夜雨聆风
夜雨聆风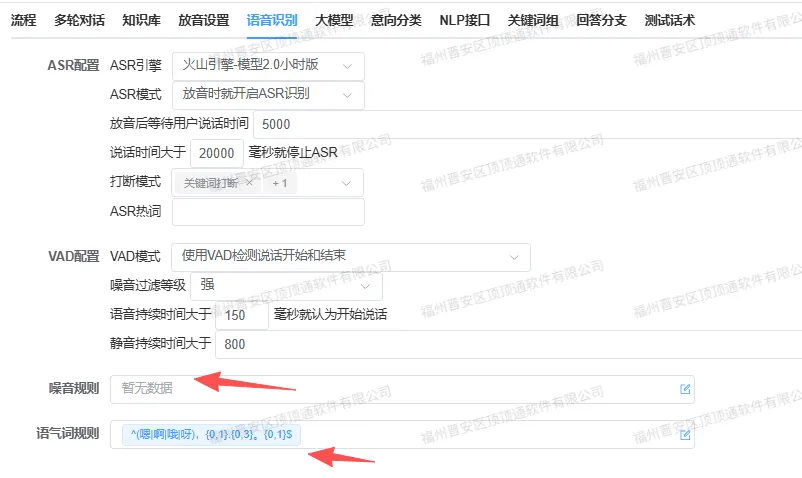
在顶顶通AICC系统 (AI大模型呼叫中心系统)的语音识别功能中,有两个高频实用规则——过滤噪音规则和语气词规则 (避免被语气词打断)。正则表达式是这两个规则的核心,今天就用最通俗的语言、最实用的案例,教大家快速掌握这些常用正则写法,一看就会、一用就对!
一、核心重点:语气词开头正则写法
先从最常用的语气词规则入手,给大家拆解一个经典正则,逐段讲明白每一部分的含义,再也不用怕看不懂复杂符号~
经典正则示例
逐段拆解(超直白)
- ^(嗯|啊|哦|呀|哦|噢)
:开头必须是这些语气词中的任意一个(嗯、啊、哦、呀、噢均可)✅ - ,{0,1}
:语气词后面,可带1个中文逗号,也可以不带(灵活适配不同口语习惯)✅ - .{0,3}
:中间可接0~3个任意字符(汉字、字母、标点都算1个字符)✅ - 。{0,1}$
:结尾可带1个中文句号,也可以不带,且到这里结束,不能多字少字✅
常见疑问:为什么能匹配「啊,知道了。」?
很多人会疑惑:「啊,知道了。」看起来很长,为什么能匹配上面的正则?我们逐字对应拆解就懂了:
「啊,知道了。」拆解后:
啊 → 开头语气词(符合规则第一部分) , → 1个中文逗号(符合「,{0,1}」) 知道了 → 3个汉字(刚好符合「.{0,3}」,不超限制) 。 → 1个中文句号(符合规则最后一部分)
所以它完全符合规则,自然能被匹配到~
小调整:拒绝过长短句
如果想让「啊,知道了」这类中间超过2个字符的句子被拒绝,只需修改一个数字,把「.{0,3}」改成「.{0,2}」,修改后正则如下:
二、实用案例:4个场景,一看就会
结合实际使用场景,给大家整理了4个高频例子,覆盖不同需求,直接复制就能用!
例子1:限制中间最多2个字
正则规则:
✅ 能匹配(符合规则):
啊、哦,好、嗯,行。、噢行
例子2:必须带逗号,中间1~2个字
正则规则:
✅ 能匹配(符合规则):
啊,好。、哦,行吧、嗯,知道
❌ 不能匹配(不符合规则):
啊好(没带逗号)、哦,知道了(中间3个字,超限制)、嗯,你说得对(太长)
例子3:只匹配单个语气词(无多余内容)
正则规则:
✅ 能匹配(符合规则):
嗯、啊、哦
❌ 不能匹配(不符合规则):
嗯啊(两个语气词)、啊,好(带多余内容)、哦知道了(带多余内容)
例子4:语气词开头,不限制后续长度
正则规则:
💡 关键说明:.* 表示“任意字符、任意长度”,也就是语气词后面可以接任何内容,不做限制。
✅ 能匹配(符合规则):
啊,你说得对、哦,我知道了、嗯,这个事情我明白了
三、其他常用正则写法(顶顶通AICC高频)
除了语气词规则,再给大家整理3个系统常用的正则写法,覆盖否定词、身份证、银行卡校验场景,直接复制可用~
- 否定词开头写法
适用于过滤“不、没”开头的否定类短句,正则如下:
- 银行卡号码校验(16位,#结尾)
规则:16位纯数字,以#号结束,正则如下:
四、小总结
其实顶顶通AICC系统里的正则规则,核心就是这几个基础符号:
• (A|B|C):A、B、C三选一(语气词、否定词常用)
• .{0,n}:最多n个任意字符
• ^$:从开头到结尾,严格匹配
• \d:纯数字
记住这些,再结合上面的案例,就能轻松应对语音识别中的正则配置啦!如果有特定场景的正则需求,也可以留言补充~
|(注:文档部分内容可能由 AI 生成)