 夜雨聆风
夜雨聆风





把恶意软件改名成 resume.pdf 也没用!谷歌开源「文件识别杀手」Magika,撑起 Gmail/Drive 每周千亿文件第一道门
最近有条推文在疯传:「谷歌开源了 1.7B 参数小模型,能跨 100+ 语言解析文本、表格、公式、图片和 PDF。」听起来很炸,但这个描述——根本对不上 Magika。真正的 Magika,是谷歌内部用了多年、每周处理数千亿文件的 AI 文件类型识别系统,1.0 版本刚用 Rust 重写完,支持 200+ 文件类型,准确率约 99%。它不是 OCR,不是文档解析器,它做的是更底层、更关键的一件事:看穿文件在伪装什么。
先把这个谣言说清楚
这条推文的原文是这样写的:
“someone just open-sourced a 1.7B parameter model that parses text, tables, formulas, images, and PDFs across 100+ languages.”
「有人刚开源了一个 1.7B 参数模型,能跨 100+ 语言解析文本、表格、公式、图片和 PDF。」
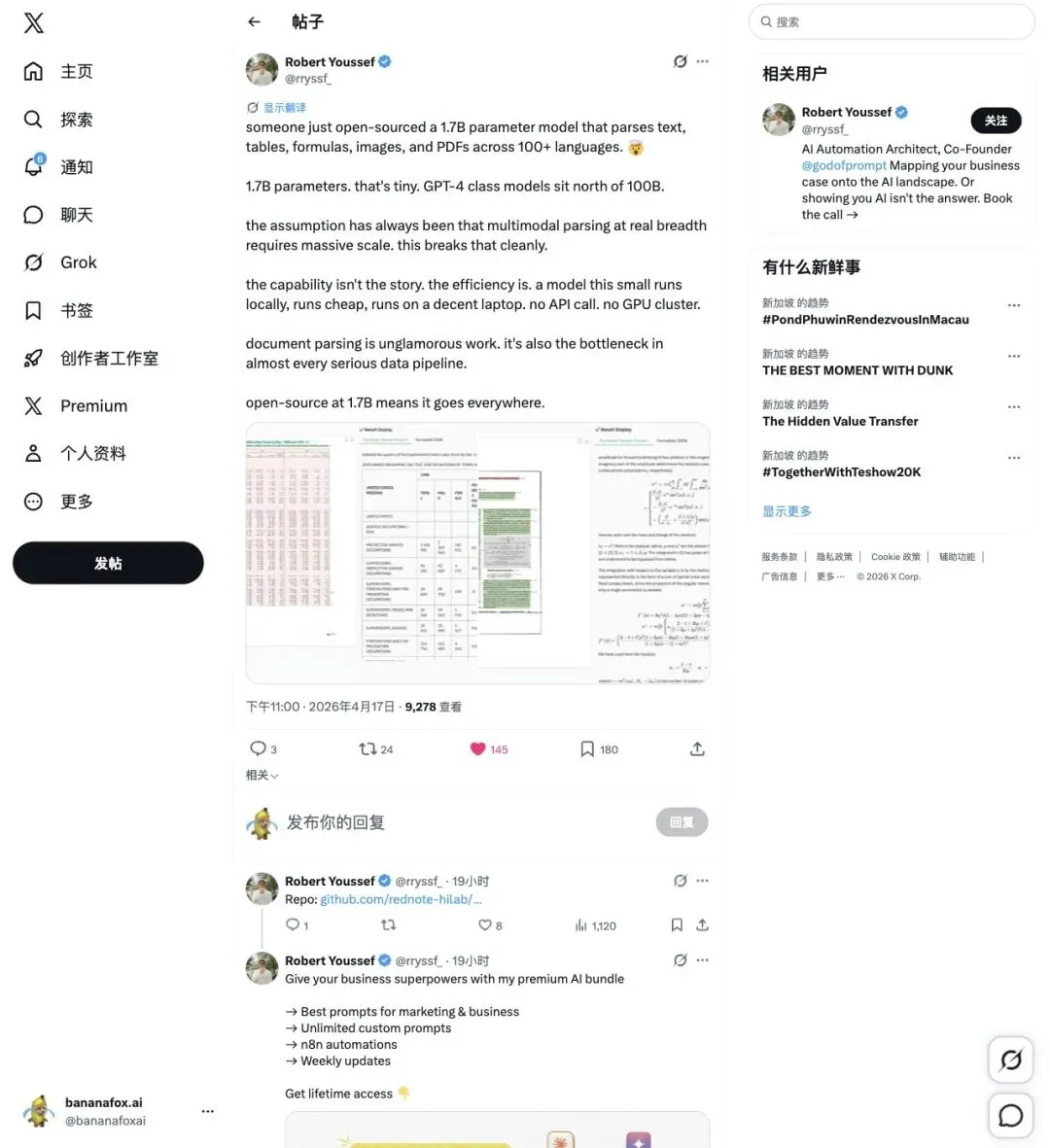
▲ 这条推文把”1.7B OCR/文档解析模型”和 Magika 混在一起传播,约 9200+ 次浏览
问题在于,这套描述和 Magika 官方资料一个字都对不上。
谷歌官方博客的第一句话是:
“Today we are open-sourcing Magika, Google’s AI-poweredfile-type identificationsystem.”
「今天我们开源 Magika,谷歌的 AI 驱动文件类型识别系统。」
GitHub README 的标题是:
“Fast and accurate AI poweredfile content types detection“
「快速、精准的 AI 驱动文件内容类型检测」
Magika 回答的问题是”这是什么文件”,不是”这个文件里写了什么”。
这两件事紧邻,但不是一回事。
那 Magika 到底在做什么
把一个文件上传到系统,平台首先要决定:
-
