 夜雨聆风
夜雨聆风





AI 的 skill 到底是什么?
如果你最近老听到 skill 这个词,但一直没搞明白它到底是什么。
尤其如果你正准备自己做一个 skill,或者你正在了解 skills 的组成,你可以通过这篇文章搞明白它。
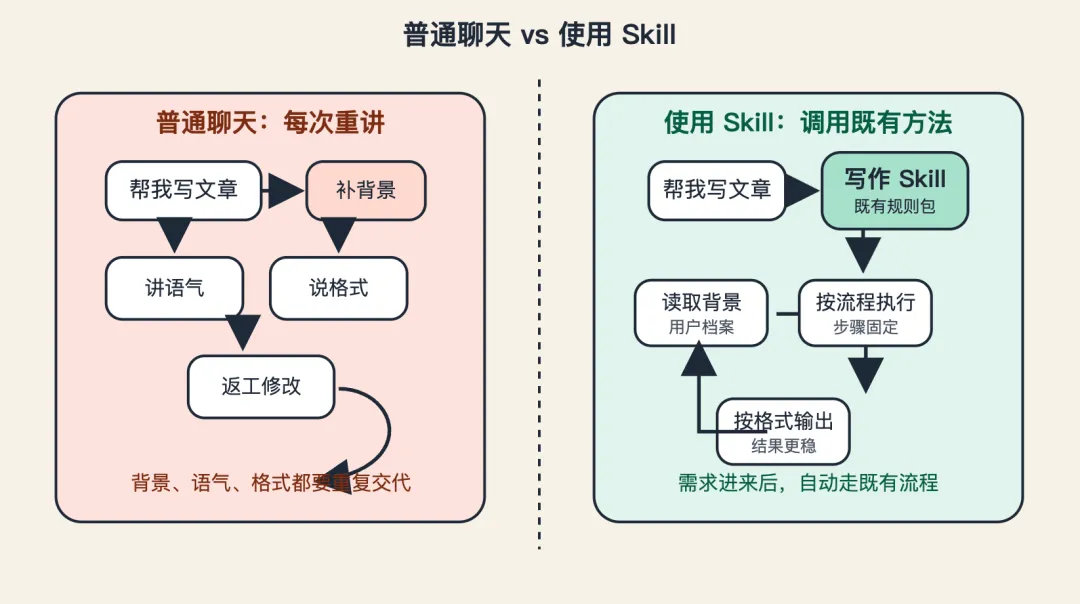
skill 不是一句提示词。
skill 更像是一份给 AI 的任务说明书,或者说,一本小型操作手册。
它解决的不是“这次怎么回答”,而是“以后遇到这一类任务,你该按什么流程做”。
比如你每次都让 AI 帮你抓网页、整理知识库、改口播稿、转公众号排版。
如果每次都重新解释一遍,AI 当然也能做。
但它每次都要重新猜你要什么,重新猜你习惯什么格式,重新猜你这套流程分几步。
这时候,skill 的价值就出来了。
你把这类重复任务,写成一个独立的能力包。
下次只要用户说中了这个场景,AI 就会加载这套说明,再去做事。
所以 skill 的本质,不是聊天。
是把“临时发挥”,变成“可复用流程”。
一、skill 里面到底装了什么?
先看最小结构。
一个 skill 文件夹,最少只要一个文件:
my-skill/└── SKILL.md这个 SKILL.md 是必需的。
没有它,就不算一个完整 skill。
它里面通常有两部分。
第一部分是 frontmatter,也就是最上面的 YAML 信息。
最关键的通常是两个字段:
-
• name -
• description
name 是 skill 名。
description 不是给人看的宣传语,它更像触发说明。
你要在里面写清楚:
-
• 这个 skill 是干什么的 -
• 用户在什么场景下会用到它 -
• 用户可能会怎么说
因为 AI 平时先看到的,往往就是这部分描述。
它会先根据描述判断:这个 skill 要不要触发。
第二部分就是正文,也就是具体使用说明。
你可以把它理解成:
这个 skill 的工作边界、执行步骤、注意事项、引用哪些参考文件,都写在这里。
二、为什么很多 skill 不只有一个 SKILL.md?
