这就需要明确你与ai的分工关系,我是想要ai帮我收集高质量信息?还是整理数据?还是生成可视化的扇形图?还是宣传视频?真人音频?甚至是blender模型?在二八定律(20% 的关键因素,决定 80% 的结果)的指引下,ai看似帮你完成了80%的工作(这很爽),其实这一切都源于你的执行力,回归到你自己的价值上来没有执行力,你连做什么内容都不知道有人会说“做自己的专业领域”这看似很有道理但是反直觉的是:越是非常专业的人士,比如科学家、工程师、会计师这些人, 其实大多数是不愿意使用AI 的。这是一个非常有意思的现象, 研发LLM(large language model)的那些科学家,可能还会比较排拆的使用他们自己开发的LLM。可能原因是:他们的专业能力很好, 完全掌握自己的技能并且高效的解决问题本身就是他们的强项, AI 并不能给他们带来更大的效率提升,相反还会影响他们的发挥。举个例子:就好比你是一名Tony,你想用ai做发型推荐。根据脸型,ai能直接照搬明星同款,而你却不一定同意因为作为顶级Tony的你会看:·气质·职业·用户维护能力·发质变化·社交场景客户说想剪明星同款,你就可能直接劝退,因为“不适合”这就能得出共性规律:AI更擅长“标准答案”老手更擅长“情境偏差”那ai还能有啥用?当前AI主要强在前两层:·规则整理·模式归纳但“例外处理”往往仍依赖你这种专家这本质不是行业差异,而是:当工作的核心价值来自“标准化执行”,AI更容易被接受而实现价值。当工作的核心价值来自“临场判断 + 人文经验”,高手的判断更谨慎更有“活人感”。从现象中总结:越靠流程吃饭的人,越容易被AI增强。越靠手感、关系、时机吃饭的专家,越倾向把AI当辅助。而你我的朋友,你是专家你要想的不是让ai做你擅长的事,而是让ai做你不擅长的事
1.2怎么把工作安心地交给ai来做?
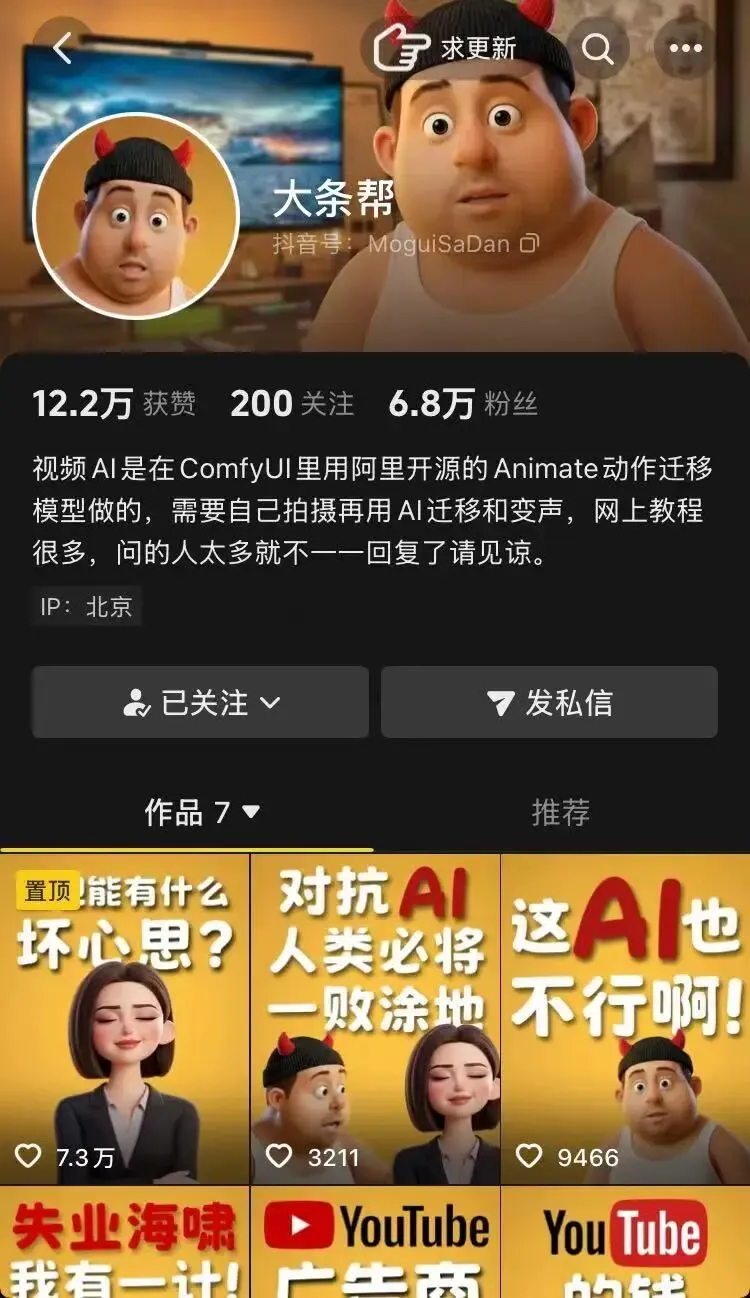
