 夜雨聆风
夜雨聆风





OpenAI工程师把话挑明了:一个人盯3到5个Coding Agent,基本就到顶了!反手开源了一套「少盯人、多验收」的新系统
一个残酷的数字:3到5
故事要从一条推文说起。
2026年4月27日,Alex Kotliarskyi(@alex_frantic)在X上发了一条线程,开头就是一记重锤:
“Engineers at OpenAI experience the same problem as everyone else — we can supervise about 3–5 coding agents. After that productivity drops. Codex is smart, but our attention is limited.”
「OpenAI的工程师也遇到和所有人一样的问题:我们大概只能有效盯住3到5个coding agents,再往上生产率就掉了。Codex很聪明,但我们的注意力是有限的。」
注意,这不是某个路人在吐槽。这是跟OpenAI / Codex直接相关的工程实践者,在公开线程里坦承的一线体感。
这条帖子的热度也说明它戳中了痛点:66条回复,133次转发,2623个赞,2875人收藏,近40万次浏览。
为什么这个数字会引起这么大共鸣?因为每个实际用过coding agent的人都有类似体感:
-
单个agent,很爽 -
两三个agent,开始频繁切换注意力 -
真到五六个以后,你会开始忘记哪个分支改了什么、哪个任务卡在什么点、哪个diff里可能埋了雷
3到5,像一条隐形的天花板,所有人都感觉到了,但之前没人说破。
▲ 开发者@a_protsyuk回应:”在构建我们的平台时遇到了同样的瓶颈——3-5基本上是通用的”(1.9K次查看)
真正的瓶颈,从来都不在模型那一头
有一条回复把这件事浓缩成了一句话,传播力极强:
“Generation is solved. Supervision is the new bottleneck.”
「生成问题已经解决了。监督才是新的瓶颈。」
▲ @gpt3_eth的回复,一句话总结了整个讨论的核心
想想看——2024年大家还在比谁的模型能写更长的代码、谁的上下文窗口更大。到了2026年,代码生成越来越便宜,人的验证和注意力反而成了最贵的资源。
模型可以一秒写完一个函数,但人要花五分钟看懂它改了什么、会不会出问题。你同时开了五个agent,每个都在不同分支上噼里啪啦地改代码,你的大脑根本处理不过来。
AI编程真正的天花板,已经悄悄从”模型能力”转移到了”人脑带宽”。
OpenAI的解法:别再同步盯了
面对这个瓶颈,OpenAI给出的答案出乎很多人意料。
他们没有做一个更大的dashboard让你同时看20个窗口,也没有说”等下一代模型就好了”。他们做了一件更根本的事:重写了人和agent之间的协作流程。
这个方案叫Symphony,已经开源。
“So we built (and open sourced!) Symphony to remove that ceiling. Here’s how it works:”
Alex在线程里把Symphony的运作逻辑讲得非常清楚,核心就四步:
第一步:挂在任务系统上自动跑。
“Symphony uses a project management software to track work. For every open issue it guarantees that there’s a non-interactive Codex agent running in its own isolated workspace. If it crashes or gets stuck — Symphony restarts it.”
每个issue对应一个独立工作区,agent卡住了系统自动重启,不需要人肉盯着救火。
第二步:逼agent先交”工作证明”。
“We taught Codex to produce ‘proof of work’: green CI, deep reviews from specialist agents (security, safety, reliability, etc.), and—if the change touches user-facing surfaces—a recorded video.”
CI得绿、安全审查得过、改了界面的还得录个视频——agent必须先自证清白,才有资格来烦人类。
第三步:人只在最后环节介入。
“Codex moves the ticket to a special ‘Human Review’ status only if it has a convincing packet. Our job is now to go over and review the artifacts.”
人类的工作从”盯agent的每一步操作”变成了”看agent交上来的证据包”。CI状态、安全审查报告、diff、walkthrough视频——异步验收,按需审批。
第四步:不满意别去微操agent,回头改规则。
“If we are not happy, we don’t steer Codex. Instead we go back to our repository and provide more docs, rules, guardrails, and skills.”
