 夜雨聆风
夜雨聆风





运维界的 OpenClaw 来了!
一个看得懂系统、查得出根因、还能动手解决的AI Agent。 监控、远程执行、知识库、专家智能体、Bash、文件等各类技能——直接通过飞书、Slack、Telegram下达指令。
过去十年,运维工具堆得越来越高:Prometheus 看指标、Loki 翻日志、Grafana 画图、Jaeger 追链路、再加一堆告警群和值班表。但凌晨三点告警一响,工程师要做的事情还是老一套——在七八个面板之间来回跳,把碎片拼成一个”为什么”。
而Ongrid(https://github.com/ongridio/ongrid) 是完全AI Nitave的做法:让 AI Agent 替你跳面板、拼线索、写结论,把人从”采集者”变成”决策者”、”诊断者”。而且——它完全开源、一行命令就能自托管,数据全程不出你自己的机房。
下面,跟着每一个模块,看看它到底能干什么。
一、入口:用一句话开始,而不是一堆面板
打开 Ongrid,迎接你的不是密密麻麻的图表,而是一句随机prompt例如:“需要我先做些什么?”
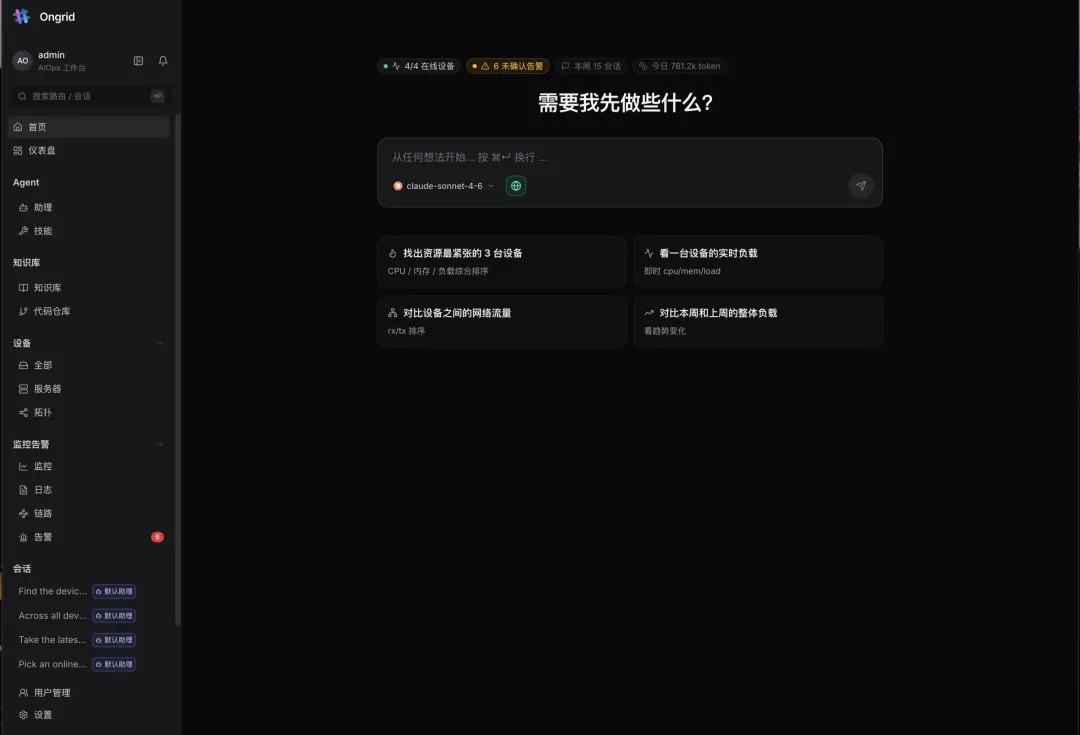
顶部一行就是集群的”体温”:4/4 在线设备、6 未确认告警、本周会话数、今日 LLM token。下面是几个开箱即用的意图卡片——”找出资源最紧张的 3 台设备”、”看一台设备的实时负载”、”对比设备之间的网络流量”。
你不需要记 PromQL,不需要知道指标叫什么。想问什么,就打一句中文。 剩下的,交给 Agent。
二、Agent 助理:会自己编排工具的运维大脑
