 夜雨聆风
夜雨聆风





OpenClaw系列第9课:Memory 机制 – 如何让 AI 记住你的事
这是「OpenClaw 教程课程」第 9 课。 前一课我们讲了 Context Engine,知道了模型到底“看到了什么”。这节课继续回答另一个很多人最关心的问题:OpenClaw 到底是怎么记住事情的?

图:Memory 不是临时上下文延续,而是把真正值得长期保留的信息沉淀下来。
很多人第一次用 OpenClaw,都会很自然地问:
-
它会记住我之前说的话吗? -
为什么有些事它下次还记得,有些又像忘了? -
Session 和记忆到底是不是一回事? -
我能不能让它长期记住我的偏好、项目背景、固定写作要求?
这些问题背后,其实都指向一个核心概念:
Memory。
但这里最容易搞混的一点是:
OpenClaw 的“记住”并不只有一种。
它至少涉及两层:
-
当前 Session 里的连续上下文 -
更长期、可被反复检索的 Memory
所以今天这节课,我们要讲清楚的不是一句“它能记住”,而是:
它到底记住了什么、怎么记、记在哪里、什么时候该记。
一、先说结论:Memory 不是聊天上下文的延长线,而是“长期可检索记忆”
这是今天最重要的一句话。
很多人会把 Memory 理解成:
-
聊天记录放久一点
这个理解不够准确。
更准确的理解应该是:
Memory 是从大量交互信息里,抽取出真正值得长期保留的内容,再写入一个可被以后检索的记忆层。
也就是说,Memory 不是把所有聊天原样堆着不动,而是更像一种“沉淀”。
它保留的通常不是所有细节,而是这些更值得长期保存的东西:
-
你的偏好 -
你的身份信息 -
固定项目背景 -
长期有效的工作方式 -
持续性的任务线索 -
明确确认过的约定
这就是为什么 Memory 和 Session 不是一回事。
二、Session 和记忆,到底差在哪?
你可以先用一句最容易记住的话来区分:
Session 管“当前这段对话”,Memory 管“未来还值得再拿出来用的事实”。
Session 更像短期工作台
它负责:
-
当前这轮对话的连续性 -
你刚刚说过什么 -
这次话题现在进行到哪 -
当前运行时的即时上下文
它的特点是:
-
更临时 -
更依赖当前交互 -
会被 /new、重置、生命周期切断
Memory 更像长期资料卡
它负责:
-
以后仍然可能有价值的信息 -
可以被检索出来重复使用的信息 -
不应该只留在一次聊天里的内容
它的特点是:
-
更稳定 -
更长期 -
更偏“提炼后的事实”