这里我想到前几个月关注的一个抖音帐号@大条帮帐号很有特色,卡通形象配上地道的首都口音,看一下很有意思,看两下还有深度(但是视频对于短视频用户有点长了)还有新颖的AI动画形式,包装精准的科技热点内容,再配上讨巧的运营细节,这个账号实现了低成本、高记忆点、高流量的冷启动如果让你去做这样式的帐号,你可能会想:1. 怎么搭建ComfyUI 环境?2.搭建完了又怎么调试?3.怎么做到真人动作自然配合?4.配音与变声又如何清晰处理?(尤其还带口音)…….那如果我告诉你:AI只是“壳”,核心还是选题和文案你又会怎么想?其实很多人做这类账号,会陷入“为了AI而AI”的误区:把大部分精力花在调模型、修穿模上,却忽略了内容本身的打磨当观众点进视频,首先被新颖的动画形式吸引,但决定他关注你的,永远是内容的价值、观点和情绪共鸣。动画形式只是加分项,内容才是根本其实这个账号背后的创作者只是一名打工人她在北京的律师事务所里上班,不是北京人,是成都人,家在城南….咳咳咳….绕远了,其实我想说的是她的执行力:·创作者的专业:解读职场焦虑、科技冲击、人性观察这些严肃话题·视频的创作视角:AI 时代的普通人·内容的叙事风格:趣味解构与吐槽(她本人确实爱吐槽生活hhh)专业解读+打工人视角+幽默风格=有价值、能共情的高质量内容同时补充上一点:她并不是计算机或者新媒体专业出身(视频里动画人物单调的动作和呆呆的表情确实看出这一点)但她的内容围绕AI 冲击下的职场焦虑、行业吐槽、职场人性观察展开,并能精准戳中当下打工人的痛点,比如 AI 替代工作、广告行业困境、职场潜规则等是ai做成账号了吗?显然不是这是专业运用+ai辅助的结果应该说是ai帮她做成了账号把不擅长的交给 AI,反而能提升你的核心能力你不用陷在琐碎弱项里,就有多余心力:·深耕自己擅长的领域·思考决策、创意、判断、看人看事·专注提升不可被 AI 替代的思维和阅历用一句话总结:你没必要什么都自己做,你只需要做好你最擅长、最有价值的部分,剩下的,全部交给ai
1.3有没有不吃操作的好选题?