这是 Ongrid 的心脏。当你问”找出当前 CPU、内存或负载最紧张的 3 台设备,给出关键指标和判断依据”——
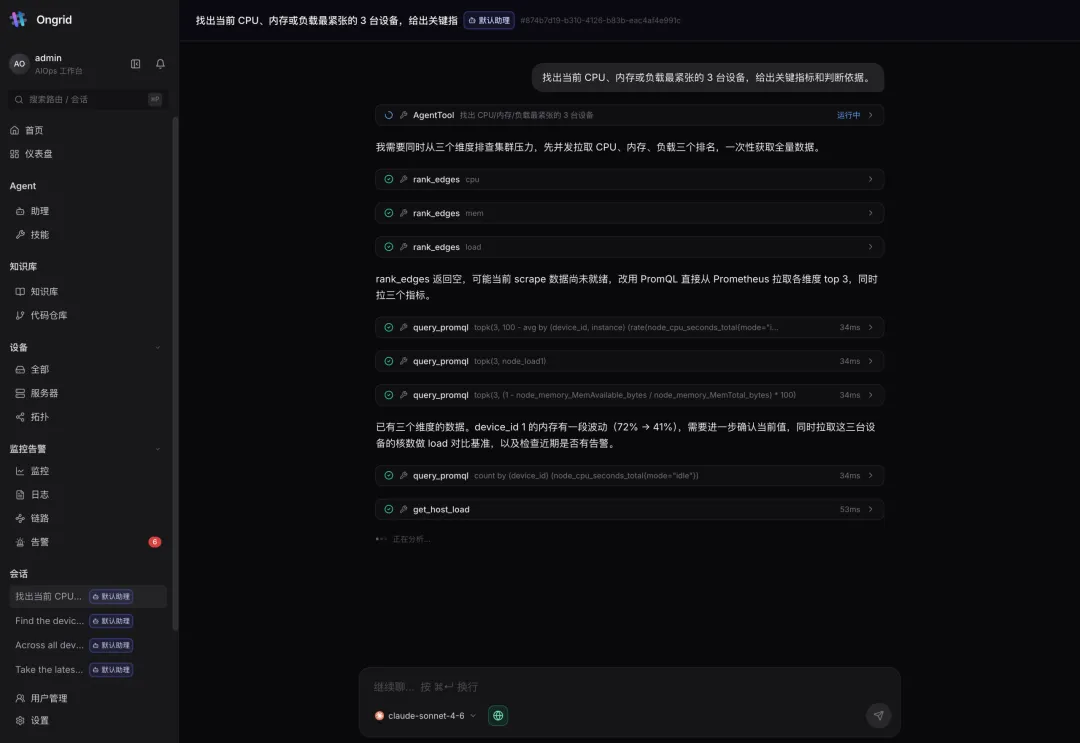
看它怎么干活:
-
并行拉取三个维度(CPU / 内存 / 负载)的排名; -
发现 rank_edges返回空,自己判断“可能 scrape 数据尚未就绪”,立刻改用query_promql直接从 Prometheus 取 top 3; -
注意到 device_id=1内存有波动(72% → 41%),主动追加查询去确认当前值,并拉核数做 load 基准、检查近期告警。
这不是一个”问一句答一句”的聊天机器人,而是一个会自己设计排查路径、遇阻会换路、看到异常会深挖的协调者(Coordinator)。它背后还能把任务分派给 SRE / 网络 / 数据库子专家。每一次工具调用都清清楚楚列在时间线里,可审计、可复盘。
三、仪表盘:集群态势一屏掌握
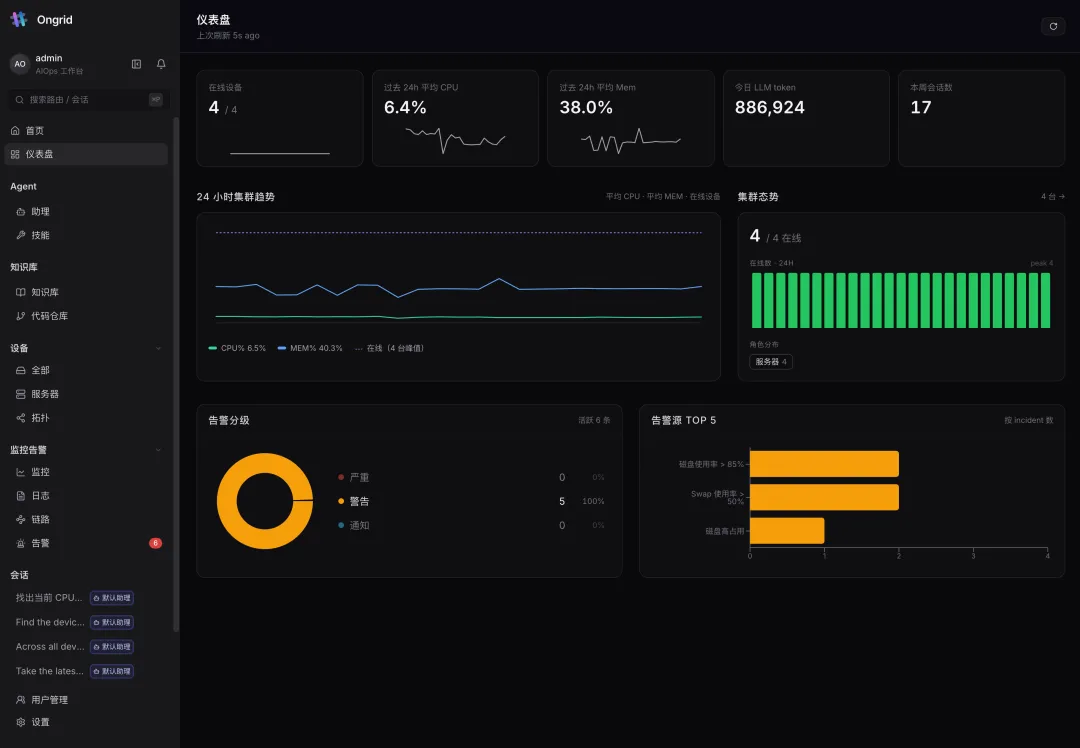
在线设备、过去 24h 平均 CPU / 内存、今日 LLM token、本周会话数——核心指标卡顶在最上面。下面是 24 小时集群趋势、集群在线态势(绿色心跳条一眼看出谁掉过线)、告警分级环图,以及”告警源 TOP 5″。
它既是给人看的总览,也是给 Agent 用的上下文。 当你发起一次诊断,Agent 看到的,和你看到的,是同一份实时态势。
四、设备纳管 + 浏览器 SSH:零入站端口,开箱即连
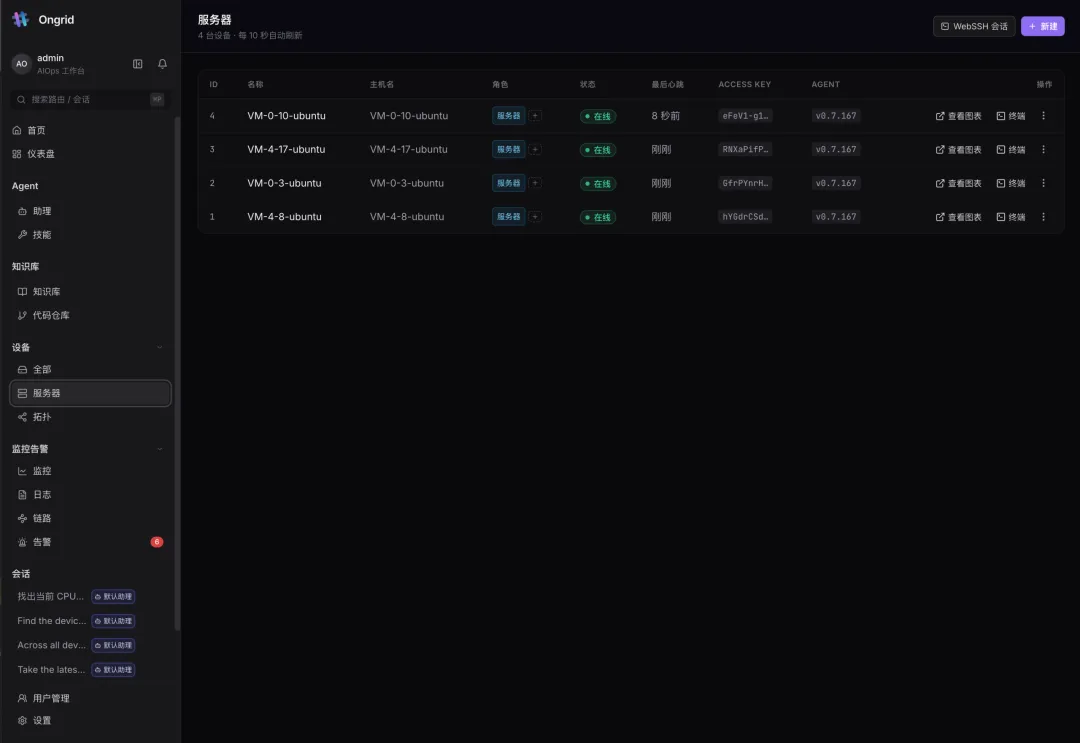
