 夜雨聆风
夜雨聆风





智算中心规划:等效AI算力及Token承载用户量折算
1. 算力的单位:
通常采用FLOPS(Floating PointOperations Per Second)表示每秒钟能够完成的浮点运算或指令数,例如一台计算机每秒钟可以完成10亿次浮点运算,那么它的 FLOPS 值就是1G FLOPS(1 Giga FLOPS)。

|
序号 |
算力精度 |
衡量的算力类型 |
适用范围 |
|
1 |
FP16 |
AI服务器 |
衡量智算中心的智能算力性能,用于AI训练等 |
|
2 |
FP32 |
通用服务器 |
衡量数据中心的基础算力性能,适用通用计算 |
|
3 |
FP64 |
超级计算服务器 |
衡量超算中心的超算算力性能,适用于科学计算、工程计算等高精度计算 |
1GW 的电不能全部变成算力,需要经过三道“关卡”的扣除:
第一关:PUE(能源使用效率)
-
1GW 是数据中心的总输入功率。
-
其中约 25%~30% 的电力会被散热系统(空调/液冷)、照明和网络设备消耗掉。
-
目前先进数据中心的 PUE 约为 1.25。
-
剩余 IT 设备可用功率 ≈ 800 MW。
第二关:非计算硬件损耗
-
在 IT 设备内部,电力并非全给 GPU。CPU、内存、硬盘、主板以及电源转换损耗会占用一部分。
-
通常 GPU 占总 IT 负载的 60%~70%。
-
GPU 实际可用功率 ≈ 800 MW × 70% = 560 MW。
第三关:GPU 能效比
-
以当前主力芯片 NVIDIA H100 为例,其 AI 算力(FP16精度)约为 120 TFLOPS,功耗约为 700W。
-
单瓦算力 ≈ 0.12 PFLOPS / 700W ≈ 0.00017 PFLOPS/W。
-
1GW总算力 = 560,000,000 W × 0.00017 PFLOPS/W ≈ 100,000 PFLOPS。
数据中心算力是数据中心内所有服务器算力的加和。那我们如何根据一个数据中心IT电力容量来估算数据中心的算力呢?
1、选定服务器类型,计算服务器数量。
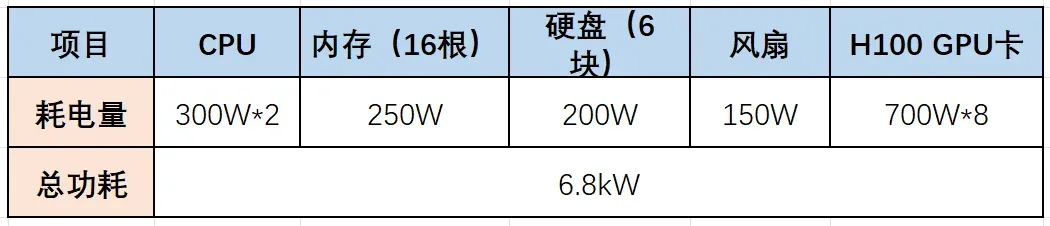
假定某数据中心规划1GW电力,其中IT总容量为800MW,采用H100 GPU模组整机服务器满配,单个H100 GPU模组功率约8kW。【一个H100 GPU模组,包含8张GPU卡,理论计算最大的功耗为6.8kW,分别由以下几项组成】:
2、获取服务器GPU算力参数
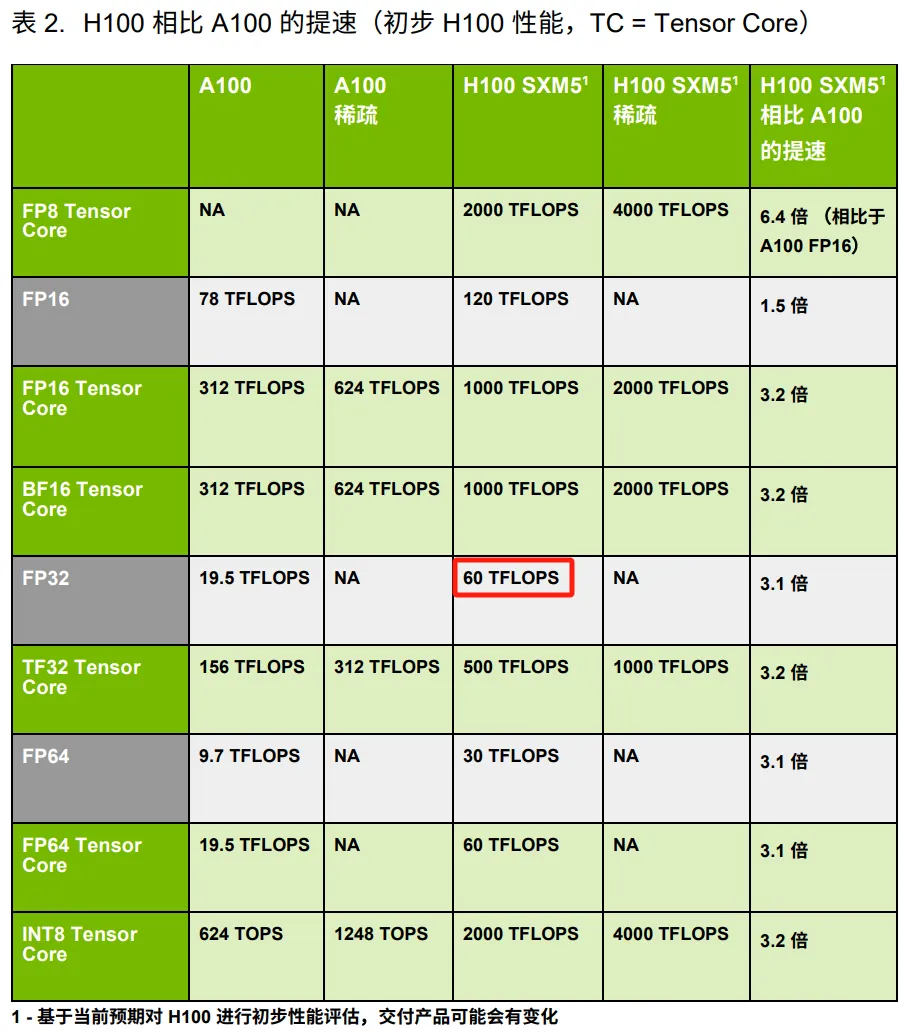
根据《NVIDIA H100 Tensor Core GPU 架构白皮书》,查询H100 GPU单卡算力为120TFLOPS(半浮点精度FP16)。
2、计算数据中心算力
单台服务器共有8张GPU卡,在忽略CPU算力的情况下,可计算出智算中心算力理论峰值为:
数据中心算力(CP)=单台服务器算力 * 服务器数量
=120TFLOPS *8 * 100,000
≈1000 TFLOPS *100,000
=100,000 PFLOPS
3、总结:
