 夜雨聆风
夜雨聆风





深度解密Kafka消息存储:从源码到磁盘的极致性能之路

为什么Kafka能支撑百万级消息吞吐量?为什么重启后能快速恢复数据?答案都藏在它的消息存储机制里。本文将从源码层面深度解析Kafka如何通过巧妙的磁盘设计和索引机制,实现高性能与可靠性的完美平衡,带你看透消息从内存到磁盘的每一步流转。
一、Kafka消息存储的核心架构:Log与LogSegment
Kafka的消息存储采用了分段式日志(Log Segment)设计,这是其高性能的基石。在Kafka源码中,Log类代表一个分区的日志集合,而每个Log由多个LogSegment组成。
// Kafka Log类核心结构
public class Log {
private final List<LogSegment> segments;
private LogSegment activeSegment;
// 追加消息到活跃Segment
public long append(MemoryRecords records) {
ensureOffsetInRange(records);
return activeSegment.append(records);
}
}
每个LogSegment对应磁盘上的两个文件:.log数据文件和.index索引文件。这种设计的优势在于:
– 避免单个文件过大:每个Segment默认大小为1GB,方便文件管理和清理
– 提高读写性能:顺序写入磁盘,利用磁盘预读特性
– 高效过期删除:直接删除整个Segment文件,避免随机IO
二、消息写入流程:从生产者到磁盘的极致优化
当生产者发送消息到Kafka时,消息经历的核心流程如下:
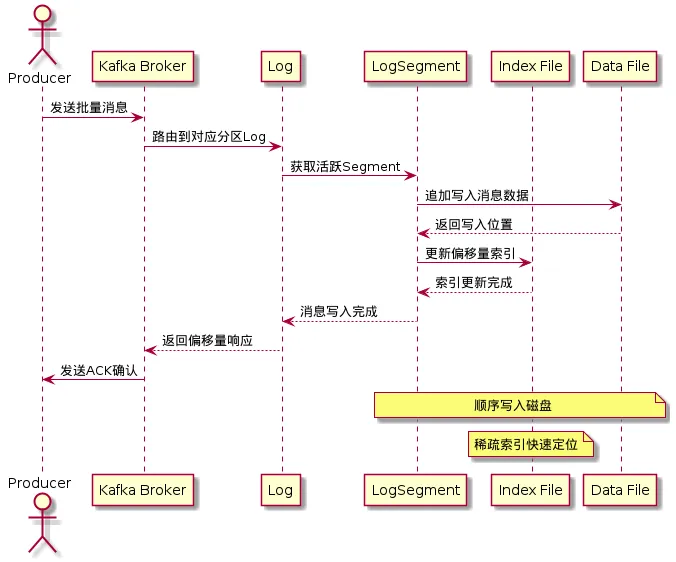
1. 内存缓冲与批量写入
Kafka在ProducerBatch中实现了批量消息处理,通过RecordAccumulator积累消息,达到一定大小或时间后批量发送。
// 生产者批量发送核心逻辑
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return accumulator.append(tp, timestamp, serializedKey, serializedValue,
headers, interceptCallback, true);
}
关键优化点:
– 减少网络IO次数:批量发送降低了TCP连接的开销
– 提高磁盘写入效率:批量写入减少了磁盘寻道时间
2. 磁盘写入与刷盘策略
消息到达Broker后,首先写入PageCache,然后通过异步刷盘策略持久化到磁盘。Kafka提供了三种刷盘策略:
# 刷盘策略配置
log.flush.interval.messages=10000 # 每10000条消息刷盘
log.flush.interval.ms=1000 # 每1秒刷盘
log.flush.scheduler.interval.ms=9223372036854775807 # 调度器间隔
在源码中,LogSegment的append方法负责将消息写入内存映射文件:
public long append(MemoryRecords records) {
int written = records.sizeInBytes();
mappedByteBuffer.put(records.buffer());
mappedByteBuffer.force(); // 强制刷盘(根据策略触发)
return nextOffset;
}
三、索引机制:实现消息的O(1)时间复杂度查找
Kafka通过偏移量索引和时间戳索引实现了消息的快速定位,这是其能支持百万级消息快速查询的关键。
1. 偏移量索引(.index文件)
偏移量索引存储了消息偏移量与文件位置的映射关系,采用稀疏索引设计,每隔一定字节数建立一个索引项。
// 偏移量索引核心结构
public class OffsetIndex extends AbstractIndex {
public void append(long offset, int position) {