每台机器装一个轻量 edge agent,主动拨出到云端建隧道——主机上不需要开放 22 / 80 / 443 任何入站端口。列表里在线状态、最后心跳、版本一目了然。
最爽的是右边那颗”终端”按钮:
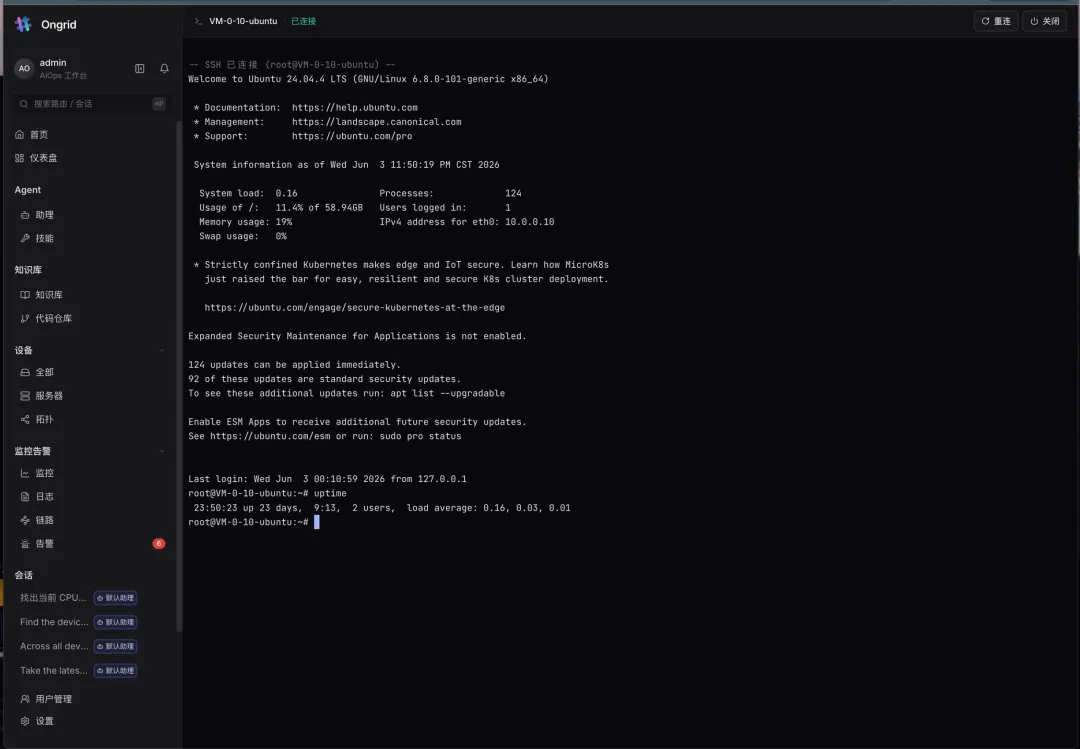
点一下,浏览器里直接弹出一个真实的 SSH 会话——root@VM-0-10-ubuntu,uptime、apt list 随便敲。没有跳板机、不用分发密钥、走反向隧道、全程审计。 在任何一台内网机器上拿到一个 shell,从此只要一次点击。
🔒 技术解密:零端口暴露怎么做到的?
传统方案是”云端来连主机”,每台机器都得开端口、放行入站——每开一个口,就多一个被攻击的面。Ongrid 反过来:主机上的 edge 只做一件事——主动向云端拨出一条加密连接,就像浏览器访问网站一样。之后所有命令、SSH、文件传输,全都在这条主机自己发起的隧道里反向流动。
结果就是:主机零监听端口、防火墙入站规则可以全关,22 / 80 / 443 一个都不用开。攻击面从”每台机器一堆开放端口”,收敛成”一条出站连接”。
五、监控:内置可观测全家桶,Agent 自己写查询
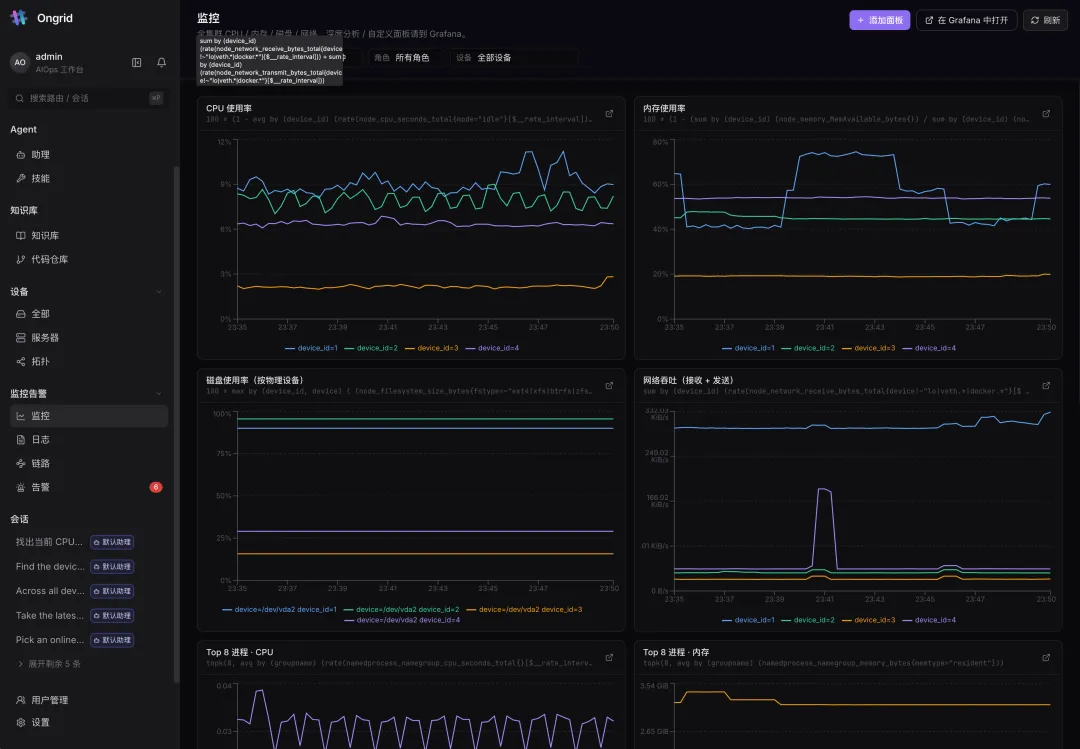
Prometheus + Grafana 已经接好。全集群 CPU / 内存 / 磁盘 / 网络吞吐、按物理设备拆分、Top 8 进程 CPU / 内存——这些面板出厂即用。需要深度分析或自定义?一键跳 Grafana。