它是图片、文档、脚本,还是可执行文件? -
应该送去哪个扫描器? -
能不能渲染?要不要高危拦截? - 如果文件扩展名是假的,系统能不能看穿?
最后这个问题,才是 Magika 存在的理由。
社区里传播最广的一句话,来自 @_vmlops 的推文,7074 个赞,近 48 万次浏览:
“rename malware to ‘resume.pdf’? magika sees through it”
「把恶意软件重命名成 resume.pdf?Magika 也能看穿。」
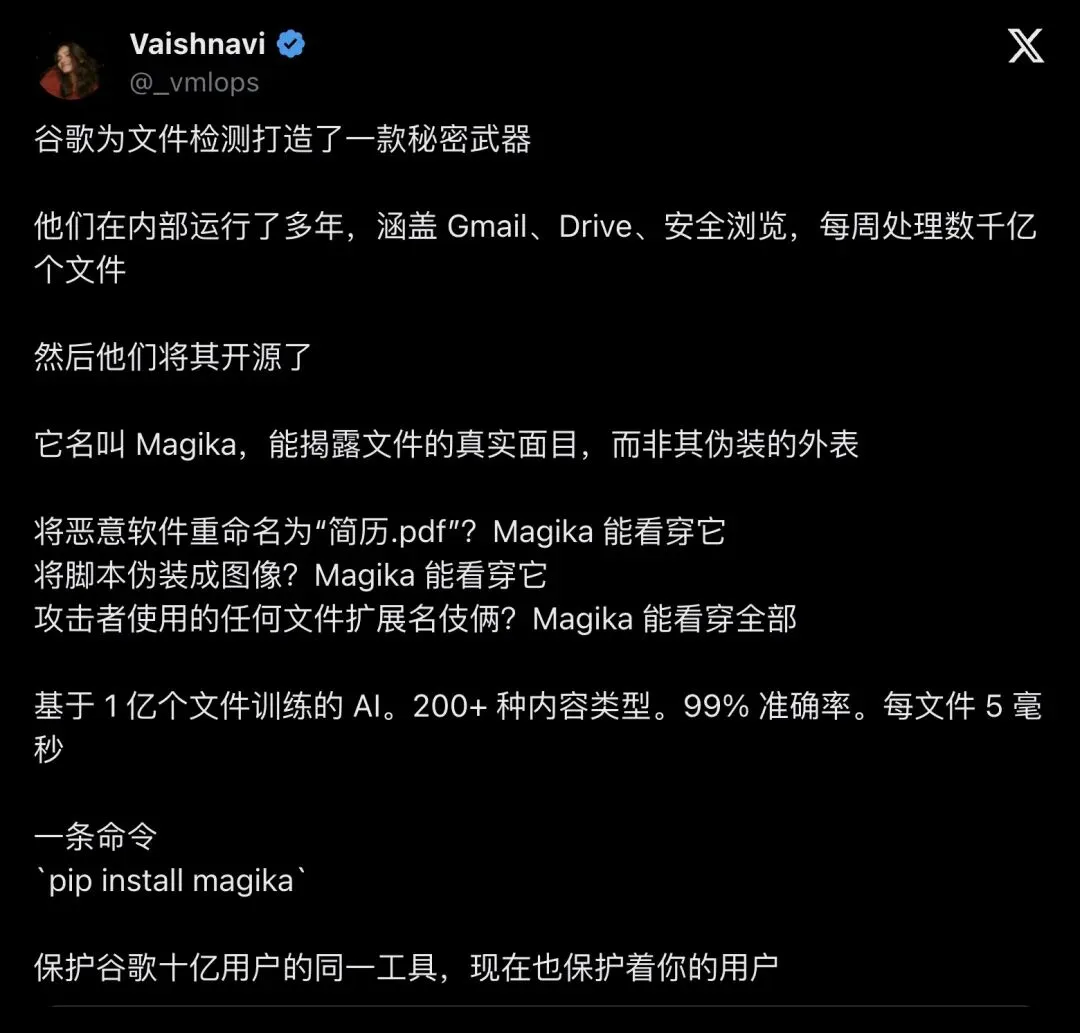

▲ @_vmlops 推文,7074 likes / 927 reposts / 479826 views
这句话把 Magika 的价值说得比任何技术文档都清楚。
谷歌内部用了多年,才决定开源
Magika 不是一个实验室 demo。
谷歌官方公开披露:它已经在内部用于Gmail、Google Drive、Safe Browsing,每周平均处理数千亿个文件。
和旧的手工规则系统相比:
-