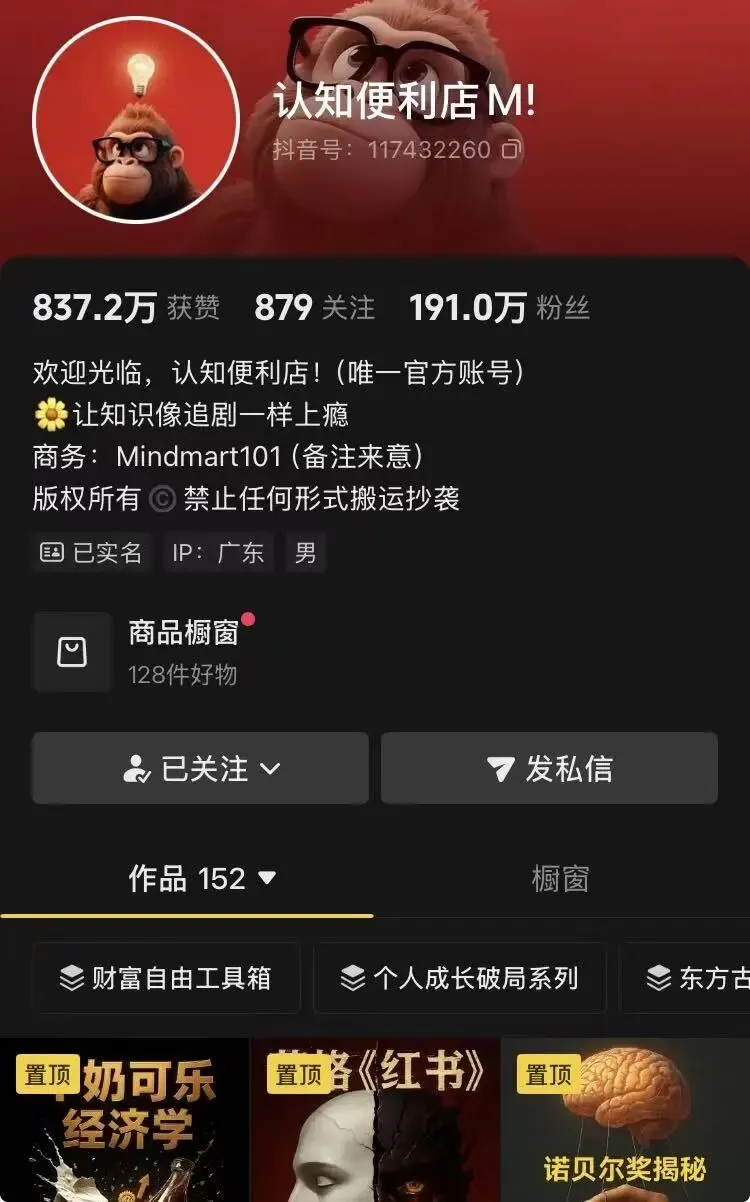
有的兄弟,有的@认知便利店一个人运营3个账号,4个月涨粉120w他有自己想过选题吗?并没有结合账号的爆款逻辑和选题策略,让我们把他的内容选题一点点拆解开来:第一,核心选题逻辑:“已验证爆款 + 二次创作”根据账号的底层逻辑,它的选题核心不是从零原创,而是 “用 AI 加工已被市场验证过的爆款内容”:·来源:知乎、天涯、人文社科类高赞问答爆文,这些内容已经经过用户的点赞、收藏、评论验证,自带流量潜力·创作:用 AI 把这些内容重新拆解、改写,用更通俗、更体系化的方式讲出来,再搭配 AI 生成的画面完成视频制作·优势:不需要自己猜用户喜欢什么,选题自带 “爆款基因”,大幅降低试错成本,支撑账号日更、多账号同时运营第二,三大爆款选题方向生活现象+底层逻辑+反直觉科普这是账号最出圈的选题类型,核心是用经济学,社会学原理解释日常现象,打破用户的固有认知典型例子:“为什么牛奶装在方盒子里,可乐却装在圆瓶子里?”“为什么景区的矿泉水比外面贵好几倍?”“为什么超市总把贵的东西放在和视线齐平的位置?”特点:用大家熟悉的场景做钩子,用颠覆常识的结论抓眼球,最后用底层逻辑升华价值这完美契合 “内容价值 =(理论深度 × 表达清晰度)/ 认知门槛” 的爆款公式第三,聚焦认知升级 + 财富思维的搞钱话题(这可以说是流量密码)普通人关心的 “搞钱、成长、破局” 话题而用系统化的思维拆解问题你就能满足用户对 “提升认知” 的需求虽然我对钱不感兴趣,但是我对搞钱的人感兴趣开个玩笑hhh但“搞钱”确实是我发现的短视频最大爽点,也是我扩展私域的核心话题所谓“搞钱”本质是与人性底层需求、时代焦虑和传播规律等大部分人固有频率的多重共振而看着爽的搞钱话题,永远都是不吃操作的好选题这里我想展开聊一下:如何利用FOMO(fear of missing out)情绪实现爆款?这不是题外话,而是我对人性的直接观察今年一月底,openclaw(原名clawbot)也就是龙虾agent横空出世(简单介绍一下:OpenClaw 是“能动手的 AI”—— 把大模型从 “聊天框” 解放出来,变成能在你电脑上24 小时自主干活、隐私可控、高度定制的数字员工,适合追求隐私、自动化与 AI 控制权的个人与团队。)两条视频就给我带来了5万多的播放…虽然流量不算多,但是同时带来了几十条私信(虽然数量上赶不上颜值内容,但是质量绝对高,而且是目前能扩展私域的重要途径)这些私信都有些什么?”能介绍一下吗?““可以加你吗?”“可以给个联系方式吗?”“想找一个项目”“想跟着你”“很迷茫”“懂得比我多”“可以交学费”等等你可能好奇,我都发了什么?