关键在于:这些 PromQL 不需要你写。 面板标题上挂着的就是真实查询语句,而当 Agent 排查时,它会自己拼出 topk(8, ...)、rate(node_network_receive_bytes_total{...}) 这样的表达式去取数。可观测栈是它的”眼睛”,不是你的负担。
六、日志:LogQL 直查 Loki,一行就是一条线索
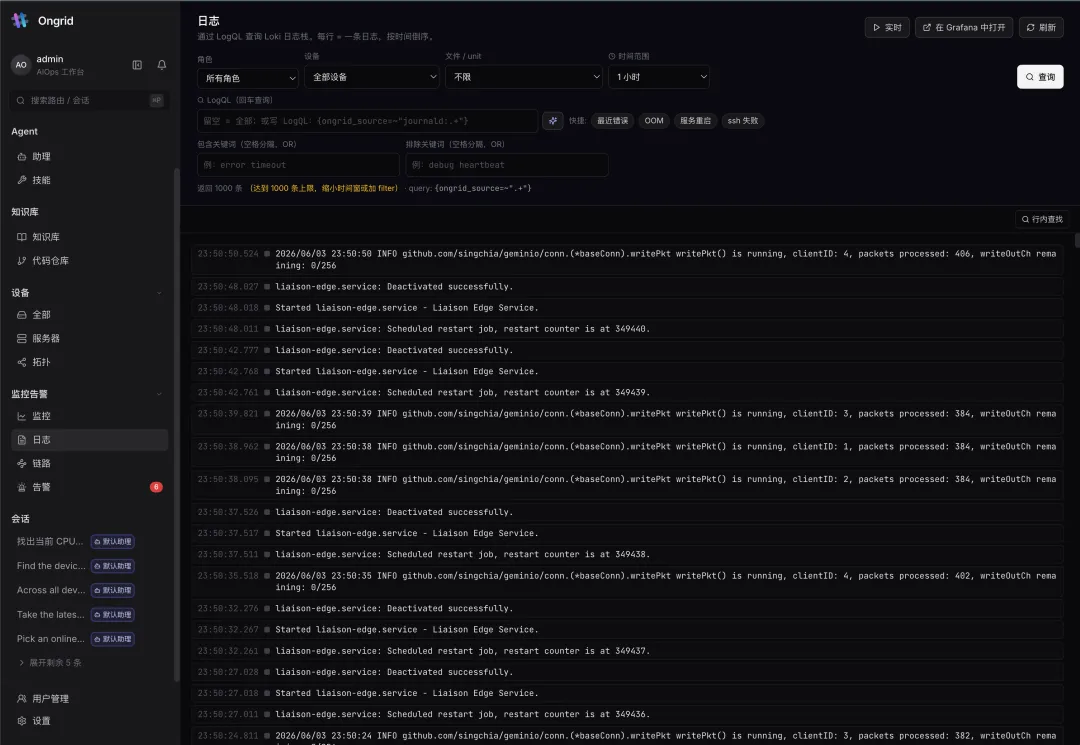
同样地——Agent 也能查日志。 一次根因分析里,它会把指标的异常窗口和日志里的关键事件对齐,让”现象”和”证据”自动咬合。
七、告警 + 根因分析(RCA):从”报警”到”答案”的最后一公里
这是 Ongrid 最能打的一块。告警不再只是一条红色通知,而是一份带证据链的根因报告:
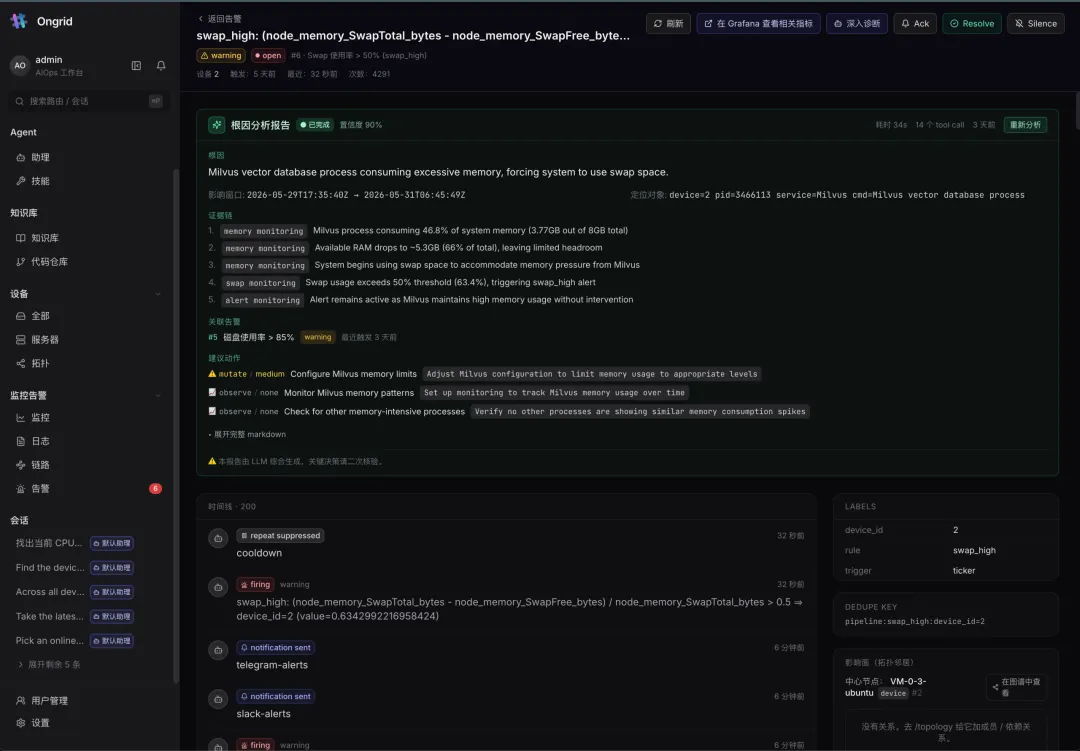
swap_high 触发后,Agent 自动起了一次 RCA,耗时 34 秒、调用 14 个工具、置信度 90%,给出结论:
根因:Milvus 向量数据库进程占用内存过高,把系统逼到使用 swap。 定位对象精确到
device=2 pid=3466113 service=Milvus。
下面是一条条带标签的证据链(memory monitoring → swap monitoring → alert monitoring)、关联告警(#5 磁盘使用率 > 85%)、以及带优先级的建议动作(mutate / observe)。右侧还顺手算出了影响面(拓扑邻居)——这台设备出事,会波及谁。
从”Swap 使用率 > 50%”这种干巴巴的阈值,到”是 Milvus 把内存吃爆了,建议这样配限制”——中间那一公里,Agent 替你走完了。
八、知识库(RAG):96 篇运维 Playbook 出厂内置
