——你只知道它记住了什么,但不知道它为什么这么记、记在哪里、准不准确。
这套系统完全反着来:所有记忆产物都以可读的 Markdown 和 Mermaid 文件存放在本地 ~/.openclaw/memory-tdai/ 目录下。你可以直接打开文件夹,像翻书一样查看 AI 记住了你哪些东西。从「用户画像 → 场景块 → 原子事实 → 原始对话」,每一步都清清楚楚——你可以自己验证 AI 有没有记错、有没有遗漏,调试过程完全透明可控。
效果如何?用数据说话
以下数据来自官方 Benchmark,对比了接入本插件前后的变化:
在短期记忆测试中:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
+51.52% | −61.38% |
|
|
|
|
|
|
|
|
|
|
|
|
在长期记忆测试中:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
+59% |
最惊喜的是:成功率大幅提升的同时,Token 消耗反而大幅下降。 在 WideSearch 测试里,Token 用量比原来少了 61.38%,成功率却翻了一半多。这说明分层记忆不只是”记得多”,而是”记得准、省着用”。
怎么用?三步接入
这套系统虽然背后技术复杂,但用起来极其简单。因为它完全本地运行,不需要任何外部 API,零配置就能开箱即用。
🔧 第一步:安装插件
打开终端,输入一行命令:
⚙️ 第二步:启用插件
在 OpenClaw 配置中加入:
✅ 第三步:验证运行状态
安装完成后,可以通过以下方式确认记忆系统正常工作:
- ●查看记忆文件:打开
~/.openclaw/memory-tdai/目录,确认是否有persona/、scenarios/、atoms/等子目录生成。 - ●查看运行日志:
openclaw gateway logs中搜索tdai或memory关键词,确认记忆采集和提取流程已启动。 - ●触发记忆召回:与 AI 进行 5-8 轮对话后,发送”你还记得我的偏好吗?”,观察 AI 是否能准确引用之前对话中提取的记忆。
当然,如果你有更多定制需求,它也提供丰富的调参选项:时区设置、召回策略、记忆提取频率、画像生成频率等等,满足高级用户的微调需求。
总结:AI 记忆的下一代方案
回过头来看,TencentDB Agent Memory 做的事情其实很朴素:
它没有发明什么”更聪明的压缩算法”,也没有搞”更大的上下文窗口”。它只是认认真真地模仿了人脑记忆的方式——把信息分层,该记得记,该忘的省,需要的时候能找回来。
但就是这么简单的一个思路,在 Benchmark 上带来了最高 +59% 的成功率提升,同时 Token 消耗减少超过 60%。
这个项目由腾讯云维护,MIT 开源协议,2026 年 4 月 7 日创建,当前版本 v0.3.6,两个月已收获 5,066+ GitHub Star 和 431 Forks。目前已有 OpenClaw 和 Hermes 两大 Agent 框架的适配,未来还会支持跨框架记忆迁移、Skill 自动生成、可视化调试面板等能力。
当然,它也不是完美的。目前需要 Node.js ≥ 22.16 的运行环境,本地 SQLite + 向量检索会消耗一定系统资源,跨框架的记忆迁移和导入导出功能尚在开发中——如果你正在使用非 Node.js 技术栈,可能需要等待后续版本的支持。
你最想用这套记忆系统解决什么问题?评论区聊聊。如果觉得有用,点个「在看」让更多人看到。
在公众号后台回复「记忆」,获取 TencentDB Agent Memory GitHub 项目地址和快速上手指南。
项目地址
https://github.com/TencentCloud/TencentDB-Agent-Memory
推荐阅读
开源项目,用自然语言一句话,生成高保真设计稿,太丝滑啦~~~
AiToEarn 评测:我用它一个人管了 10 个平台,内容运营闭环实测