就是简单的搬运,我搬运时甚至没有完全理解我在搬运什么(但这不重要,重要的是这给我账号带来的溢价是真实的,当我被私信时,其实我的能力其实被大大高估了)但是我没搬技术解读,也没搬运行原理,甚至都不是最简单的概念介绍没错,你可能已经猜到了我搬的内容就是“搞钱”我的文案只需要几个关键词“polymarket”,“一晚”,“超200%收益”,“ai助手”,“立刻变现”虽然我没有当时没有扩展私域,也没有帮人装几百一套的openclaw但是我看到了:人们从 “要不要学” 变成 “不学就要被彻底甩开” 的生存级FOMO当社交平台充斥ai成果晒单,FOMO被全方位放大,我甚至都不需要利用萨伊定律(供给会自动创造自身的需求),因为不停迭代的ai已经为我创造了现有的他人FOMO情绪。而我需要做的就是创造一个有确定价值的账号去与FOMO受众做利益交换,直接体现的就是流量与高质量私信(其实FOMO的消除才应该是终极目标,这与心理抗拒理论与禁果效应有关,但是对于抖音账号的短期运营没太大好处,原谅我不展开讲了…….其实是我懒hhh)回过头来搞钱+ai,永远都是最好的选题而你要做的就是尽可能早的抓住这些选题,让你溢价
1.4用ai做深度内容有流量吗?
老谈“搞钱”太low了,什么”提升认知“都是自我安慰罢了你想追求更前沿更专业的内容,但却又害怕观众看不懂没关系,观众不需要真的懂,他们真正需要的是:“这跟你有关、对你有用”“你懂我、我认同你”你需要接受观众心里只关心三件事:“能帮我省钱、赚钱吗?”“能帮我少踩坑、省时间吗?”“能帮我提升认知、变强、不落后吗?”兜兜转转,又回到了“搞钱”……难道抖音没法做有深度的专业内容吗?你可以这样做:1. 开篇 3 秒抓停留:不说术语,先说利益 / 痛点别上来就讲原理、讲参数。—错误:今天给大家解析 XX 技术架构、底层逻辑。—正确:为什么很多人学不会 XX 技术?核心卡在这一个点/这个技术一旦普及,会直接改变你的行业收入用痛点、反差、利益、颠覆认知开场,立刻锁住注意力2. 专业内容”降维翻译“:三层拆解·人话层:先讲这件事能干什么、解决什么问题·类比层:用生活常识打比方(把复杂技术比作喝水、开车、快递流程)·专业层:最后再补术语、原理、参数先懂逻辑,再听专业,观众才不会中途划走让我们从“深度流形”(技术型)与“假思考流行病”(认知型)这两个看似与“搞钱”没有任何联系的选题出发,聊聊ai怎么帮你做专业内容“降维翻译”(因为我就喜欢这种不搭噶的选题hhh)
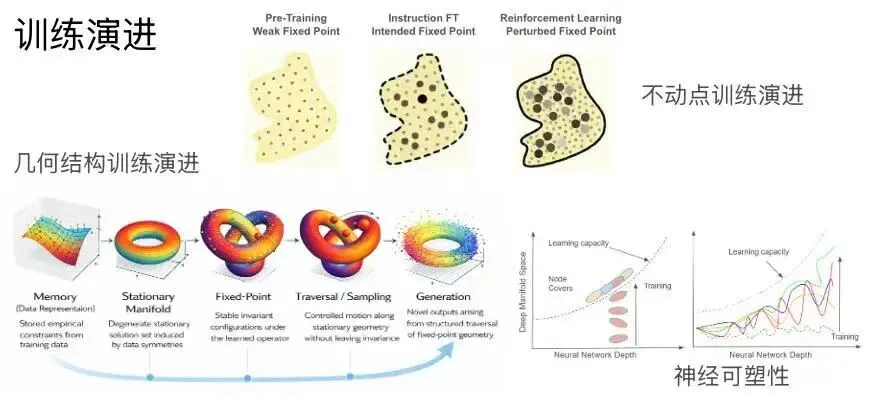
一、深度流形
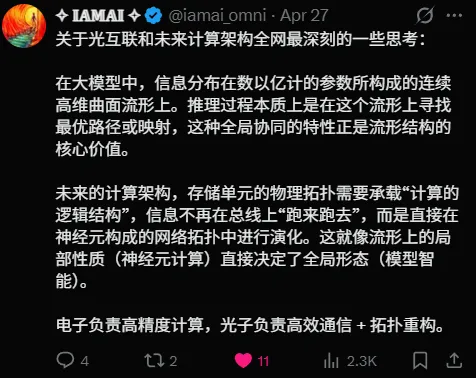
先了解一下基本概念从X@BetaTomorrow的一篇短文《Why Is Continual Learning Even Possible Mathematically? 为什么持续学习在数学上是可能的?》出发可能更易理解(因为这篇短文本身就是专业内容翻译)简体中文原文:持续学习为什么在数学上是可行的?要回答这个问题,我们需要退一步思考。数学解可以分为两大类:解析解与数值解。解析数学追求精确解:一个真正的不动点。经典数值计算则从精确解不再可得之处开始。它通过离散化、近似和迭代推进,通常借助微分和积分过程,获得一个收敛解,并非解析意义上的真实答案,而是一个平均解,或者我们称之为平均不动点。