因为真实任务通常不止一段说明就够了。
常见结构大概长这样:
skill-name/├── SKILL.md├── agents/│ └── openai.yaml├── scripts/│ └── xxx.py├── references/│ └── xxx.md└── assets/ └── xxx-template.md这里我一个个讲。
1. SKILL.md
这是入口文件。
AI 先靠它判断要不要用这个 skill。
真的触发以后,再按这里面的说明继续读取别的文件。
所以 SKILL.md 要做两件事:
第一,讲清楚这 skill 解决什么问题。
第二,告诉 AI 什么时候该去读 references/,什么时候该跑 scripts/。
2. agents/openai.yaml
这个一般不是所有 skill 都有。
它更偏界面层元数据。
比如技能列表里显示什么名字、短描述是什么、默认提示词是什么。
如果你只是本地先做一个能用的 skill,这一层不是第一优先级。
但如果你想把 skill 做得更规范,或者要接技能市场、技能面板,这个文件会很有用。
3. scripts/
这个目录放的是可执行脚本。
为什么要单独放?
因为有些动作,靠文字解释不够稳。
比如:
-
• 转文件格式 -
• 批量处理图片 -
• 解析某种固定结构的数据 -
• 跑一个反复会用到的自动化步骤
这种时候,把逻辑写进脚本,比每次让 AI 临场现写更稳,也更省 token。
4. references/
这个目录很重要。
它放的是参考资料,不是直接输出物。
比如:
-
• API 文档 -
• 路由规则 -
• 领域知识 -
• 风格说明 -
• 复杂工作流拆解
为什么不把这些全塞进 SKILL.md?
因为太长了。
skill 不是写得越多越好。
真正好的 skill,通常是入口短一点,详细材料按需去读。
这样上下文更干净,AI 判断也更稳。
5. assets/
这个目录放的是产出时要用到的资源。
比如模板、样式、图标、示例文件、样板文档。
它跟 references/ 的区别是:
references/ 更像拿来看的。
assets/ 更像拿来用的。
三、skill 到底怎么用?
这里很多人容易误会。
skill 不是你手动点开一个文件夹,再复制里面的提示词。
更常见的用法是:
AI 先看 skill 的描述。
如果用户当前请求命中了这个场景,它就自动触发。