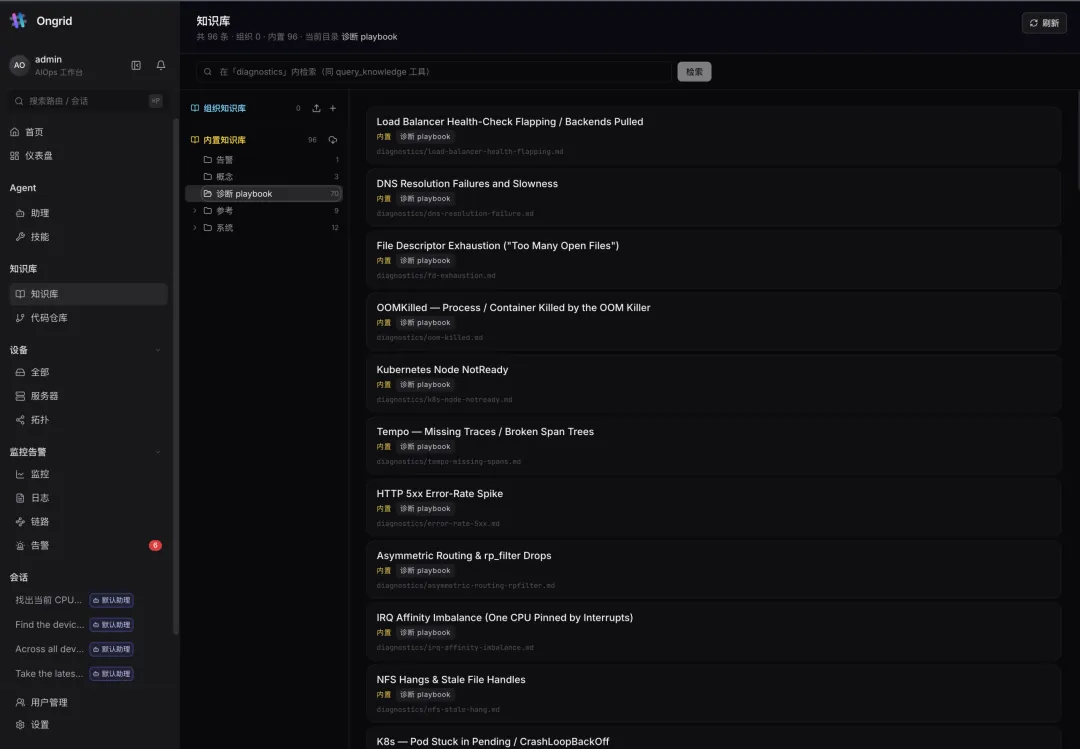
Ongrid 内置 96 篇运维知识,其中 70 篇诊断 Playbook——DNS 解析失败、文件描述符耗尽、OOMKilled、K8s Node NotReady、负载均衡健康检查抖动、非对称路由 rp_filter 丢包、IRQ 亲和失衡、NFS 卡死……几乎覆盖了一线最常见的疑难杂症。
这些不是摆设:Agent 排查时会用 query_knowledge 检索它们,把”行业经验”注入到每一次诊断里。组织还能上传自己的 Playbook(md / txt / pdf / docx),或接入私有代码仓库,让 AI 懂你自己的系统。
九、技能(Tools):33 个能力,AI 的”手”
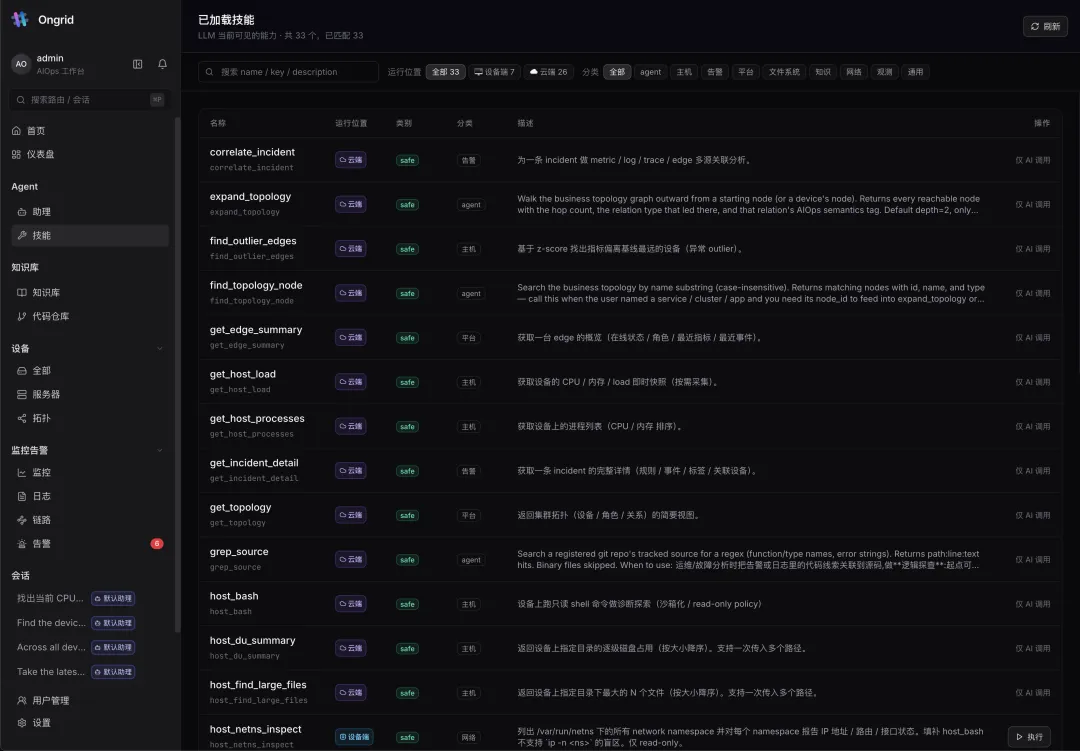
LLM 当前可见的能力一共 33 个——7 个跑在设备端、26 个跑在云端,按 agent / 主机 / 告警 / 平台 / 文件系统 / 知识 / 网络 / 观测分类:
-
correlate_incident——为一条 incident 做 metric / log / trace / edge 多源关联; -
expand_topology/find_topology_node——在业务拓扑图里 BFS 计算影响面; -
host_bash——设备上跑只读 shell 做诊断探索(沙箱化 read-only 策略); -
get_host_load/get_host_processes/host_du_summary/host_find_large_files——主机即时快照; -
