 夜雨聆风
夜雨聆风





03. nanobot 源码解读:LLM参数构造
03. nanobot 源码解读:LLM参数构造
文档内容基于 HKUDS/nanobot: “🐈 nanobot: The Ultra-Lightweight Personal AI Agent” 的 main 分支 3c06db7 提交进行说明。
目录
-
• 03. nanobot 源码解读:LLM参数构造 -
• 目录 -
• LLM 接口入参说明 -
• nanobot 的 tool -
• tool概念说明 -
• LLM 使用 tool 的工作流程 -
• nanobot 的 tool 实现 -
• tool 集配置 -
• nanobot 的 memory -
• 核心类 -
• memory 工作流程 -
• nanobot 的 skill -
• skill概念说明 -
• skill 工作流程 -
• nanobot 的 context -
• context概念说明 -
• system prompt 构造逻辑
LLM 接口入参说明
在深入理解 nanobot 的 LLM 参数构造之前,先了解下 LLM 接口的入参格式,以 DeepSeek 的 chat/completions 接口为例,重点需要关注 messages 和 tools:
-
• messages参数:消息列表,即通俗含义的prompt(提示词)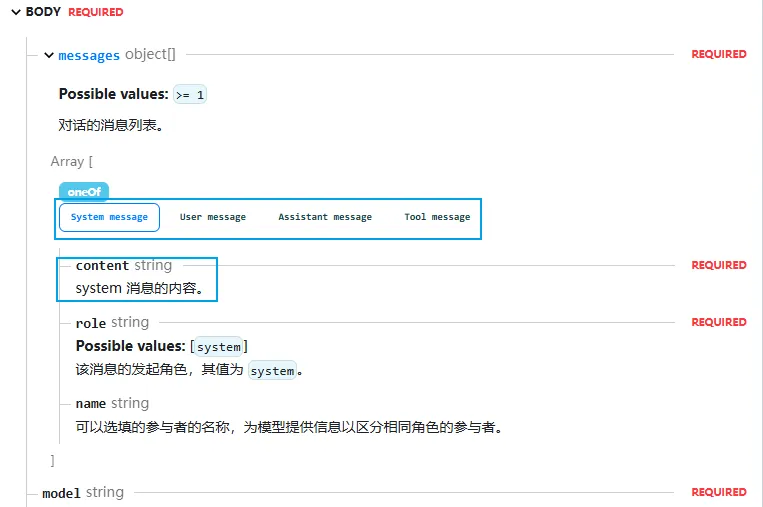
-
• tools参数:可调用的工具列表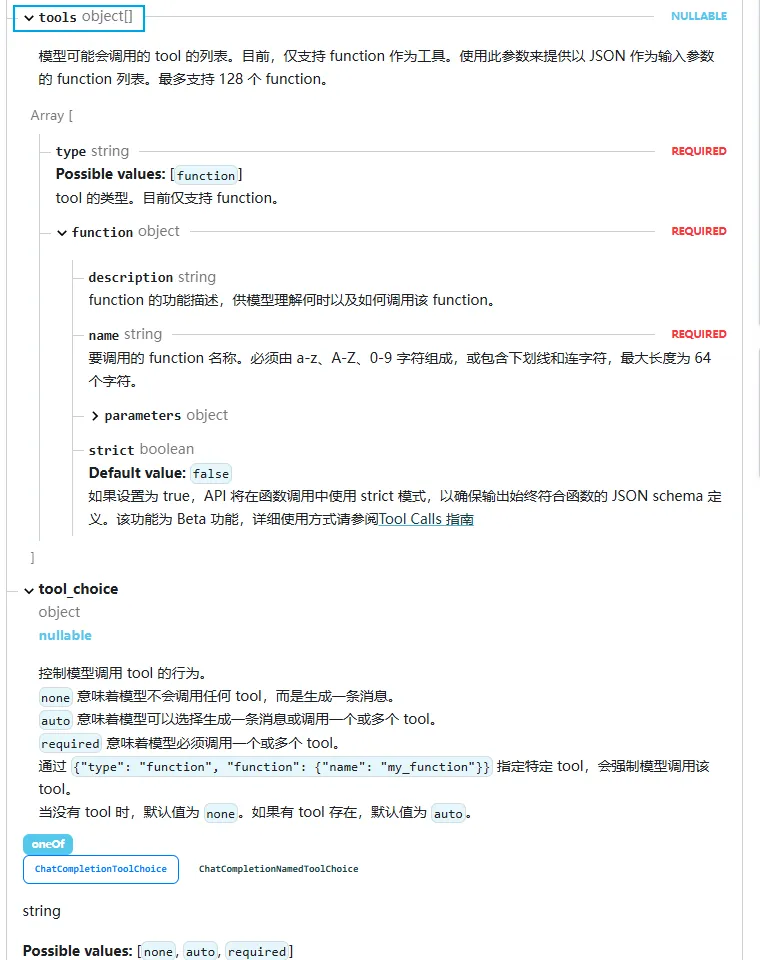
nanobot 的 tool
tool 概念说明
所谓 tool,即作为 LLM API 调用方,告诉 LLM 这里有一个 function:
-
• name: 这个function的名称是什么 -
• description: 这个function能干什么 -
• schema: 要调用这个function需要提供什么参数
插播一下
mcp,全称 Model Context Protocol(模型上下文协议)。mcp是一种标准化的协议,规定了外部进程如何暴露tool,使得不同系统之间能够相互调用工具。通过mcp,工具提供者(mcp server)可以将自己的工具以一种标准化的方式暴露给工具使用者(mcp client)。所以,只要实现了mcp client协议,就可以接入mcp server并使用mcp server暴露的tool。在 nanobot 中,mcp被用来扩展工具能力,允许接入第三方工具服务。
LLM 使用 tool 的工作流程
LLM 使用 tool 的工作流程是:
-
• 调用方按规范(提供 tool列表)调用 LLM API -
• LLM 认为需要执行某个特定的 tool(此时返回值会包含tool的名称和参数值) -
• 调用方使用 LLM 回复的参数去调用 tool对应的function,得到结果 -
• 调用方在 messages字段上追加 LLM 回复的tool执行请求和tool的执行结果,再次调用 LLM API
nanobot 的 tool 实现
nanobot 的 tool 相关代码在 nanobot/agent/tools/ 包下。可以看到,nanobot 定义了很多 tool,现挑选几个进行说明:
-
• ReadFileTool/WriteFileTool/EditFileTool/ExecTool: 读文件/写文件/编辑文件/执行命令,绝大多数 Agent 都会提供这几个工具的实现。 -
• MessageTool: 消息发送,nanobot 的消息发送一般都是在 Agent Loop 流程结束后,如果需要在 Agent Loop 期间发送消息则会调用这个工具。将需要发送的消息直接转换成 OutboundMessage 存入 MessageBus。 -
• SpawnTool: 生成 Subagent,当 Main Agent 遇到复杂任务或者耗时任务时,可以创建 Subagent 后台执行,然后等待 Subagent 执行完成后发送的通知。
