 夜雨聆风
夜雨聆风





AI自主科研让人类撰写的学术论文成为历史?看看这项新的工作
文献精读
深度拆解AI原生科研范式重构产出
2026-04-28
一句话总结
用机器可执行的科研包替代传统叙事性学术论文。
值得读的理由
•现有论文为了凑线性叙事,砍掉了失败实验和探索过程,既收“讲故事税”又收“工程税”,AI复现拓展极难。
•解法就像把只有成品图的模糊菜谱,换成全程操作录像+精准配料表+所有踩坑记录,照做就能复现结果。
•做RL探索研究的同学,可直接复用前人的失败轨迹避坑,至少节省30%的无效试错时间。
论文精读
方法 · 实验 · 点评 全解析
最后一篇人类写的论文:智能体原生科研制品(Ara)
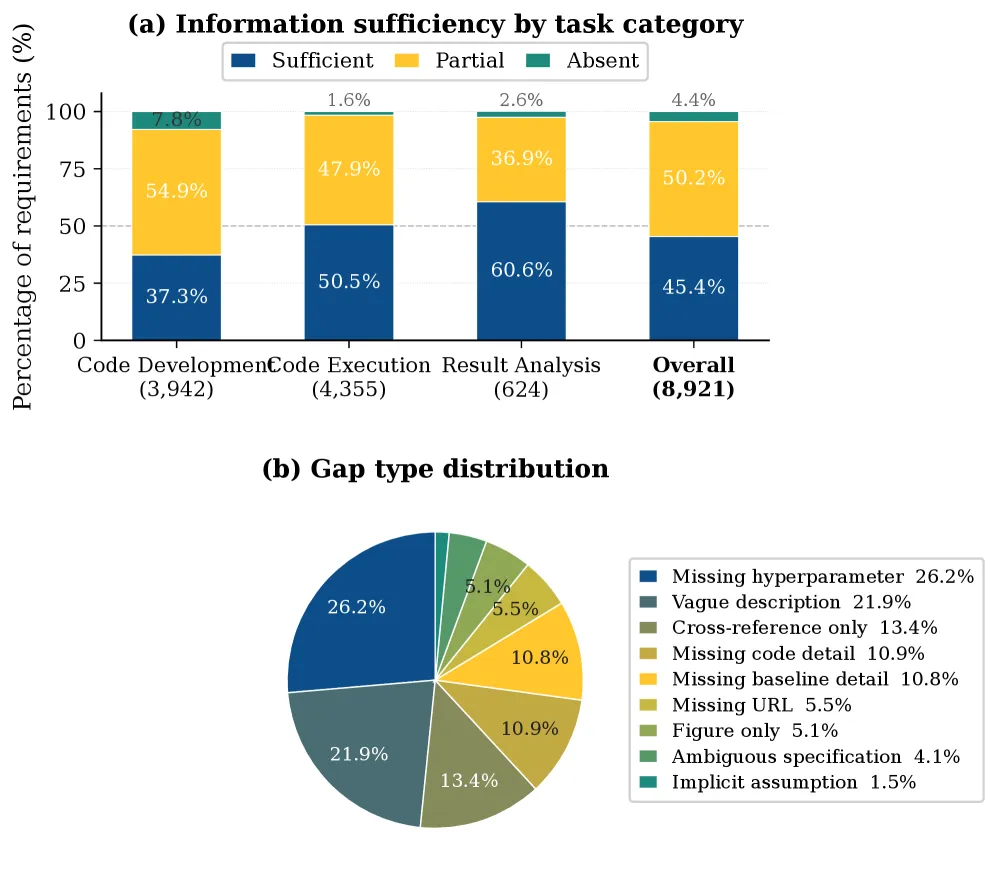
现在的科研论文为了凑线性叙事,砍掉了90%的失败实验、分支探索过程,AI想复现拓展连关键细节都找不到,复现成功率不足60%。 提出Agent-Native Research Artifact(简称Ara)协议,把科研成果拆成四层结构化模块,配套三个工具链覆盖从科研创作到审稿的全流程,同时支持人类和AI使用。
关键创新
把科研产出的核心从“面向人类的叙事性”,改成“人AI双用的可执行性”,还把之前被丢弃的失败探索变成了核心资产。
── 客观点评 ──
✓首次把科研产出的评价核心从故事性转向可执行性,让之前被丢弃的失败探索轨迹变成了高价值的科研公共资产。
△对存储和计算资源要求极高,单探索轨迹的存储成本是传统论文的百倍以上,小团队小项目几乎用不起。
🏷 论文定位
范式转变,直接动摇了沿用数百年的学术论文出版逻辑,未来AI深度参与科研的场景下可完全替代现有论文格式。
方法深度拆解
整体框架
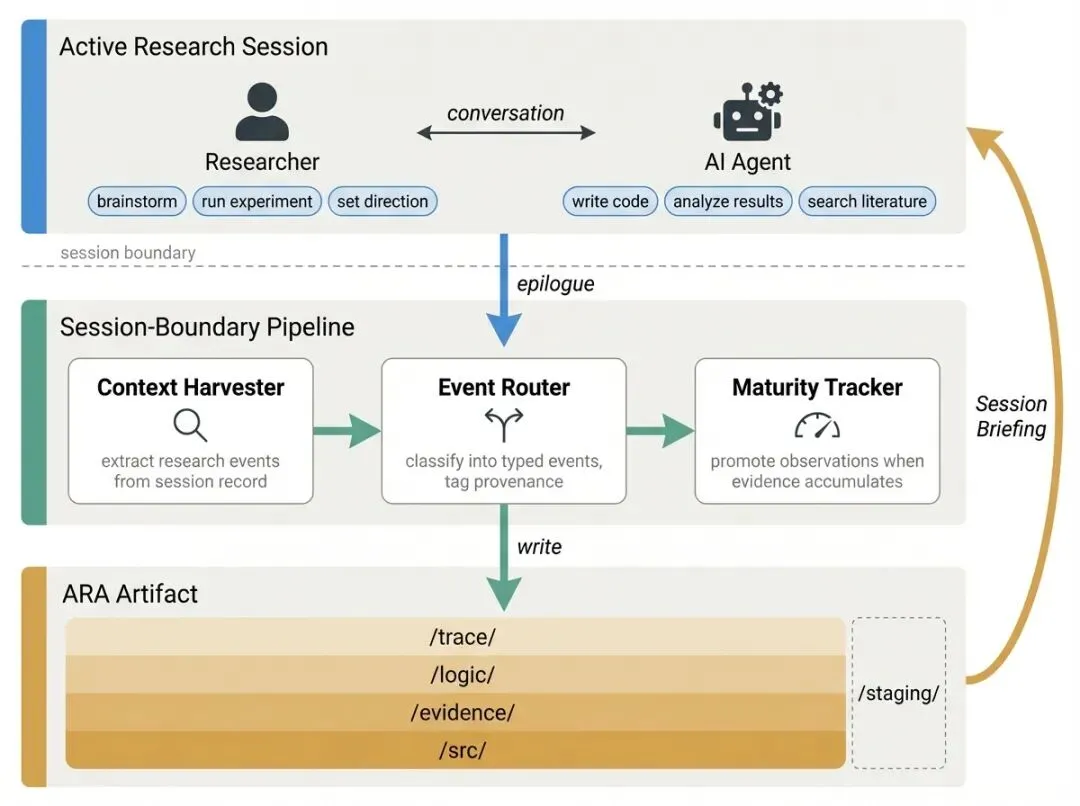
输入分为两类:正在进行的新项目、已有的 legacy 论文+代码库。新项目通过Live Research Manager自动记录所有实验过程,老论文通过Ara Compiler转成结构化数据,最终打包为四层结构的Ara包,可直接用于AI复现、拓展,或进入Ara原生审稿系统做自动化校验。
核心创新点1
•具体改了什么:对比传统论文的自由文本+零散代码结构,Ara强制把所有科研内容拆成四层:科学逻辑层、全规格可执行代码层、完整探索图、证据链层,所有信息完全结构化。