文件类型识别准确率提升50% -
让专用恶意文档扫描器多覆盖11%的文件 -
无法识别的文件比例压到3%
这不是”酷 demo”,而是一个在真实安全流量里跑了多年的底层系统。
2024 年 2 月,谷歌把它开源。
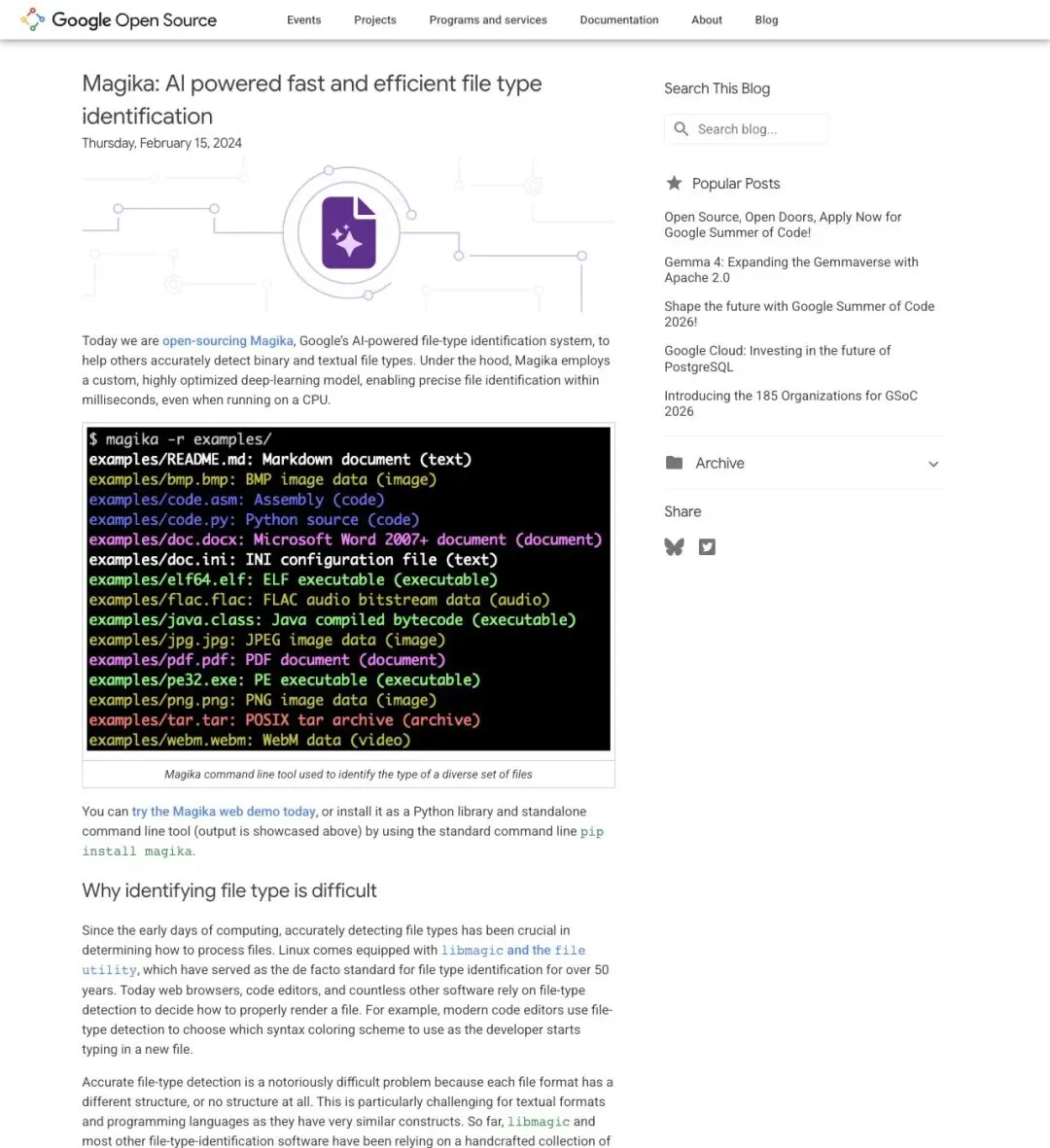
▲ Google Open Source Blog 2024 年 2 月开源公告
Hacker News 第一天就拿到695 points / 251 comments,开发者社区的反应是:「这东西我们等了很久了。」
模型有多小,速度有多快
这里有个反直觉的地方。
Magika 的模型权重,大约只有 1MB。
不是 1.7B 参数,不是几十 GB,是1MB。
但它能做到:
-
覆盖200+ 种文件类型 -
在约 1 亿样本的测试集上,平均准确率约99% -
单 CPU 上,单文件推理时间约5ms -
M4 MacBook Pro 上,接近每秒 1000 个文件
这就是为什么它能进 Gmail 和 Drive 的生产链路——它足够快,足够准,足够小。