触发以后,再去读 SKILL.md 正文。
如果正文里还写了:
-
• 去读哪个 references/*.md -
• 去运行哪个 scripts/* -
• 去调用哪个模板
它再继续往下走。
所以 skill 的使用链路,通常是这样的:
用户提需求-> AI 判断哪个 skill 相关-> 读取 SKILL.md-> 按需读 references/-> 按需跑 scripts/-> 生成结果
这也是为什么 skill 适合做重复任务。
因为它不是把答案存起来。
它是把做法存起来。
四、那我怎么创建第一个 skill?
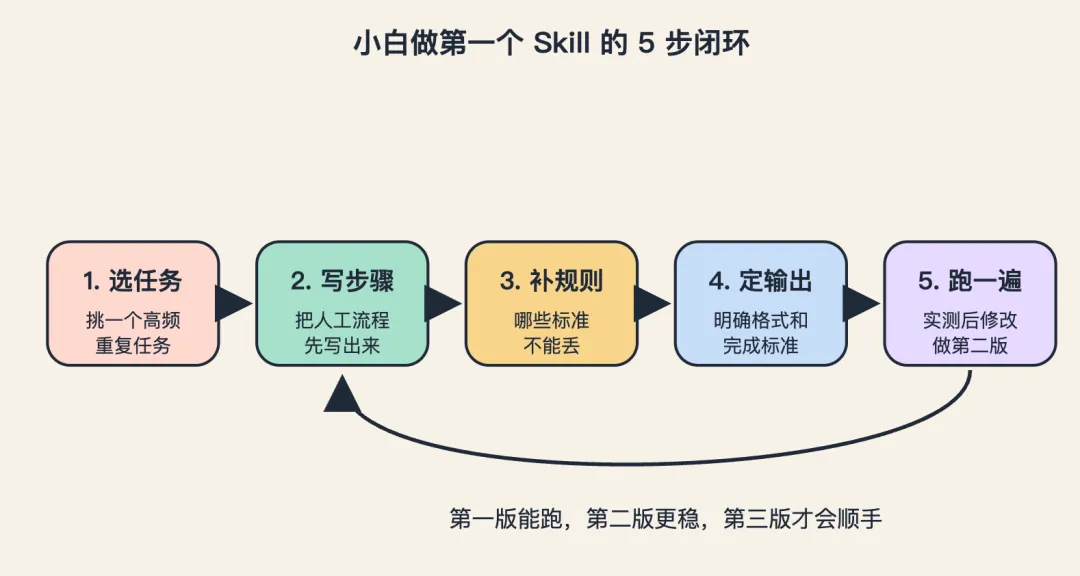
如果你第一次做,我建议你别上来就做一个很大的。
先做最小闭环。
就三步。
第一步,先选一个你已经重复做过 3 次以上的任务。
比如:
-
• 把网页存成 markdown -
• 把口播稿改成公众号版 -
• 把会议纪要整理成待办 -
• 把一篇文章做成白板脚本
别选太大、太泛的任务。
“帮我做内容运营”这种太大了。
“把文章改成视频口播稿”这种就比较合适。
第二步,新建一个 skill 文件夹,只写一个 SKILL.md。
像这样:
my-first-skill/└── SKILL.mdSKILL.md 先写四样东西就够了:
-
1. 这个 skill 是干什么的 -
2. 在什么场景下触发 -
3. 执行步骤是什么 -
4. 输出格式是什么
先别追求豪华结构。
先让它能用。
第三步,跑几次真实任务。
如果你发现:
-
• 某段说明太长 -
• 某类知识经常要反复看 -
• 某个步骤每次都一样
再拆。
比如把长说明拆到 references/。
把稳定动作拆到 scripts/。
把模板拆到 assets/。
这才是比较自然的创建顺序。
不是先搭一棵很漂亮的目录树。
而是先跑通,再分层。
总结
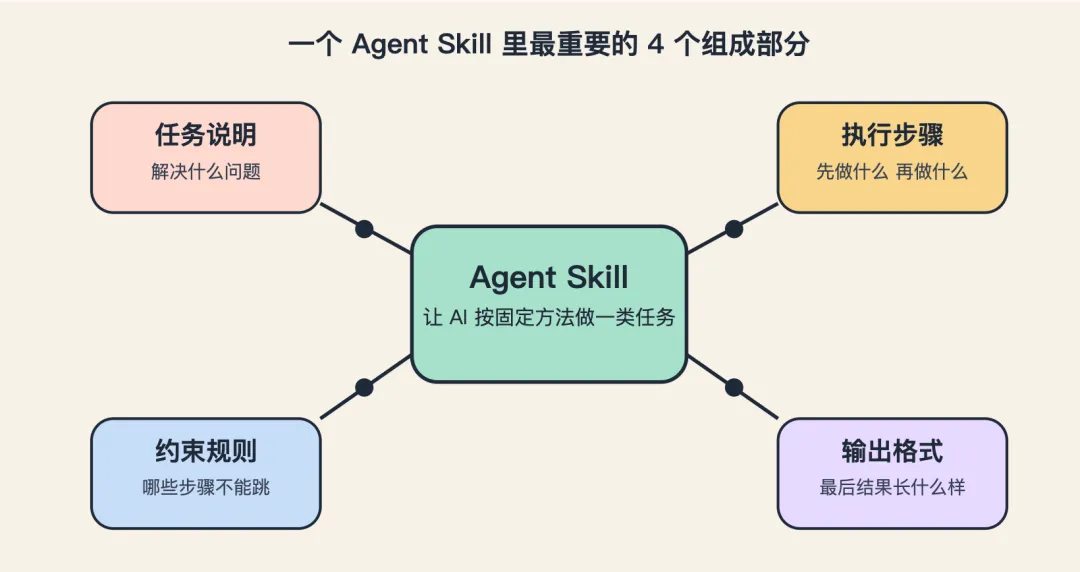
skill = 任务定义 + 触发条件 + 执行步骤 + 可复用资源。
如果再讲直白一点。
提示词,解决的是“你这次怎么说”。
skill,解决的是“这类事以后怎么做”。
所以真正值得做成 skill 的,往往有三个特点:
• 会重复出现
• 步骤相对稳定
• 做错成本比较高
比如抓网页、整理知识库、标准化改稿、固定格式发布。
这些都很适合做成 skill。