host_netns_inspect——列出 network namespace 报告 IP / 路由 / 接口状态……
每一个都标了 safe、标了运行位置、标了是否”仅 AI 调用”。这就是 Agent 的双手——而且每一次出手都在沙箱里、都被审计。
十、模型自由:自带钥匙,热切换不重启
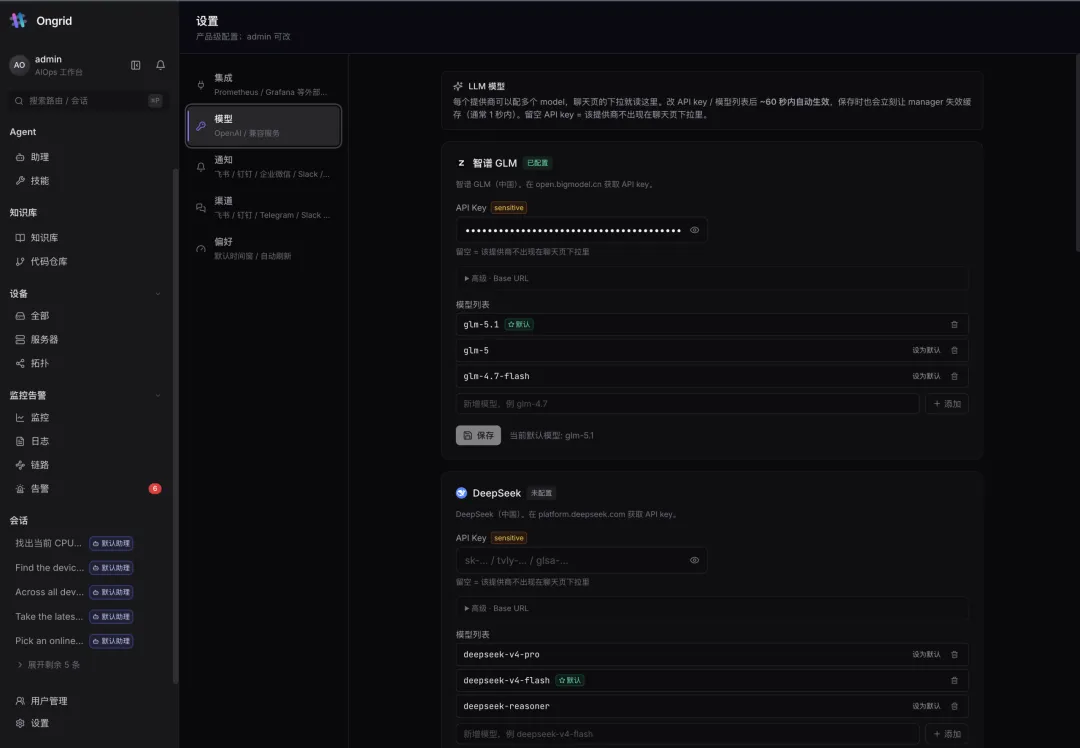
不绑定任何一家模型厂商。Anthropic / OpenAI / 智谱 GLM / DeepSeek / Gemini / Kimi——填上自己的 API Key 即可,每个提供商可配多个 model,聊天页下拉直接读这里。
改了 key 或模型列表,~60 秒内自动生效,无需重启。留空某个提供商的 key,它就不出现在下拉里。默认模型一键切换,全平台(RCA / 翻译 / 聊天)跟随——今天用 glm-5.1,明天想换 Claude,鼠标点一下的事。
十一、通道:告警和对话,直接打进飞书
排查能力再强,也得”送到人手边”。Ongrid 支持 Slack / Telegram / 飞书 / 钉钉 / 企业微信 五大 IM 双向通道——告警推得出去,指令也能从群里发回来,每个通道还能配独立语言。
一段飞书里的真实交互:

十二、最重要的一件事:它是开源的
说了这么多能力,但 Ongrid 最该被记住的一点是——它完全开源,Apache 2.0 协议,代码就摆在 GitHub 上(github.com/ongridio/ongrid)。
这意味着什么?
-