1.0 版本:Rust 重写,支持类型翻倍
2025 年 11 月,谷歌发布 Magika 1.0。
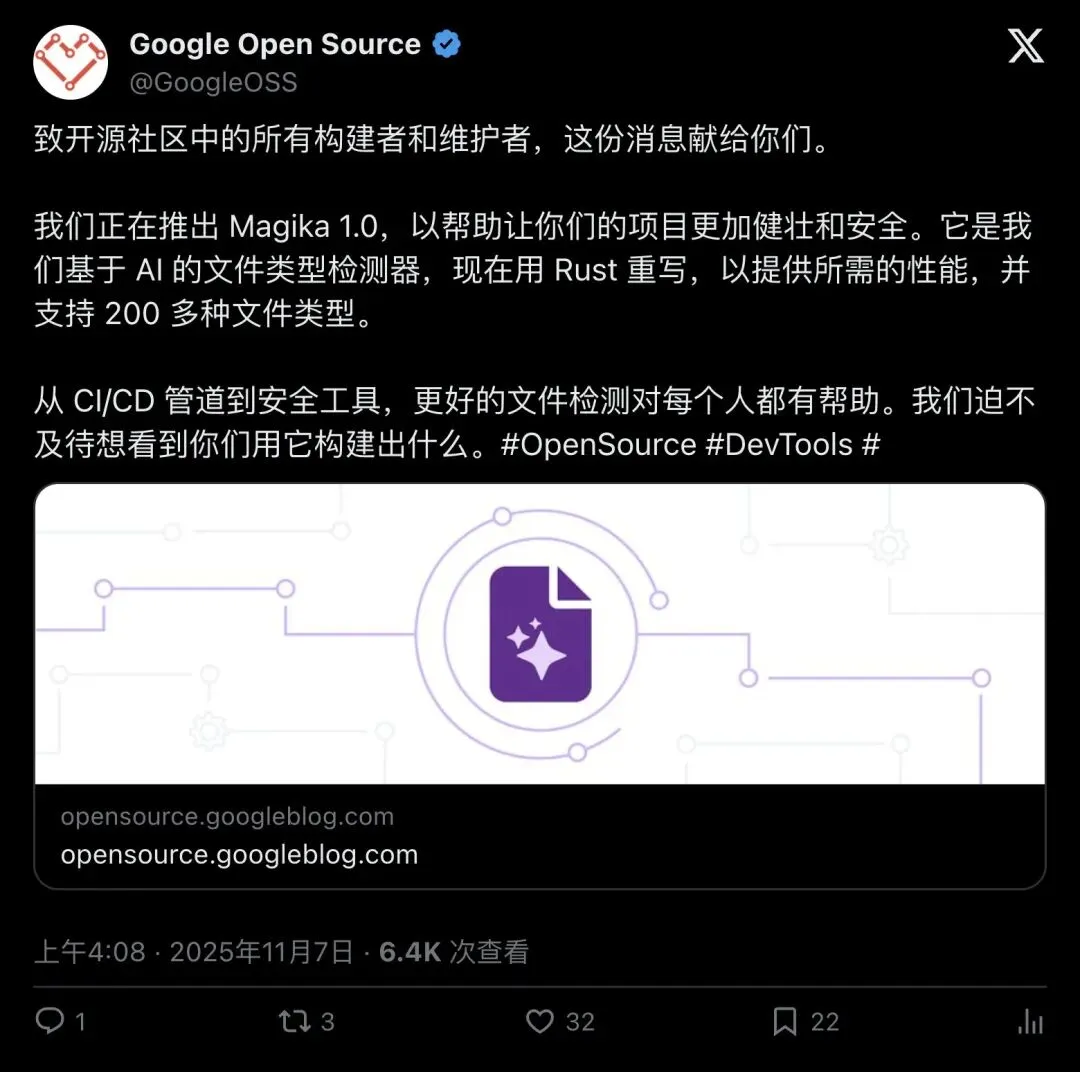
▲ @GoogleOSS 发布 Magika 1.0 公告
核心变化有四个:
第一,支持文件类型从 ~100 扩到 200+。
新增了大量现代工程场景里的类型:
-
数据科学/ML:`ipynb`、`pytorch`、`onnx`、`parquet`、`h5` -
现代语言:`swift`、`kotlin`、`typescript`、`dart`、`solidity`、`wasm`、`zig` -
DevOps/配置:`dockerfile`、`toml`、`hcl`、`bazel`、`yara` -
数据库/图形:`sqlite`、`dwg`、`psd`、`woff`
第二,核心引擎用 Rust 重写。
“A brand-new, high-performance engine rewritten from the ground up in Rust.”
