 夜雨聆风
夜雨聆风





文档解析,别总怪大模型不好用,90%的问题都出在这一步
关注”东哥说AI“,持续分享大模型应用实战经验。
你有没有遇到过这种情况:
把公司的合同、报告或者产品手册丢给AI,让它帮你找信息,结果它给的答案要么牛头不对马嘴,要么说”文件中没有相关内容”——明明你亲眼看到那个数字就在第三页。
这不是大模型不够聪明,也不是你的提示词有问题。很多时候,问题出在一个经常被忽视的环节——文档解析。
准确来说,是AI根本没把你的文件”读进去”。
为什么PDF对AI来说那么难
这个问题我以前也没深想过,直到真正开始做企业AI项目才发现:PDF这个格式,对人来说用起来很方便,对AI来说处理起来真的很麻烦。
一份普通的PDF里面,往往混着多种内容——分栏的文字段落、合并了行列的复杂表格、嵌入的图片图表、数学公式,还有扫描件(本质是一张图片,里面没有任何可以直接读取的文字)。这些内容夹在一起,没有统一的格式,也没有固定的位置规律。
用最基础的代码库直接”读”PDF,出来的效果经常是:段落顺序乱了,表格变成了乱七八糟的文字,图片里的关键数据根本提不出来。这样的数据,你再怎么优化大模型,答案也不会对。
所以,文档解析做不好,后面的AI应用都是浮沙上建楼。
很多企业项目做了半天发现效果差,一层层排查下去,根子就在这里。
OCR在2025年变了什么
说到OCR,很多人第一反应还是”识别发票上的文字””扫描身份证”。这是OCR很长时间里的主要用法——认字符。
但从2025年开始,这个领域集中爆发了一批新模型,把OCR的能力边界往前推了一大步。
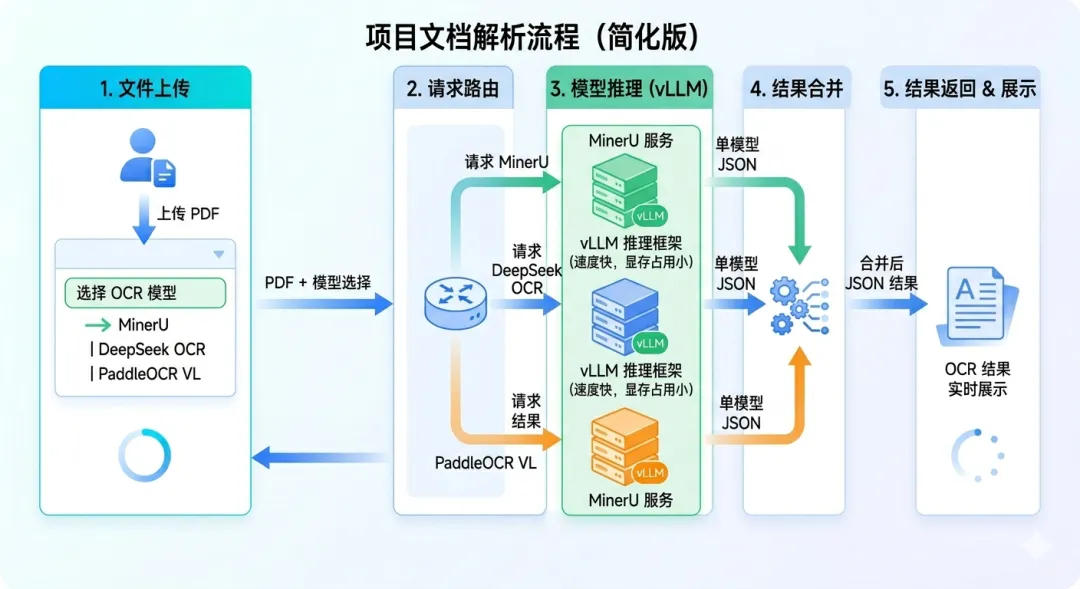
这批新模型做的事情不只是”认字”,而是理解整个文档的结构。它能告诉你:这是一个标题,那是一段正文,这里有个表格,表格下面是说明文字,这张图是流程图……然后把整个文档按照人类正常的阅读顺序重新整理出来,最终转成markdown或JSON格式输出。
有了这样结构化的数据,才能让大模型真正”读懂”你的文件,后续无论是做知识库问答还是自动化处理,都有了可靠的原材料。
这是一个挺关键的变化,但知道的人不多。

三个目前最主流的开源方案分别是:
MinerU(上海人工智能实验室出品)——做法类似流水线,先分析页面布局,把不同区域分别框出来,再按阅读顺序重排,最后统一输出。新版本还能直接用视觉语言模型”看图理解文档”,在网页PDF、带广告内容的文件里过滤效果不错,综合准确率大概在92%-95%。
PaddleOCR(百度飞桨)——GitHub上关注度最高的OCR项目之一,今年年初发布的PaddleOCR-VL版本,参数量只有0.9B,非常轻,但在业界权威评测集上达到了94.5%的精度。它把布局检测和内容识别分两步做,推理速度在三者里最快,显存占用也低。
DeepSeek OCR——DeepSeek出的轻量级专用模型,7G显存就能跑,表格识别和公式提取做得不错。官方文档简单,但社区热情很高,有很多人在探索各种用法。
企业里,这东西实际用在哪
讲完模型,说说真实的落地场景。
财务和法务是目前跑得最多的方向。批量处理发票、合同,把关键字段提取出来自动录入系统,或者让AI帮你找合同里的风险条款——这些需求以前要花大量人力,现在结合文档解析和大模型,基本可以实现半自动化。
企业知识库是更普遍的场景。几乎每家公司都有大量文档积累,产品手册、技术规范、历史报告……这些内容一直躺在文件夹里用不起来。要想让大模型能回答基于这些内容的问题,第一步就是把这些文档解析成可用的数据。这一步做好了,知识库的效果才有保证。
学术和研究场景里,主要是处理大量论文PDF。论文里的图表、公式、参考文献,对解析精度要求很高,稍微有偏差就会影响后续分析的准确性。
几个选型时会遇到的实际问题
三个方案各有侧重,选哪个取决于你自己的情况。
如果文件以数字原生PDF为主(就是用Word或其他软件直接导出的PDF,不是扫描的那种),三个方案差距不大,可以都试试。
如果有大量扫描件、拍照图片,或者要处理手写内容,PaddleOCR的覆盖场景更全一些。
显存资源有限,DeepSeek OCR是比较省资源的起点。
有一个坑要说:很多人用了OCR模型,觉得效果不好就直接换工具,其实很多时候问题不是工具的问题——图片分辨率不够、输入格式预处理有问题、切分策略不对,这些都会让效果大打折扣。同一个模型,优化前后差距可以非常大。遇到效果不理想,先检查自己的使用方式,别急着否定工具。
从实际落地来看,文档解析是那种”不注意不知道,踩过一次就忘不了”的坑。
很多项目在早期设计阶段把它当成”基础配置”随手一搞,结果上线以后AI的回答总是不对,排查了半天才发现问题在最开始那步。
好消息是,现在开源社区里已经有了相当成熟的方案,门槛没那么高。把这件事真正做对,也就是时间和耐心的问题。
这一步打好,后面才能顺。