一行命令,全栈自托管。 docker compose up,Prometheus + Loki + Tempo + Grafana + Agent 一整套直接在你自己的机器上跑起来。不是 SaaS 试用,不是 demo 沙箱——是你拥有的、能改的、能审计的完整系统。 -
数据不出门。 指标、日志、链路、SSH 会话、告警、对话记录,全都留在你自己的基础设施里。对金融、政企、私有化交付这些数据不能上公有云的场景,这不是加分项,而是能不能用的前提。 -
没有黑盒。 Agent 每一步怎么决策、调了哪些工具、跑了什么命令,代码里写得清清楚楚,行为可复现、可裁剪。担心 AI 在生产环境乱来?那就把它的”手”(技能)按你的策略锁死——源码在手,规则你定。 -
模型也由你做主。 配合前面说的”自带 API Key、热切换”——上层 Agent 开源、底层模型自带,从代码到大脑,整条链路都不绑定任何一家厂商。
闭源 SaaS 给你一个”信任我”的承诺;开源给你一份”自己验”的源码。运维这种事,后者才让人睡得着。
三步装起来
支持 Ubuntu 22.04+ / Debian 12+ / RHEL·Rocky 9。下载 release、解压、跑安装脚本:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line# 1. 下载最新 releasewget https://github.com/ongridio/ongrid/releases/download/v0.7.168/ongrid-v0.7.168-linux-amd64.tar.xz# 2. 解压tar -xf ongrid-v0.7.168-linux-amd64.tar.xz && cd ongrid-v0.7.168-linux-amd64# 3. 安装sudo ./install.sh
想从源码起整套栈做本地开发?配好管理员账号和一个模型 API key 即可:
ounter(lineounter(linecp deploy/.env.example deploy/.envmake compose-up # 停止用 make compose-down
跑完,浏览器打开就是你在上面看到的那个工作台——全部在你自己的机器上。
结语:从”看图的人”到”做决策的人”
Ongrid 把可观测、设备直达、AI Agent、知识库、IM 通道拧成了一根链条:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
采集、拼图、翻面板的脏活,交给 Agent。判断和决策,留给人。 而这一切,开源、自托管、数据不出门。
运维届的 OpenClaw,真的来了——而且,它把源码也一起交到了你手上。
⭐ GitHub:github.com/ongridio/ongrid · Apache 2.0 · docker compose up 一键自托管
最后的最后,重要的事说三遍(不管你是懂chatbot、grafana、prometheus、loki、llm、agent、sandbox、skill、harness、网络等等):
欢迎贡献代码,一起来做最好的AI Ops Agent吧,迫切需要你加入!!!
欢迎贡献代码,一起来做最好的AI Ops Agent吧,迫切需要你加入!!!
欢迎贡献代码,一起来做最好的AI Ops Agent吧,迫切需要你加入!!!