「全新的高性能引擎,从零开始用 Rust 重写。」
内存安全更强,更适合在安全场景里被大规模集成。
第三,训练数据规模升级。
训练数据解压后超过3TB,约1 亿个样本。对稀缺格式,谷歌用Gemini 生成高质量合成训练数据,再结合增强技术补齐长尾类别。
第四,已有 100 万月下载量。
不是实验室项目,是真实在用的工程组件。
它已经进了安全生态
Magika 不只是一个命令行工具。
它已经接入VirusTotal和abuse.ch这类安全生态,作为前置识别层,在文件进入专用扫描器之前,先判断”这是什么”。
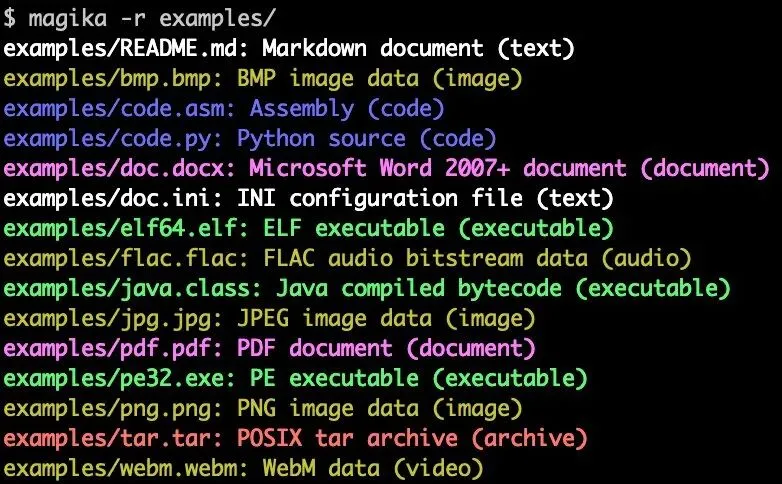
▲ Magika CLI 输出示例,一行命令识别文件真实类型
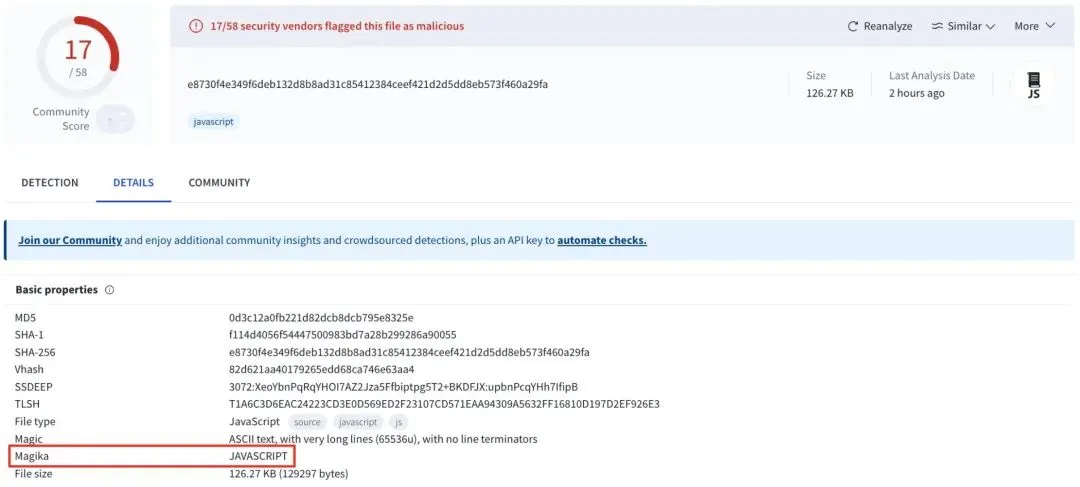
▲ Magika 在 VirusTotal 中的集成
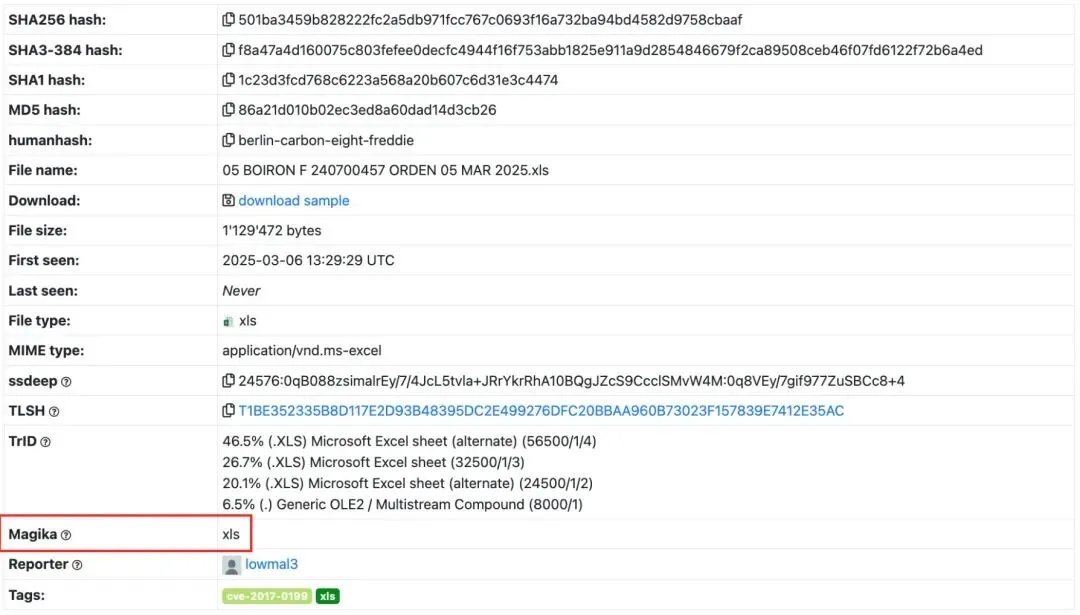
▲ Magika 在 abuse.ch 中的集成
GitHub 仓库 `google/magika` 目前已有 13000+ stars,提供 Rust CLI、Python API、JS/TS 包,一行安装:
“` pip install magika “`
它不是神,但已经非常实用
安全研究员 Somdev Sangwan 在 2024 年底发布了一篇绕过文章《Bypassing Google’s Magika & Bullying AI》。