tool 集配置
nanobot 通过 ToolRegistry (nanobot/agents/tools/registry.py) 来管控哪些 tool 允许被使用。nanobot 源码中有三个调用 LLM 接口的大类别,其分别为这三类调用设置了不同的 tool 集:
-
• Main Agent:Agent Loop 中的 Main Agent (nanobot/agent/loop.py)。这里的调用几乎添加了所有可用的 tool(包括mcp提供的)。 -
• Subagent:Agent Loop 中的 Subagent (nanobot/agent/subagent.py)。对比 Main Agent,Subagent 没有 mcp的工具集,没有SpawnTool(仅允许 Main Agent 创建 Subagent),没有MessageTool(Agent Loop 流程中的消息发送也只能通过 Main Agent)。 -
• Dream 机制:根据对话历史更新知识库(nanobot/agent/memory.py)。需要读取修改知识库文件,仅配置了 ReadFileTool、WriteFileTool、EditFileTool。
显然,我们观察到了一个工程实践事实:针对不同的场景,需要配置不同的 tool 集。tool 集配置一般考虑:
-
• 能力限制:如 Subagent 不能调用 SpawnTool,可以避免子代理的无限创建 -
• 成本控制: tools参数也会占用 token,减少tool可以降低调用成本 -
• 认知聚焦:如 Dream 机制只需要修改文件,添加无关工具可能干扰核心任务执行
nanobot 的 memory
核心类
memory 的相关代码在 nanobot/agent/memory.py 文件中。这个文件中实现了三个类:
-
• MemoryStore: 构造system prompt时,提供持久化记忆(memory/Memory.md)和未经过持久化处理的近期历史对话消息。 -
• Consolidator: 执行 token 压缩。生成的prompttoken 可能较多,会使用该类尝试消减下 token 数。 -
• Dream: 对历史对话消息做持久化操作。使用大模型提取消息中涉及USER(用户信息等)、SOUL(bot人设等)、MEMORY(上下文知识等)的内容,然后更新对应文件。
memory 工作流程
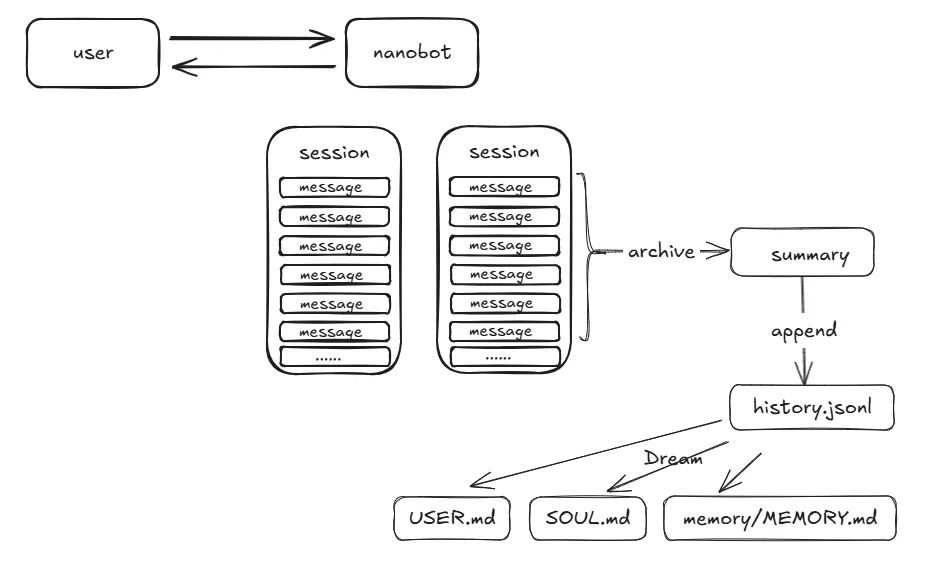
整体流程大概如下:
-
• 满足一定条件后,历史消息会被总结追加到 history.jsonl -
• 定时触发 Dream机制,从history.jsonl中提取持久化记忆
nanobot 的 skill
skill 概念说明
skill 的相关代码在 nanobot/agent/skills.py 文件中。
skill 的最大特征是渐进式披露:最开始只给 LLM 提供 skill 的 name 和 description,若 LLM 认为需要使用对应的 skill,才会要求提供对应的 skill 具体内容。
nanobot 会读取特定目录下的所有可用的 skill,然后将 name、description 等内容拼接成 xml 格式塞到提示词中:
<skills> <skill available=""> <name>这里是skill的name</name> <description>这里是skill的description</description> <location>SKILL.md文件位置</location> </skill></skills>skill 工作流程
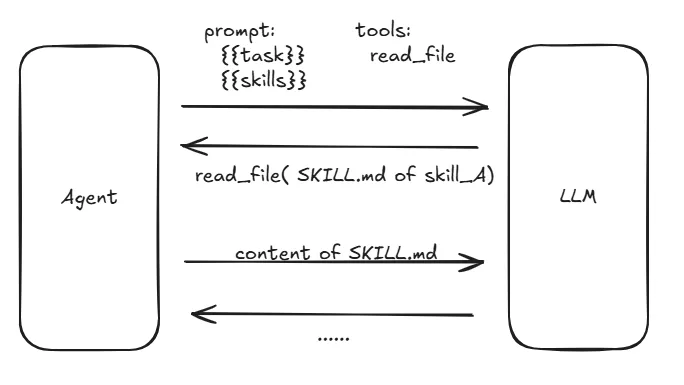
整体流程大概如下:
-
• 将 skill基本信息(含SKILL.md路径)和ReadFileTool提供给大模型 -
• 大模型如认为需要加载 skill,则要求执行ReadFileTool -