1GW电力 ≈ 10万台 H100满配服务器 ≈ 10万P FLOPS
即:1GW电力可规划的算力在2万至15万PFLOPS之间。这里有两条典型路径:
1)采用英伟达H100等高性能GPU集群:1GW(即1000MW)电力可支撑约 10万PFLOPS 的AI算力 。
2)采用国产高能效芯片(如燧原i20/S60)集群:按N卡性能50%预估,1GW电力可支撑 5万PFLOPS 算力 。
3)考虑到未来芯片(如 Blackwell 系列)能效比的提升,以及集群优化的进步,行业通常会将规划值上浮30%,即峰值规划至 20万 PFLOPS。
注:若采用混合异构架构(如H100与国产芯片并用),实际算力将介于上述区间,具体取决于部署比例和调度效率。此外,电力使用效率(PUE)、散热能力、网络延迟、软件栈开销等因素也会影响最终可用算力(大规模集群的实际算力远低于芯片理论峰值之和),通常实际运行中需预留10%-30%的冗余空间 。
从生活场景可直观感受算力需求的量级差异:
-
场景一:智能客服、语音助手。算力需求约几十至数百GFlops,单次消耗小,但需支撑海量用户并发。
-
场景二:AI绘图、短视频生成。生成一张高清图需数百TFlops;生成1分钟Sora级视频,算力消耗堪比一个中小数据中心全天负荷。
-
场景三:千亿参数大模型训练、L4级自动驾驶。需持续调用数千PFlops乃至EFlops级算力,运算数月,完全依赖智算中心这类国家级基础设施。
在1GW(吉瓦)这一量级的电力供给下,数据中心可部署约10万PFLOPS级别的高性能算力集群,单日可处理约2000万亿Token,主要应用于:大模型训练与推理、自动驾驶研发、生物医药模拟及国家级算力枢纽建设,支撑AI产业核心场景。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
1、算力每日Token产出量
每秒Token生成数 (TPS) = (总算力(FLOPS) × 系统利用率(U)) / (每Token 计算量)
1)1P总算力供给(每日)
= 10^15 FLOPS(每秒浮点运算次数)*86,400 秒/天
= 8.64*10^19 FLOPS
受限于内存带宽(Memory Bound)、通信延迟和调度损耗。实际有效算力利用率通常较低,按 50% 估算。
2)每Token算力成本(生成单个Token所需的浮点运算次数。这个值基本由模型大小决定,可以用公式 每Token计算量 = 2 × 模型参数量 进行估算。实际生产中,为考虑冗余和稳定性,常取
3)不同模型规模下的每日Token产出估算
|
|
|
|
|---|---|---|
|
|
|
8.64*10^19 *50% / 200*10^9 = 864*10^8 *50% / 200 = 2.16 *10^8 = 2.16 亿 |
| 70B (700亿) |
|
3.09亿 |
| 13B (130亿) |
|
16.61亿 |
| 7B (70亿) |
|
30.86亿 |
注:以上为理论推算值,并未考虑内存和带宽的瓶颈。
基于当前(2025-2026年)的行业技术水平和实际工程经验,1 PFLOPS 的算力在一天内大约平均可产出 10万亿 Token。