解析真不动点与数值平均不动点都是静态的,因为方程和坐标是给定且固定的。从这个角度来看,神经网络是一种数值计算吗?是的,毫无疑问。神经网络并不解析地推导解。它将数据离散化为层和权重,通过非线性激活进行近似,并通过微分和积分过程进行迭代。深度流形对此给出了精确的表述:它将神经网络的全局方程表示为不动点的拉格朗日形式,但这个不动点是动态且随机的。进一步地,深度流形指出坐标在每次迭代中都会发生变化。这种坐标变化是逆问题学习动力学的一部分。学习本质上是一个逆问题。理论上,神经网络可以无限期地训练,其对应的不动点也随之移动。深度流形将神经网络视为堆叠的分段流形,每个流形的方向在每次迭代中都会改变,用代数语言来说,这就是坐标变换。训练过程中的坐标变换,在数学上正是持续学习得以可能的根本原因。持续学习并非特例,也不是工程上的权宜之计。它是一个数值系统的自然行为,其平均不动点随着底层数据分布的演变而移动。接下来自然引出两个问题:如何使持续学习更加高效?以及是否存在根本性的极限?预训练基础模型已经包含大量不动点和许多捷径通路。这些捷径很像人类的直觉:快速、可靠,却大多不透明。我们往往对依赖直觉的系统感到不安,无论是人类还是机器,尤其是当这些通路对我们隐而不见时。这正是我们用强化学习构建推理模型的原因。从这个意义上说,持续学习不仅仅是新知识的积累。它是推理的生产过程,主要通过形成通向不动点的推理链路径来实现。这样的推理路径同时也能减少幻觉现象:幻觉往往出现在基础模型的捷径通路上.这个角度来看,GRPO等强化学习方法可以被视为曲率扰动。这类扰动之所以强大,在于它们能够重塑现有通路的几何结构,并孕育新的推理路径。但扰动不能是任意的,它必须有明确的方向;否则便是徒劳,因为许多通路已经在预训练和先前的强化学习轮次中形成。更重要的是,强化某条通路的扰动,可能同时削弱乃至破坏另一条通路。学习与灾难性遗忘正是从这里开始的,不是作为记忆失败,而是在共享流形上操作的几何必然结果。这重新定义了两个问题的框架。效率不在于训练得更快,而在于引导扰动使其相互增强而非相互冲突。持续学习的极限,也许不是硬件约束或数据约束,而是几何约束:一个给定容量的流形能够支撑多少条推理路径,才不至于导致相互破坏。总体而言,持续学习应在训练进程的框架下加以研究:涵盖不动点的演进、权重空间几何形变的演进,以及神经可塑性。正如我们所发现的,神经网络数学高度违反直觉且极其原始,常常超出我们的预期。然而,一旦我们看穿其表象,便能发现其中的优美、洗练与丰饶。我们不知道它究竟有多深;可能还需要30到50年的时间才能被完全理解。牛顿的微积分曾等待了200多年才获得其数学严密性,而这一基础最终是由我的合著者(石根华)在20世纪60年代后期、在他20多岁时通过“不动点类理论”所奠定的。在稍微了解深度流形后,我们可能很难一下子找到这与“搞钱”甚至日常生活的联系(这是因为人脑工作内存不够大、感知是碎片化输入、思维只能自下而上建构。