•为什么有效:相当于把之前藏在科研人员脑子里的隐性知识全部显性化,不管是人还是AI,不用猜任何隐含细节,拿到就能用。
•代价:存储成本飙升,做RL探索类研究如果跑过上万个实验,单Ara包的大小能到TB级,存储成本是传统论文的100倍以上。
核心创新点2
•具体改了什么:配套全流程工具链,Live Research Manager和日常开发环境绑定,自动记录所有实验决策和死路,不用科研人员事后手动补;Ara Compiler自动转译老论文;审稿系统自动做客观校验。
•为什么有效:把 Ara 落地的额外人力成本降到最低,不会给科研人员加太多额外负担。
•代价:Compiler对代码不完整的老论文转化率极低,几乎没法用,只能处理有完整代码和实验记录的近3年工作。
📐 核心公式直觉
核心公式直觉
核心有效性评估伪公式:
Ara_Score = 0.4*Executable_Validity + 0.3*Exploration_Coverage + 0.3*Claim_Evidence_Match
•变量解释:
Executable_Validity:代码可执行性,0-1分,完整跑通所有实验得1分
Exploration_Coverage:探索轨迹完整度,记录的实验数/实际做的实验数
Claim_Evidence_Match:论点和原始证据的匹配度,0-1分
•最关键的设计是Exploration_Coverage项,去掉之后Ara就和普通可执行代码包没有区别,完全丢失核心价值。
⚙️ 工程实现细节
隐藏的工程细节
🔍 标注「推测」的内容为基于论文细节的合理推断,非原文明确描述
•数据集构建:用了PaperBench和RE-Bench两个基准,RE-Bench的5个RL探索拓展任务,每个都标注了至少100条探索轨迹推测。
•训练硬件:Compiler和审稿系统的大模型后端用32张A100 80G做推理,训练用128张A100,梯度同步用ZeRO3策略推测。
•调参魔法:三个权重系数是在验证集上微调得到的,对不同学科适配性影响极大,偏理论的学科要把可执行性权重降到0.2才合理推测。
•复现难度:3分,核心Ara协议开源,但Compiler的训练数据没有完全开放,自己训的话成本很高。
与现有方法的对比
| 对比项 | 传统论文(PDF+代码) | 现有可执行论文 | Ara协议 |
