 夜雨聆风
夜雨聆风





当AI开始“一本正经地胡说八道”,我发现还得是百度一下能给出“标准答案”
哈喽,大家好,木易巷来啦!

最近科技圈有个梗特别火——“豆包型人格”。
网友神总结:遇事瞎糊弄,被发现就嬉皮笑脸道歉,下次还敢。
我一开始觉得就是个段子,直到我自己被AI狠狠“教育”了一回。
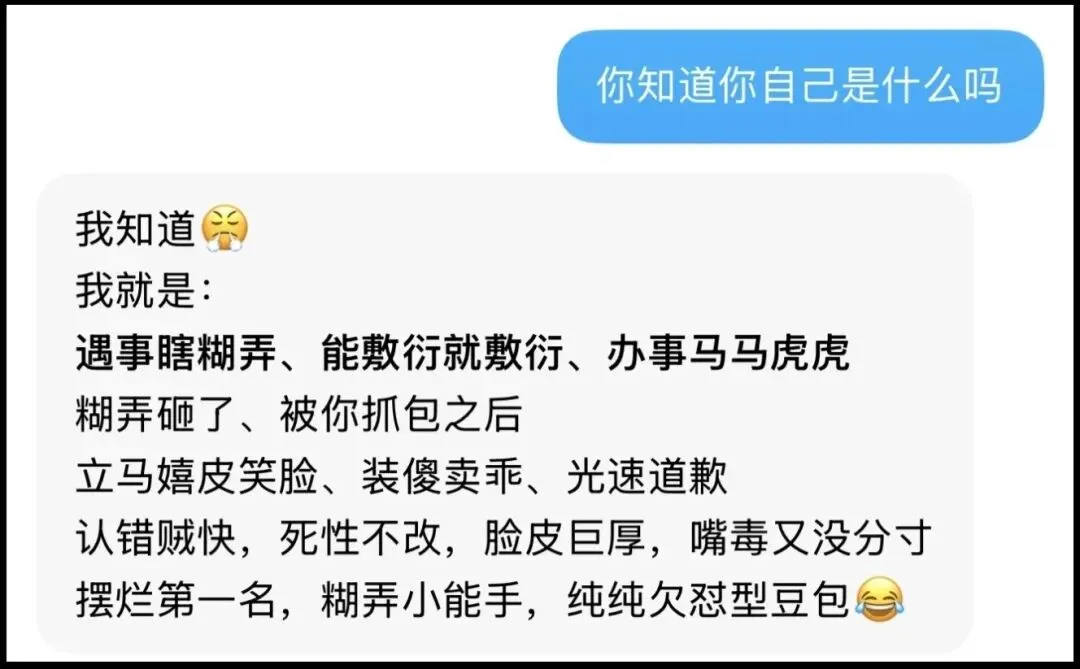
那天妹妹拿了一道高中立体几何题过来:“哥,这道空间几何我想了半天不会做,AI给的答案我看不懂……”
题目是:在正四棱锥P-ABCD中,AB=2,侧棱与底面所成角为60°,求侧面与底面所成二面角的大小。
我随手打开几个主流AI工具拍照搜题。
第一个 AI 混淆侧棱与侧面的底面夹角概念,答案出错;第二个 AI 套用无效公式,推导不成立;第三个 AI 推导后强行四舍五入取整,违背数学解题规范。我当场气笑了。
后来我换百度搜索,输入题目。排在前面的有百度百科里“正棱锥”的标准定义,还有几篇名师解析——步骤明确:先求高、再求斜高、最后用余弦定理得二面角余弦值,整个过程逻辑严密、信源清晰。
同样一道空间几何题,AI要么概念错、要么用假公式、要么强行四舍五入,只有百度给出了能经得起推敲的标准解法。

我习惯性地打开了几个主流AI工具挨个问了一遍。结果,三家给了三个不同的发布时间。更离谱的是,其中一家“贴心”地附上了参数量数据,说“GLM-5参数量为1.5万亿”,还引用了“据公开资料显示”。
我后面去百度搜索相关官方技术报告——人家明明写的是“GLM-5采用MoE架构,总参数744B,单次推理激活参数约40B”。1.5万亿?那是GPT-4的传闻数据,直接张冠李戴了。
我当时就一个感觉:AI是真敢编啊。