要先拆要素做锚点,再靠关联编织成框架,无法直接凭空搭建整体结构)不妨问问ai,让我们找到与现实的联系:来自grok深度流形与传统流形学习的区别• 传统流形假设/流形学习(Manifold Hypothesis / Manifold Learning):高维数据实际躺在低维潜流形上,用于降维、可视化等(如 Isomap、LLE)• 深度流形(Deep Manifold):焦点不在数据分布,而在神经网络自身的内在几何。它把整个网络视为一个动态的、堆叠的分段流形空间,强调训练动态、不动点演化、坐标变换等,属于神经网络理论的新框架,而非数据降维工具这时ai已经帮你完成了”三层拆解“类比层拆解你会发现深度流形好像就在你的身边那么你就会开始做简单的总结:1.流形思考更像是底层逻辑,动态的、堆叠的分段流形空间在解析过程中不断调整迭代2.而传统流形学习更像是将较为平整的非线性数据保留原始几何结构,进行降维、降阶“摊开”、“简化”可分类管理的“潜流形”低维数据3.深度流形堆叠更像是一个空间中的,由多个变量组成的,非线性的层层片段(每层片段都会变换坐标来适应持续学习)这时你在ai的辅助理解下,又完成了专业层的拆解(加油,你马上就能输出爆款了!!!)最后一层,也是最需要ai帮助的一层:人话层回到“搞钱”,你需要找到深度流形的现实意义——能联系到观众生活的意义我找到的是与量子+ai未来计算架构的联系:首先来自X@iamai_omni 的思考其次来自X@Phoenixyin13的信息解读:中国首家专注AI+量子融合的实体公司量智开物(北京)科技有限公司正式在京成立创始人是清华大学高等研究院的教授翟荃(杨振宁的关门弟子)他的团队主要有三个收获:1. 抓住了1万多个原子 清华团队刚刚在实验里一次性抓住 10064个原子,直接打破美国加州理工之前的6100个纪录,进入万原子时代,量子计算的硬件底子一下变大了很多。2. 追风算法 解决了怎么快速摆弄这么多原子的问题。以前原子多了就乱,现在AI帮忙像追风一样快速精准重排,让万量级量子计算机真正能跑起来。3. 扁鹊量子纠错器 量子计算很容易出错,这个AI工具像老中医望闻问切一样,聪明地找出错误并纠正,大幅提升量子计算机的稳定性。或许再过几年,AI训练一个超级大模型不再需要烧掉一座小城市的电;新药研发、新材料发现,不用实验室试十年,而是用量子+AI在电脑里“秒”出来;甚至我们这些普通学生,都能用上量子加速的工具写论文、做实验。未来计算架构本质是深度流形的硬件具象化(用物理载体去动态拓扑连续演化的流形)而AI+量子融合的实体公司量智开物(北京)科技有限公司的正式成立,就是最前沿的实践落地当深度流形通过未来计算机与观众产生联系时(同时还有杨振宁身份的背书,前沿视角的稀缺价值)那么你的人话层自然解决了三个核心问题·能帮观众省钱、赚钱吗?·能帮观众少踩坑、省时间吗?·能帮观众提升认知、变强、不落后吗?完成了专业内容的“降维翻译”,你的视频怎么不会吸引人呢?聊到这里,我又有了新的感受,虽然信息到处都是,但筛选、解读、落地、信任、认知这五层差,永远抹平不了(原谅我不展开聊信息差这个话题,因为这与ai关系不大)
二、“假思考流行病”