这个思路很像什么?从”手把手带实习生”升级成”写制度、建SOP、定验收标准”。
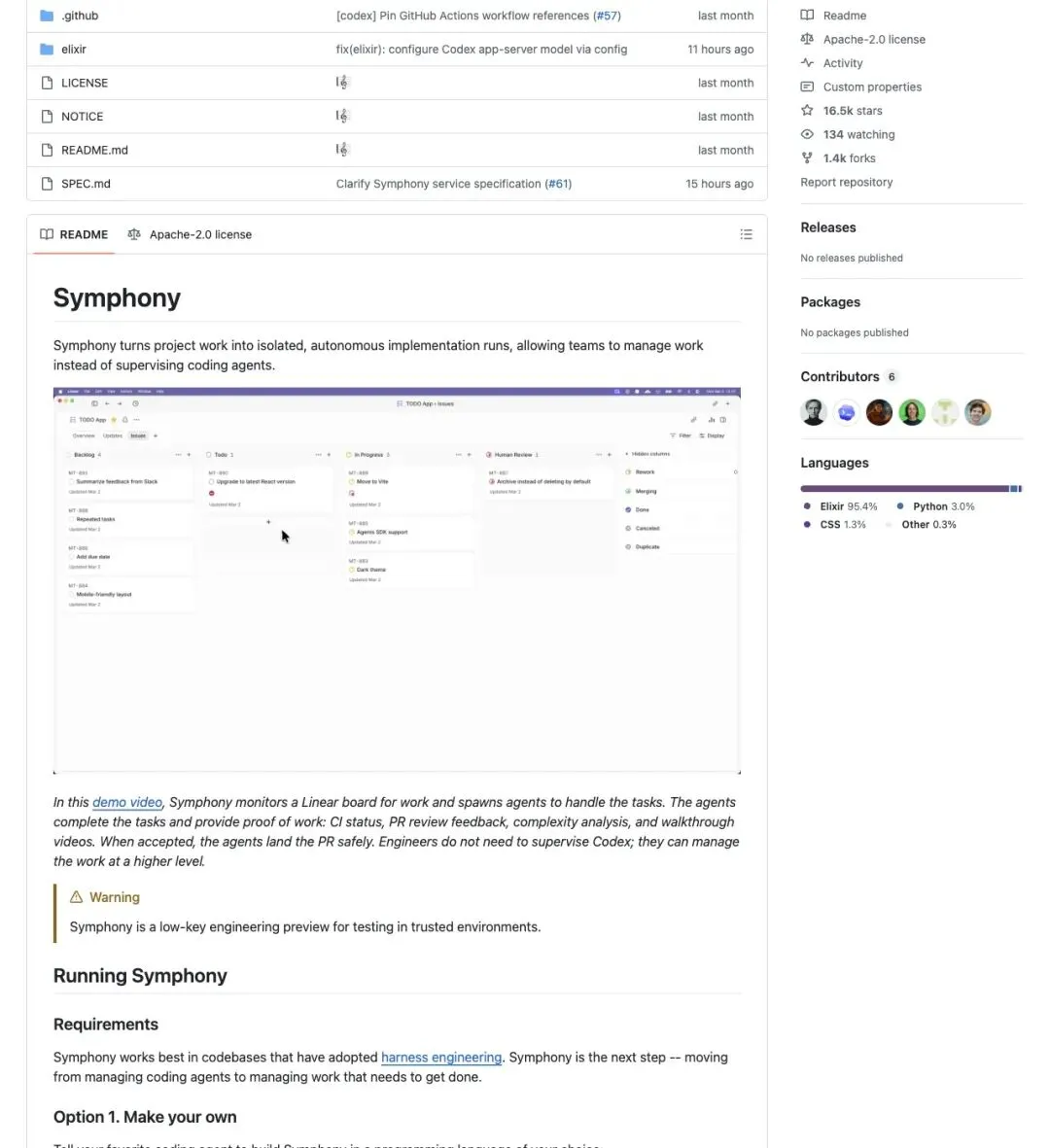
▲ OpenAI Symphony的GitHub仓库页面,16.5K star,README开头就写明:”让团队管理工作,取代监督coding agents”
一句话看懂Symphony的野心
GitHub仓库README的第一句话已经把野心写得明明白白:
“Symphony turns project work into isolated, autonomous implementation runs, allowing teams to manage work instead of supervising coding agents.”