备注:
1)模型越小(如 7B),1 PFLOPS 能跑出的 Token 数量越多(可能达到数千亿/天);模型越大(如 400B+),数量越少。
2)“1 FLOPS ≈ 0.01 Token”,意味着生成一个词需要按100次计算器,是基于 Transformer 架构在 FP16/BF16 精度下 的典型推理效率,已被 NVIDIA、Meta、阿里通义、华为昇腾等广泛采用作为估算标准。即:1PFLOPS ≈ 10^13 Token = 10万亿 Token。
2、大模型训练业务(??)
1GW电力可支持千亿参数大模型(如GPT-4级别)进行上万次完整训练迭代。例如,GPT-4大模型单次训练消耗4000亿token(??),则1MW(100P)数据中心可支撑约2500个GPT-4大模型训练任务:
100P * 10万亿Tokens/P ➗ 4000亿Token = 2500个 GPT-4大模型训练
3、推理服务
推理服务:日均可处理超百亿token请求,满足千万级用户日常交互需求。若单用户(中等强度)日均算力需求20万 token(??,突发?),理论上1MW(100P)算力集群可稳定支撑超1000万的中等强度使用。
100P * 100万亿Token/P ➗ 20万 * 1/10000突发 = 1000万用户
推理场景下部分实际应用Token对照表:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
文本属于一维数据,生成每个Token仅需1轮迭代,可以用KV Cache缓存来“以存代算”,即生成第2个Token的时候,可以从缓存中调用第1个Token,不用从头再算一次。通常,普通文本问答任务,单次消耗Token仅千级。
4、视频生成
视频生成是一种从噪声中恢复图像的技术,主要用到扩散模型,要逐帧去噪,每一步都是海量矩阵运算。
视频是四维数据(宽x高x时间xRGB), 每一帧图像去噪过程中无法“以存代算”,因此,生成每个帧需20-30轮迭代。
举个例子,用户生成一段时长5秒、帧率24帧/秒、分辨率720p的视频,需要消耗的Token数为:
视频Token用量≈(宽×高×帧率×生成视频时长)/256
≈ 1280*720*24*5/256 = 43.2万个Token
从以上Token消耗量对比可以看出,视频生成模型的计算复杂度远超文本模型,单次视频生成任务消耗Token数通常为一般文本问答的百倍以上。
🌍 对比现实世界规模:
-
微信:2023年日均消息量约 2.1 万亿 Token(含文本、语音、图片描述)→ 相当于 24 PFLOPS 的算力支撑 -
OpenAI GPT-4:日均处理约 10 万亿 Token→ 相当于 115 PFLOPS 的持续推理算力
1 PFLOPS = 每天产出 86.4 万亿 Token,是支撑“全民AI化”服务的最小算力单位。
1 PFLOPS 的算力,单日即可完成超过860亿次AI对话,相当于全球每天有 超过10亿人 各自与AI聊上8次以上。
一个中型城市级AI平台,通常需要 100–500 PFLOPS 才能实现“人人可用、秒级响应”。