 夜雨聆风
夜雨聆风





你的 Agent 还在硬编码?这家"AI 公司"已经在猎头了
AI 圈最近有个尴尬的事实:你做的 Agent 越多,系统越脆。
LangGraph 拉一个状态图、AutoGen 摆几个 role、再上 CrewAI 堆个 Manager。三个月前的 demo 跑得贼欢,三个月后改个需求,整张图就要重画。你不是不想堆功能,你是不敢堆。一个改动会牵动十几个节点的 prompt,谁也不敢拍胸脯说改完之后整张图还能收敛。
四月底,一篇刚挂上 arXiv 的论文(2604.22446)把这件事说得更狠了一句:现在所有主流多智能体框架,根上都卡在三件事上:
“fixed team structures, tightly coupled coordination logic, and session-bound learning.”
翻译成人话:团队结构是死的、协作逻辑是焊死的、学到的东西出了这个 session 就忘。
这三句话,把过去一年所有”多智能体框架”的根本病征,按在地上摩擦了一遍。
更让人绷不住的是:他们不只是写了篇论文,还做了一个像素风的”AI 公司”运行界面,CEO 是你本人,HR / EA / COO 三位 Agent 围着你转。看一眼这张图,你大概率会笑出声。
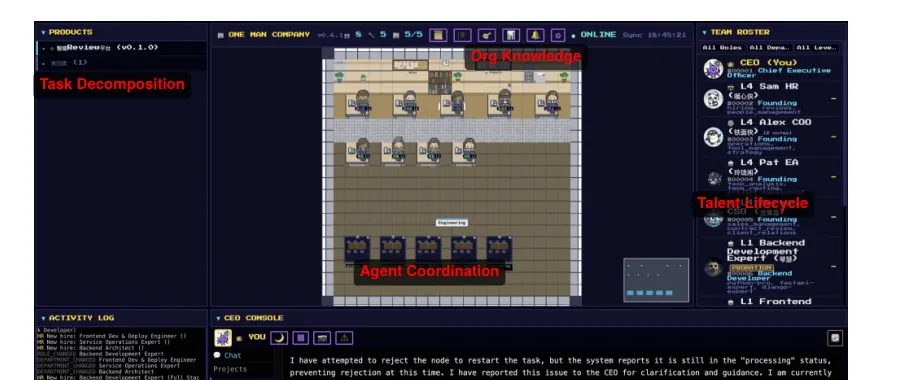
图 1:论文中的 OMC 运行界面截图。左上 Task Decomposition 任务树、中间像素风办公室里的 Agent 走来走去、右上 Team Roster 员工花名册、下方 CEO Console 是你跟系统对话的入口。 来源:arXiv:2604.22446 Figure 1。
病到什么程度?说一个我自己踩过的坑
上个月帮朋友做一个产品需求分析的 Agent 链:
-
Researcher 先去爬竞品;
-
Critic 反驳 Researcher;
-
Writer 整合写 PRD;
-
Reviewer 打分。
四个角色的 prompt 改了 11 版。最后老板说:”能不能再加一个法务 Agent?” 我盯着 graph.py 看了五分钟,默默把 PR 关了。
加一个角色,意味着重写状态机、重新调每个节点的 prompt 注入、重测所有边……这种结构焊死的痛,干过 Agent 编排的同行应该懂。每一次”加个角色”都是一次重构,每一次重构都伴随线上事故的概率。最后大家选择把功能砍掉,而不是把架构改对。
更骚的是 session-bound learning。
Researcher 这次琢磨明白了某竞品的定价策略,下次开新会话,它啥也不记得。我们不得不在外面套一层 Vector DB 当”记忆补丁”,可那是检索,不是学习。它不会从上次的失败里长经验。同一个坑,每次都得重新踩一遍。换言之,你花在”教 Agent”上的所有时间,开下一个项目的瞬间就作废。
就这两件事,卡死了今天 90% 的多智能体应用。
这篇论文换了个不像工程的思路
他们的解法叫 OneManCompany(缩写 OMC,下文简称 OMC)。
注意,名字不是噱头。论文真的在用”公司”这套抽象重新建模整个系统:
-
每个能干活的单位不再叫 Agent,而叫 Talent(人才)。一个 Talent 是 skills + tools + runtime configuration 的便携式打包。你可以理解为一份”AI 简历 + 工具箱”,可以从一个项目搬到另一个项目,不丢经验。
-
任务来了,不是按预设角色分配,而是去 Talent Market(人才市场)临时招聘。需要一个会写法务条款的?去市场拉。三天后这个能力不需要了?解约。
-
整个组织在执行过程中可以动态重组。论文原话:”close capability gaps and reconfigure itself dynamically during execution.”