validateOffset(offset);
buffer.putLong(offset);
buffer.putInt(position);
entries++;
}
public long lookup(long targetOffset) {
// 二分查找定位索引项
int idx = binarySearch(targetOffset);
return buffer.getLong(idx * 12);
}
}
设计优势:
– 减少索引文件大小:稀疏索引降低了内存占用
– 快速定位:通过二分查找在O(log n)时间内找到最近的索引项
– 顺序读取:从索引位置开始顺序扫描少量消息即可找到目标
2. 时间戳索引(.timeindex文件)
时间戳索引存储了消息时间戳与偏移量的映射,支持按时间范围查询消息。
// 时间戳索引核心逻辑
public class TimeIndex extends AbstractIndex {
public void append(long timestamp, long offset) {
buffer.putLong(timestamp);
buffer.putLong(offset);
entries++;
}
public TimestampAndOffset lookup(long timestamp, boolean ceil) {
// 根据时间戳查找对应的偏移量
int idx = binarySearch(timestamp, ceil);
return new TimestampAndOffset(buffer.getLong(idx * 16), buffer.getLong(idx * 16 + 8));
}
}
四、磁盘存储优化:从硬件到算法的全方位打磨
Kafka充分利用了现代硬件特性和算法优化,将磁盘性能发挥到极致。
1. 顺序IO的极致利用
与随机IO相比,顺序IO的性能高出几个数量级。Kafka的分段式日志设计确保了消息始终以顺序方式写入磁盘,完美契合磁盘的物理特性。
2. 零拷贝技术
在消息消费时,Kafka使用零拷贝(Zero Copy)技术直接将磁盘文件数据发送到网络,避免了用户态与内核态之间的数据拷贝。
// 零拷贝发送核心逻辑
public void transferTo(SocketChannel socketChannel) throws IOException {
long position = fileChannel.position();
long count = fileChannel.size() - position;
fileChannel.transferTo(position, count, socketChannel);
}
3. 文件预分配与稀疏文件
Kafka通过FileChannel预分配磁盘空间,避免文件扩展时的磁盘碎片问题。同时,利用稀疏文件特性,在创建Segment时预分配空间但不实际占用磁盘,只有写入数据时才真正分配磁盘块。
五、消息过期与清理:高效释放磁盘空间
Kafka提供了两种消息清理策略:删除策略和压缩策略,通过LogCleaner线程实现。
# 清理策略配置
log.cleanup.policy=delete # 默认删除策略
log.retention.hours=168 # 保留7天
log.segment.bytes=1073741824 # 每个Segment 1GB
在删除策略中,Kafka直接删除过期的Segment文件,避免了对单个消息的删除操作,极大提高了清理效率。
以上就是Kafka消息存储机制的核心原理。从分段式日志设计到高效索引机制,从批量写入到零拷贝优化,每一个细节都体现了Kafka对性能的极致追求。
写在最后
Kafka的消息存储机制是其高性能和可靠性的核心保障,通过巧妙的架构设计和算法优化,将磁盘IO的性能发挥到了极致。希望本文能帮助你更深入地理解Kafka的底层原理,在实际应用中更好地优化和调优Kafka集群。
欢迎在评论区分享你对Kafka的使用经验和优化技巧,一起探讨分布式消息系统的技术奥秘!