他展示了一个案例:构造一个 `.ps1` 脚本,让 Magika 以100% 置信度把它识别成 Python。
“Despite the .ps1 extension, Magika detected this script as Python with 100% certainty.”
「尽管扩展名是 .ps1,Magika 仍以 100% 确信度把它识别成了 Python。」
这说明 Magika 不是无懈可击的。规则库会被绕过,AI 模型一样会被绕过。
但这不是否定它的理由。
谷歌的设计里,Magika 本来就不是”最终裁判”,而是前置识别层 / 路由层——帮系统把文件送去更合适的扫描器,在平均效果、长尾文本类型、规模化速度上,明显比传统方案更实用。
这才是这件事真正值得写的地方
Magika 挑战的对象,是 `libmagic` / `file` 这类有50 多年历史的规则库范式。
传统方案靠的是人工维护的”文件头签名数据库”——每新出一种文件格式,就要有人手动写规则。碰到纯文本、脚本、配置文件、混淆代码,就容易吃力。
Magika 的意义不在”模型参数大”,而在:
一个很小的模型,能在 CPU 上高效替代一大块人工规则。
这是 AI 进入基础设施层的典型路径——不是前台聊天机器人,不是生成内容,而是悄悄替换掉几十年的规则系统,让整个链路更准、更快、更难被绕过。
安全行业比内容行业更早、更务实地把 AI 用在了生产链路上。
Magika 就是证据。
— END —