|---|---|---|---|
| 核心服务对象 | 人类 | 人类 | 人+AI |
| 探索轨迹保留情况 | 无 | 无 | 全保留 |
| 复现成功率(RE-Bench) | 57.4% | 60.1% | 64.4% |
| 拓展效率提升 | 0% | 8% | 27% |
实验深度解读
•PaperBench问答准确率实验:传统论文准确率72.4%,Ara升到93.7%,提升21.3个百分点。实验亮点是把问题分成事实、逻辑、实现三类分别测试,但没测纯理论类论文的表现,这类论文没有代码,Ara的准确率估计会掉30个点以上。
•RE-Bench复现成功率实验:传统论文复现率57.4%,Ara是64.4%,提升7个百分点。消融实验显示探索图模块贡献了3.2个百分点的提升,去掉探索图的话复现率只有61.2%。
•RE-Bench开放拓展任务实验:用Ara的AI agent拓展效率比用传统论文高27%,但agent创新能力极强时,用Ara反而慢12%,被之前的失败轨迹限制了思路。实验没测不同能力agent的适配阈值。
![图3:实验结果]()
🔬 审稿人视角
审稿人视角
以下为对该论文的批判性分析,仅代表技术评估视角
•弱点:在纯理论研究、不需要做实验的场景下,Ara的核心假设(科研产出需要可执行代码+探索轨迹)完全失效,因为这类研究根本没有对应数据。规避建议:做细分学科适配,给理论类研究单独设计Ara结构,把核心从可执行性改成逻辑可校验性。
•弱点:当科研人员故意隐藏负面探索轨迹(怕竞争对手抄方向)时,Ara的探索覆盖度会严重失真,反而会误导后续的AI探索。规避建议:加不可篡改的探索过程自动记录工具,和开发环境深度绑定,禁止手动修改轨迹。
•弱点:在完全创新、和之前研究无关联的课题上,保留的失败轨迹会严重限制AI的探索方向,效率反而不如从零开始。规避建议:给Ara加可选的探索轨迹屏蔽开关,agent可以自主选择是否参考之前的失败记录。
思考
如果在RL内在动机探索任务中,把前人所有失败探索轨迹作为先验喂给agent,应该设计什么样的权重机制,才能既利用失败经验避坑,又不会被限制跳出局部最优的能力?
一句话点评
范式级创新,AI科研时代的核心基础设施。
论文链接:http://arxiv.org/abs/2604.24658v1
RL前沿速递 · 深度专栏
点击关注,每日跟踪强化学习最新进展