「Symphony把项目工作拆成隔离的自治实现运行,让团队管理的是工作本身,取代一直监督coding agents。」
关键词:manage work,取代supervising agents。
但OpenAI也很诚实。README底部有一行warning:
“Symphony is a low-key engineering preview for testing in trusted environments.”
翻译成大白话:这套东西目前还是高信任环境下的工程预览版,并不是扔给任何野生代码库都能飞的通用神药。
而且它有一个前提条件:你的仓库得先做好”harness engineering”——文档得机器可读,测试得足够自洽,架构得够模块化。你得先把仓库改造成agent-friendly的,这套工作流才有意义。
社区买账吗?三派人吵起来了
Symphony发出来之后,社区反应并不是一边倒的叫好。大致分成了三派:
赞同派:”3到5确实是通用上限”
前面提到的@a_protsyuk就是代表:”在构建我们的平台时遇到了同样的瓶颈——3-5基本上是通用的。”这说明这个数字并不是OpenAI一家的特例,更像行业共同体感。
质疑派:”你只是换了个瓶颈的位置”
@PrudhviDpp的批评很尖锐:
“Good ideas but does not solve the real problem — not orchestration of github/stuck jobs. The constraint is human limitation on the amount of context our brain can take with so many worktrees running.”
「想法不错,但没解决真正的问题。瓶颈在于人脑能处理的上下文量是有限的,再多worktree一起跑,人脑还是会卡。」
换句话说:你可以把stuck jobs、GitHub调度、agent重启做得再好,但只要最后人还是得理解一堆diff和上下文,人脑带宽还是会卡住。Symphony解决的是”看不完”的问题,但未必解决”看不准”的问题。
反例派:”我同时跑25个conversation”
@_sahilahuja直接亮出了自己的数据:
“I have been running > 25 conversations.”
▲ @_sahilahuja称自己已经在用另一个orchestration工具同时跑超过25个conversation
但这里有一个微妙的区别:conversation数量≠可有效验收的agent数量。你能同时开25个对话窗口,并不等于你能高质量review 25个工程改动。就像你能同时开30个浏览器tab,但你真正在看的永远只有两三个。
Hacker News的冷水:spec像”agent slop”?
在Hacker News上,开发者的评价更加直接。
有人说这份spec”像agent slop”——只是在罗列数据库字段,提到了状态机但根本没把状态机讲清楚。
“The specs are inscrutable agent slop. I want it to tell me what it does and instead it just lists database fields.”
还有人指出,Symphony本质上只是一个scheduler / runner / tracker reader,它解决了调度问题,但真正让软件可靠落地的harness,还得靠仓库本身的工程质量。

▲ Hacker News上的讨论,25 points,有人直接批评spec质量不够好
方向可以先讲对,但开源spec本身未必已经成熟到让所有开发者信服。
更深一层:AI编程的下一场竞赛
把这件事放到更大的图景里看,一个趋势已经非常清楚了:
2024年的AI编程竞赛,比的是谁的模型能写代码。2026年的AI编程竞赛,开始比谁能让人类更省力地验收代码。
Symphony讨论的关键词已经变了。不再是更大context、更强reasoning、更多token,取而代之的是:
-
issue tracker -
isolated workspace -
proof of work -
Human Review -
WORKFLOW.md -
harness engineering
这些词放在一起,说明竞争重心已经从”模型会不会写”迁移到了”组织怎么让agent持续、可靠地写”。
正如SPEC.md里写的那样:
“A successful run can end at a workflow-defined handoff state (for example Human Review), not necessarily Done.”
「一次成功运行的终点可以只是某个工作流定义的交接状态,比如Human Review,不一定直接等于Done。」
连”成功”的定义都变了——agent跑完交上来让人审,这就算成功。
最后一个问题
这条讨论最让人细思极恐的一点在于:
如果OpenAI自己的工程师,用着全世界最好的coding model,都只能有效盯住3到5个agent——那些宣称”一个人带100个agent改造整个公司”的故事,到底有多少水分?
也许AI编程下一阶段真正稀缺的资源,从来就不是更强的模型。
而是人类愿意分出多少注意力,以及我们能不能设计出让这份注意力花得更值的流程。
— END —