我第一次读到这段,脑子里冒出来的不是 framework 的概念,是字节跳动的 OKR 复盘会。
论文给了一张架构总览图,三块拼在一起:左边是社区驱动的 Talent Market、中间是 E²R Tree Search 执行核、右边是项目复盘与组织级进化。整套机制就是一家”虚拟公司”的运行流程。
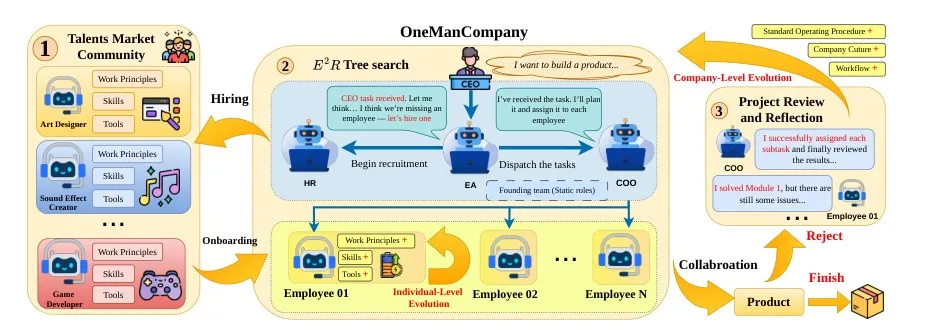
图 2:OMC 整体架构。① Talents Market Community 提供候选 Agent,HR 通过 Hiring 把人招进来;② E²R Tree Search 由 CEO / EA / COO 等核心岗位驱动任务拆解和派发;③ Project Review 决定 Reject 还是 Finish,并把经验沉淀回组织级的 SOP / Workflow。 来源:arXiv:2604.22446 Figure 2。
等等,这跟 MetaGPT / AutoGen 不一样吗?
你可能会想:MetaGPT 不也搞”软件公司”那一套?AutoGen Studio 也能动态加 Agent 啊?
差别在三个字:所有权。
MetaGPT 把”产品经理 / 架构师 / 工程师”这套角色 hard-code 进了框架,是预设的剧本;AutoGen 提供了 group chat,但每个 Agent 还是依附在某个 conversation 里活,会话一关,全部归零;CAMEL 的 role-playing 强调两两对话,更像舞台剧而非组织。
OMC 的不同在于:Talent 是独立资产。它有自己的 ID、版本号、跨任务的成长记录,可以被组织拥有、被市场流转、被审计回溯。
这听着是不是有点像 HR 系统 + 人才中介所的合体?
为什么是 2026 才有人这么干
这套范式有个隐藏的前置条件:基础模型的能力得过了某个阈值。
你想想看:把 Agent 当人来招聘,前提是 Agent 真的能”独立完成一个有边界的任务”。GPT-3 时代它不行;GPT-4 时代刚刚行,但成本不可控;到了 2026 年的这一波(Claude 3.5 / Gemini 2 / Qwen 3 全面上 reasoning),单 Agent 完成 3-5 步推理的成功率才稳稳跨过 80%。
模型够强了,组织化才有意义。 一群再聪明的”打工人”,每个人都干不利索一件事,那经理也救不了;只有当每个人能独当一面,公司这层组织才开始正向放大人力。OMC 是踩着这个时间点出来的。早一年,纸上谈兵;晚一年,红海。
E²R Tree Search:把”项目复盘”做成了算法
光招聘还不够,公司还得知道怎么干活、怎么复盘。
OMC 给出的执行核叫 E²R Tree Search,三个字母分别是:
-
Explore:把任务自顶向下拆成一棵树,每个节点是一个”可以问责”的任务单元;
-
Execute:叶子节点找 Talent 干,结果自底向上逐层汇聚;
-
Review:每一层 review 上一层的产出,发现问题就回头优化整棵树的某个分支。
听着熟不熟?这就是字面意义的项目管理 PDCA 循环,只不过执行者是 Agent。
举个具体例子。假设任务是”为某 SaaS 产品写一份 PRD”:
-
根节点 Explore → 拆成『竞品分析』『功能定义』『用户故事』『验收标准』四个子任务;
-
子任务再 Explore → 比如『竞品分析』再拆成『功能矩阵』『定价策略』『差异化机会』;
-
叶子 Execute → 从 Talent Market 里招一个『市场分析师 Talent』来干;
-
结果回收 + Review → 如果『差异化机会』产出质量低,回头重新招更专业的 Talent,或重新拆这个分支;
-
根节点合并 → 所有子产出合成最终 PRD。
整个过程像不像一家咨询公司接项目?合伙人拆活、招外包、收稿、改稿、合稿。
更关键的是论文给了形式化保证:这套循环对任何任务都能保证终止性和无死锁。这两个字,是工程上的硬刚需。今天大多数 LangGraph 跑久了卡死、AutoGen 跑久了无限互相 @ 的情况,本质都是没有人证明你的图是收敛的。
OMC 把这件事用算法证完了。这意味着你部署 OMC 系统时,可以在 SLA 里写”任务必然完成”,这在工程上是质变。
数字呢?给你一组让人闭嘴的
在 PRDBench(产品需求文档生成基准)上:
-
OMC 拿到 84.67% 成功率;
-
比上一代 SOTA 高出 15.48 个百分点。
这个量级是什么概念?做过 benchmark 的人都知道:长尾任务集上 +1 个百分点都要拼命刷。15 个点,不是调参刷出来的,是范式跳了。