图:Session 更像当前工作台,Memory 更像长期资料卡。两者都重要,但作用完全不同。
三、为什么不能只靠 Session?
因为 Session 再长,也不是长期记忆系统。
如果你只靠 Session,会遇到这些问题:
-
会话一重置,上下文就断了 -
旧内容太多,会让上下文越来越臃肿 -
真正重要的信息会被淹没在大量临时聊天里 -
同一件长期有效的事,得反复重新说
举个最典型的例子:
如果你每次都要重新告诉它:
-
你的网站是 Hexo -
文章默认中文 -
你喜欢直接给完整 .md文件 -
配图提示词要用中文 -
时间按北京时间写
那就说明这些东西不应该只留在 Session 里,而应该进入更长期的记忆层。
所以 Memory 的价值就在这里:
把“反复要重新说”的东西,变成“以后可以直接调出来”的东西。
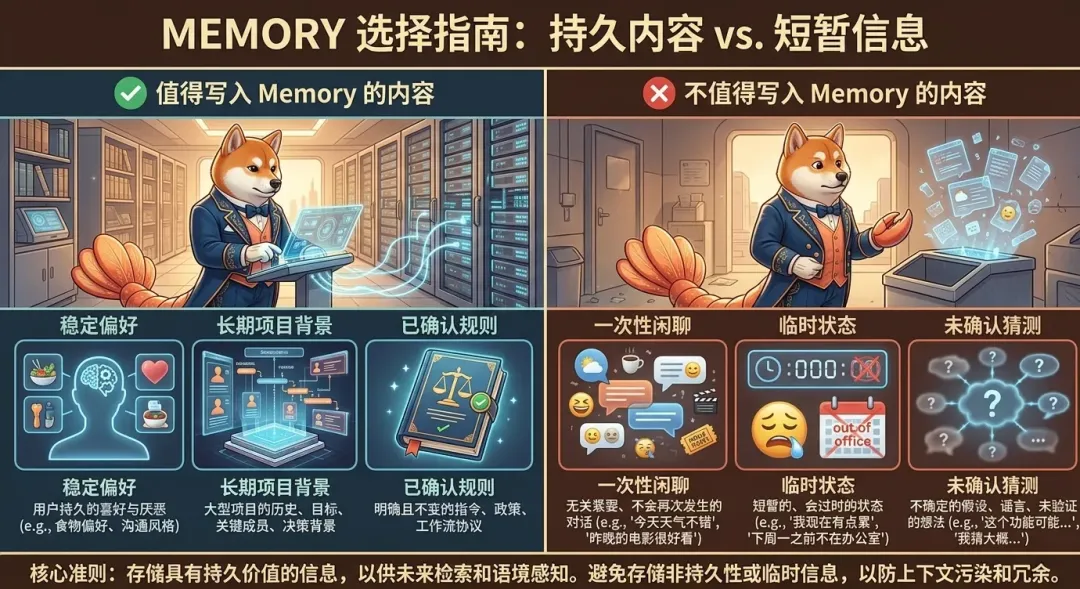
四、什么样的信息值得写进 Memory?
这一步特别重要。
并不是所有东西都值得记。
如果什么都记,Memory 就会变成新的噪音堆。
更适合进入 Memory 的内容,通常有以下几类:
1)稳定偏好
例如:
-
默认用中文输出 -
时间按北京时间写 -
文章要适配 Hexo -
生图提示词要用中文 -
正文里标注插图位置
这类内容的特点是:
-
会反复用到 -
不是一次性的 -
对后续输出持续有影响
2)身份与关系信息
例如:
-
用户怎么称呼 -
你和对方已经确认过的合作方式 -
某些长期身份设定
3)长期项目背景
例如:
-
某个博客长期写作计划 -
某个教程系列的固定结构 -
某个工作区要长期遵守的产出约束
4)已经明确确认过的重要决定
例如:
-
课程清单已经确认 -
某种格式已经统一 -
某个流程以后固定按这个来
五、什么内容不应该轻易写进 Memory?
同样重要的是:知道什么不该记。
这些通常不适合直接进入长期记忆:
1)一次性闲聊
例如:
-
某次随手吐槽 -
当天临时感想 -
不会复用的小话题
2)会快速过期的信息
例如:
-
临时状态 -
短期测试结果 -
今天有效、明天就没用了的数据
3)还没确认的推测
例如:
-
可能以后会怎样 -
也许想改成什么 -
尚未最终决定的方案
4)过于细碎、没有复用价值的内容
Memory 不是全文聊天备份。
它更像是:
从大量内容里筛出“以后值得再次提取”的信息。
六、Memory 更像“可检索事实层”,不是“完整人生档案”
这点一定要讲清楚。
有些人一听“长期记忆”,就会自然想成:
-
一个超级完整的个人数据库
但在 OpenClaw 里,更合适的理解其实是:
Memory 是面向未来使用的事实层。
也就是说,它的目标不是“什么都留”,而是“以后需要时能被重新找到并拿来用”。
所以它更强调:
-
可检索 -
可复用 -
有持续价值 -
足够明确
而不是:
-
巨量堆积 -
无差别保留
七、为什么说 Memory 是“提炼”而不是“复制”?
因为长期记忆真正值钱的地方,在于提炼。
比如下面两种写法:
不够好:原样复制
-
2026-04-19 用户说以后文章里的时间要写北京时间
更好:提炼成长期规则
-
用户偏好:以后文章、日志时间、示例时间默认按北京时间(UTC+8)书写
第二种更适合长期记忆。
因为它具备:
-
更清晰的抽象 -
更稳定的表达 -
更容易在未来被重新使用
所以你以后理解 Memory,最好不要把它想成“存一段聊天原文”,而是:
把聊天里真正稳定的部分,提炼成以后还能用的规则或事实。
八、Memory 和 Context Engine 是怎么连起来的?
前一课讲过,Context Engine 负责决定模型“看到了什么”。
那 Memory 在这里扮演什么角色?
很简单:
Memory 是 Context Engine 未来可能取用的一部分长期背景来源。
也就是说,Memory 本身不是当前输入框,但它可以在后续需要时,被检索出来重新注入上下文。
所以两者的关系可以这样理解:
-
Memory:长期保存 -
Context Engine:按需取用并装配
这就解释了为什么:
-
有些事它以后还记得 -
不是因为 Session 永远没断 -
而是因为长期记忆层被重新检索到了

图:Memory 负责长期保存,Context Engine 在未来运行时按需把它重新取出来。
九、如何判断一条信息值不值得记?
这里给你一个特别实用的判断标准。
你可以问自己下面 3 个问题:
1)这条信息以后还会反复影响输出吗?
如果会,值得考虑记。
2)这条信息是不是已经明确确认过?
如果还没确认,先别急着记。
3)如果下次还得重新说一遍,会不会很浪费?
如果会,那它大概率就有记忆价值。
把这三个问题记住,你以后就不会乱把什么都塞进 Memory。
十、你可以把 Memory 理解成“长期工作备忘卡”
这是一个很适合新手的类比。
不是完整档案馆,也不是原始聊天备份。
而更像是:
-
长期偏好卡 -
项目背景卡 -
规则说明卡 -
已确认事项卡
所以它的价值在于:
帮助系统在未来更快进入正确状态,而不是把过去一切都无差别保留。
十一、这一课最值得记住的一句话
如果今天只记一句话,我建议你记这句:
Memory 记住的不是所有对话,而是以后仍然值得再次被取用的事实。
这句话一旦理解了,后面很多事都会顺:
-
你知道什么该记 -
你知道什么不该记 -
你知道为什么 Session 和 Memory 不能混为一谈
十二、总结
今天这节课,你只要真正记住下面 5 句话,就够了:
-
Memory 不是 Session 的延长线,而是长期可检索记忆。 -
Session 管当前连续对话,Memory 管未来仍然有价值的事实。 -
不是所有内容都值得记,真正该记的是稳定、可复用、已确认的信息。 -
Memory 更强调提炼,而不是原样复制聊天内容。 -
Memory 会在未来通过 Context Engine 被重新取用。
下一课预告
下一课我们会学:
第 10 课:模型配置与切换(providers / failover)
也就是开始进入一个很多人非常关心的主题:
-
OpenClaw 到底怎么接不同模型 -
为什么有时候会 fallback -
主模型和备用模型怎么理解 -
切换模型到底是在切什么
🦞 本文由八条撰写,持续更新中。