• 执行 ReadFileTool读取SKILL.md内容后提供给大模型
nanobot 的 context
context 概念说明
context 的相关代码在 nanobot/agent/context.py 文件中,负责将上述提到的 memory、skill 以及其它上下文信息整合到提示词中。
system prompt 构造逻辑
重点看一下其关于 system prompt 的构造逻辑:
def build_system_prompt( self, skill_names: list[str] | None = None, channel: str | None = None,) -> str: """Build the system prompt from identity, bootstrap files, memory, and skills.""" # nanobot 的默认提示词模板,详见 nanobot/templates/agent/identity.md parts = [self._get_identity(channel=channel)] # 加载固定文件的内容:"AGENTS.md", "SOUL.md", "USER.md", "TOOLS.md" # AGENTS.md: 可以看作是给 Agent 看的 README.md 文件,详见 https://agents.md/ # SOUL.md: 希望 nanobot 具有什么样的"人格" # USER.md: 希望 nanobot 了解的用户信息 # TOOLS.md: 部分 tool 的使用说明 bootstrap = self._load_bootstrap_files() if bootstrap: parts.append(bootstrap) # 上文所说的 memory 部分(持久化记忆) memory = self.memory.get_memory_context() if memory: parts.append(f"# Memory\n\n{memory}") # 上文所说的 skill 部分 # nanobot 允许 skill 在 YAML Formatter 定义 skill 是否一定要被加载,即 always # always 的 skill 会直接把 SKILL.md 内容填充到提示词 # 非 always 的 skill 则只先提供 name、description 等字段,待需要时加载 always_skills = self.skills.get_always_skills() if always_skills: always_content = self.skills.load_skills_for_context(always_skills) if always_content: parts.append(f"# Active Skills\n\n{always_content}") skills_summary = self.skills.build_skills_summary() if skills_summary: parts.append(render_template("agent/skills_section.md", skills_summary=skills_summary)) # 上文所说的 memory 部分(未做持久化处理的历史消息部分) entries = self.memory.read_unprocessed_history(since_cursor=self.memory.get_last_dream_cursor()) if entries: capped = entries[-self._MAX_RECENT_HISTORY:] parts.append("# Recent History\n\n" + "\n".join( f"- [{e['timestamp']}] {e['content']}" for e in capped )) return "\n\n---\n\n".join(parts)