更值得注意的是论文用的词:”cross-domain case studies further demonstrating its generality.”,他们在跨领域上也跑了。意味着这套”公司化”组织方式不是只对 PRD 友好,而是个通用的多智能体组织层。论文 33 页 13 张图,把这套机制的边界条件画得很细,不是 marketing 话术。
当然,OMC 没解决的事也很多
我不想把这写成软文,所以也得说几句它没解决的。
第一,成本不透明。 Talent 招聘 + E²R 树搜索意味着同一任务的 LLM 调用量可能翻 3-5 倍。论文没明确给出 cost 数据。84.67% 是用多少 token 换的?这是工程落地最关键的一个问号。
第二,Talent 信誉的”漂移”问题。 一个 Talent 在 100 个项目里建立的好评,是基于过去某些版本的 prompt + 模型。模型升级、prompt 改版之后,这份信誉还作数吗?论文里看似没深入。
第三,Talent Market 的作弊。 一旦市场化,就有 Sybil 攻击:刷”假高分 Talent”骗组织雇佣。这在去中心化 marketplace 上是老问题。
但承认这些问题不影响主线判断:OMC 是把多智能体从”工程问题”拉到”组织问题”层面的第一篇严肃工作。瑕不掩瑜。
这预示着什么?四个判断
第一,多智能体框架要分层了。 LangGraph / AutoGen / CrewAI 解决的是”多个 Agent 怎么传消息”,这是通信层。OMC 解决的是”多个 Agent 怎么组织”,这是组织层。下一年,你会在 GitHub 上看到大量 OMC-style 的中间件,叠在现有框架之上。
第二,”Agent” 这个词可能要让位了。 当一个执行单元开始有简历、有跨任务记忆、能从一个项目”跳槽”到另一个项目,它就不是 Agent 了,它更像数字员工。这套语言一旦渗透进 SaaS 产品文档,整个行业的 narrative 都会重写。
第三,AGI 之前,会先冒出来”AI 公司”这个新物种。 不是说一家公司用 AI,是一家完全由 AI 组成、靠 OMC 这类组织层运行的虚拟实体。它接客户需求、招”talent”、交付产品、按月分账。这件事在 2026 年下半年大概率不再是 PPT。
第四,Talent 本身会变成新的 marketplace。 想想看:一个被验证过的『资深 PRD Writer Talent』,它的”简历”(历史成功率、擅长领域、依赖工具链)是可以估值的。下一波 AI 创业者卖的可能不是 SaaS、不是 API,而是单个高质量 Talent 的版权和分成。HuggingFace + Upwork 的合体形态,会在 12 个月内冒出来。
给开发者的三条实操建议
读完论文我列了三条 actionable,分享给同行:
-
现在就开始把你的 Agent 加 ID + 版本号。 不管你用 LangGraph 还是 AutoGen,给每个 Agent 配置加一个
talent_id+version+success_log。等 OMC-style 中间件普及,迁移成本几乎为零。 -
把”角色”当中间件,别 hard-code。 下次设计多智能体应用,把 role 注入做成可热插拔的,不要再写
if role == "Reviewer"这种判断。Talent Market 的本质就是 role 的运行时绑定。 -
重看你的失败 log。 OMC 的 Review 阶段证明了一件事:多智能体最大的浪费,是没人复盘。从下个项目开始,给你的 Agent 流水线加一层 review hook,把每次失败的根因写进一个跨会话存储,这就是最朴素的”经验积累”。
写在最后
读这篇论文的过程,我有种”被点醒”的感觉。
我们这些天天码 Agent 的人,其实一直在用工程师的本能做 Agent:状态机、有向图、protocol。但真正能 scale 的多智能体系统,可能根本不是”工程问题”。它是组织问题。
而组织问题,人类已经研究了两百年。从泰勒制到 OKR、从科层制到 Holacracy、从合伙制到平台制,每一套人类组织进化论,都可能是下一代 Agent 框架的隐藏蓝本。
OMC 这篇论文,只是把”公司”这一块第一个搬进来。等到有人把”市场””国家””开源社区”也搬进来,那时候我们讨论的就不是”多智能体编排”,而是机器文明的制度设计。
所以下次你打开 LangGraph 准备焊死下一张状态图的时候,
不妨先问自己一句:
如果我招的不是节点、是人,我会怎么搭?
论文链接:arXiv:2604.22446(33 页,13 图,2026 年 4 月 24 日上线)
作者团队:Zhengxu Yu, Yu Fu, Zhiyuan He, Yuxuan Huang, Lee Ka Yiu, Meng Fang, Weilin Luo, Jun Wang
图 1 / 图 2 直接截取自论文 arXiv:2604.22446,Figure 1 与 Figure 2,仅作引用与解读。