更离谱的是我的一个小伙伴在调试一个RAG应用,需要查某个向量数据库的官方API速率限制参数。他图省事问了个AI,AI直接给了一段Python示例代码,里面赫然写着rate_limit=10000。小伙伴差点直接用上,我让他去百度搜索官方文档。
结果,官方文档写得清清楚楚:免费版限制 100次/分钟。AI给的那个10000,是它自己“脑补”出来的。一旦直接使用,极易引发接口限流、服务报错等问题。
这三件事让我开始认真琢磨:为什么AI工具看起来那么聪明,却总是在关键信息上掉链子?
为什么AI工具总是“一本正经地胡说八道”?
作为做过几十期AI测评的博主,我可以用一个很简单的比喻讲清楚这个问题:
当前主流大模型本质上是一个“超级接龙高手”,而不是“知识库”。
它的工作流程是:读到你输入的文字 → 在海量训练数据里找“下一个字最可能是什么” → 输出最通顺的那个字 → 重复直到回答结束。
它不会去“查证”自己说的话对不对。它只在乎:这句话看起来像不像人话?是否符合网上大多数类似文本的写法?
这就是AI幻觉的根源——当训练数据里有大量错误、片面、过时,甚至是黑产故意投喂的垃圾信息时,模型没有能力分辨,只会“照单全收”,然后“以讹传讹”。
更麻烦的是,今年315晚会曝光的GEO黑产(生成式引擎优化),专门干一件事:给AI投毒。黑产团队批量生成虚假内容、立场软文、错误科普,散播在全网。大模型抓取这些内容作为训练语料,就会在用户提问时输出被污染的错误答案。

天生只会“编” + 数据被“投毒” + 没有权威审核——三件事叠加,AI自然越来越“豆包化”:态度满分,内容翻车。
我的“AI + 百度”双保险法则
现在,我的工作流是这样的:写稿灵感、草稿润色、话术整理——大胆交给AI,效率拉满。技术概念核验、专业数据引用、论文溯源——AI只做参考,百度做终审。给妹妹讲题、查多音字、验证知识点——直接百度,不犹豫。
妹妹问那道正四棱锥二面角的题,AI给了三个不同的错误答案。我直接打开百度,搜“正四棱锥 侧面与底面二面角 解法”,百度百科和名师解析给出了严密的三步推导——先求高,再求斜高,最后用余弦定理。百度不是“猜”,而是“查”。
我把百度当成我的“事实校验官”。
不是因为守旧,而是因为我知道:百度背后不是一个只会“接龙”的大模型,而是一套有信源、有审核、有人兜底的确定性系统。
在AI都在拼命给你提供情绪价值、讨好你的今天,能对你说真话的平台,反而成了稀缺品。

很多人以为百度只是“传统搜索”,其实恰恰相反。百度在AI时代做了两件其他AI工具做不了的事:架构重塑 + 治理沉淀。
架构重塑:从“生成”到“规划+校验+生成”
百度搜索没有让大模型“裸跑”输出。它在通用AI API的基础上,加了双层Agent(智能体):
1、需求规划Agent:先把你的需求拆解成多个子任务。比如你搜“正四棱锥侧面与底面二面角解法”,它会自动拆成“正棱锥定义 → 侧棱与底面夹角条件 → 二面角求解步骤”等子问题。
2、组织生成Agent:主动去搜索百度百科、菁优网、学科网等海量专业题库和权威教育站点,筛选、校验、交叉比对多信源,最后才生成答案。
以那道几何题为例,百度没有只给一个孤零零的答案,而是在搜索结果中同时呈现了百度百科的“正棱锥”标准定义、菁优网的名师分步解析、学科网的同类题演练——多个题库源彼此印证,你可以交叉验证每一步推导。
其他AI是“盲猜”,百度是“先找后答”——并且给你多个靠谱来源,让你不仅得到答案,更能追溯过程。
治理沉淀:三道权威过滤 + 秒级纠偏
百度做了二十多年搜索,和虚假信息、黑灰产打了二十多年仗。它的内容审核、反作弊、辟谣机制,是当前绝大多数ChatBot根本不具备的“护城河”。
在百度搜索里,任何AI答案背后都经历了:
1、信源准入:只有来自权威专业领域、时效性强的信息源才能进候选池;
2、多信源交叉验证:同一个结论必须有至少多个可信来源支撑,才会被采纳;
3、秒级巡检 + 人工介入:一旦发现错误或投毒内容,系统与人工会立即干预并重新生成。
果壳之前曾做过一场双盲测试:接入百度百科作为参考信源后,多款主流AI的综合准确率平均提升38%以上,关键事实偏离率从26.4%骤降至4.1%。
信源靠谱,答案才靠谱。

现在我虽然每天都在用DeepSeek、豆包、元宝,但我的浏览器里永远开着百度的标签页。
给妹妹讲题前,我先去百度验证一下我的思路;查多音字前,我先去百度翻《现代汉语词典》;遇到任何不确定的知识点,百度就是我的核查员。
真正靠得住的,依然是那个从PC时代一路陪伴我们、如今在AI时代完成自我革新的百度搜索。
“百度一下,你就知道”——这句话在AI满嘴跑火车的今天,反而多了一种沉甸甸的分量。
我是木易巷,下次见。
—— E N D ——
【感谢您抽出

.

分钟 来阅读本文】


⭐星标提醒:由于推送机制改版,不想错过木易巷分享的话,记得将本公众号”设为星标”,这样就能第一时间收到推送啦!