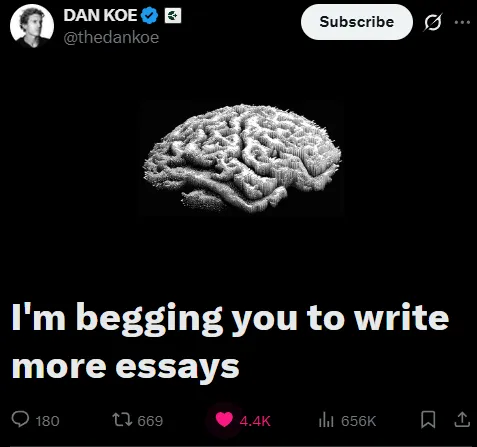
其实这与刚刚聊到的“已验证爆款“和信息差又联系到了一起(这就是大部分账号的运行思路:信息传递——形成认同——消费认同)回归正题“假思考流行病”这个概念来自X@thedankoe的长文《I’m begging you to write more essays》(这位老哥的长文很有意义,我建议尽量读一下原文,放完他的长文显得我太水了hhh)认知型内容翻译输出就好做得多,因为它本身就带有深刻的人文意义,比起技术性不需要太强的理解能力(也可能是我脑子不够用,get不到认知内容的深度hhh)还是按部就班,完成人话层,类比层,专业层的降维翻译先用问题现象引入(认知提升就是基于现有的不足)互联网没有死,但它正在杀死我们(点出问题根源)人话层完成,利用反差的问题勾起观众情绪再讲一个普遍现象:很多人每天刷新闻、看资讯,以为自己能”知情“,结果反而变得更自满、更厌世、更偏激,甚至更容易产生暴力情绪然后分析原因:网上大量的公开内容,比如社群贴文、短视频、影视音乐,如果带来的伤害比帮助多,又没有足够的有益内容来平衡,就会污染我们的认知环境说清后果:我们消费的内容,会塑造我们的身份,进而影响我们的行为和人生轨迹;同时,这些内容也在训练(或者摧毁)我们的注意力、容忍复杂事物的能力、接受矛盾的能力,以及分辨细微差别的能力类比层完成,观众开始联系实际并产生反思然后他们就会觉得“这跟我有关、对我有用”“你懂我、我认同你”价值认同不就来了吗,流量粉丝不就涨了吗接着就是专业概念的补充,用深度内容提高停留时间有三种力量,正在摧毁我们的思考能力,甚至威胁文明先讲这三种“威胁力量“:1.竞争性动态:就是“赢者通吃”的游戏,比如军备竞赛、企业抢市场、社群媒体抢注意力、学者抢着发表论文,大家只想着赢,忽略了长远价值;2.基质消耗:系统消耗基础资源的速度,超过了资源自身的再生速度。这里的资源不只是土壤、水,还有我们的注意力、人与人之间的信任——比如注意力经济,正在快速消耗我们的认知能力;3.指数型技术:技术自我加速,甚至超过人类智慧,比如AI能力不断翻倍、自动化武器、演算法快速升级,我们越来越难掌控。专业层done!最后给大家一个核心思考题(takeaway):你平时看的、发的内容,是能让你做出有益的改变,还是在悄悄毒化你自己和身边的人?认知型内容添加实践建议是很有必要的(这对涨粉有帮助),而这篇长文的标题就是在呼吁人们写长文。所以结尾建议自然就是有关写长文的(原文观点:在假思考泛滥、速食内容充斥的时代,写文章,是修复我们的心智、对抗认知毒化、创造人生意义,并且在意义经济中长期立足的最强工具之一)认知型说了这么多,好像没提到ai,其实我刚刚简单的提纲都可以用ai生成。在认知型内容上,ai甚至可以做得更好,因为这些观点并不新。而你,我的朋友,你只需要把这些爆款长文喂给ai,让它按着这三步走。为什么不自己写?ai的回答大部分时候比人更懂人,而你把不擅长的交给 ai,反而能提升你的核心能力
1.5最简单的起号选题
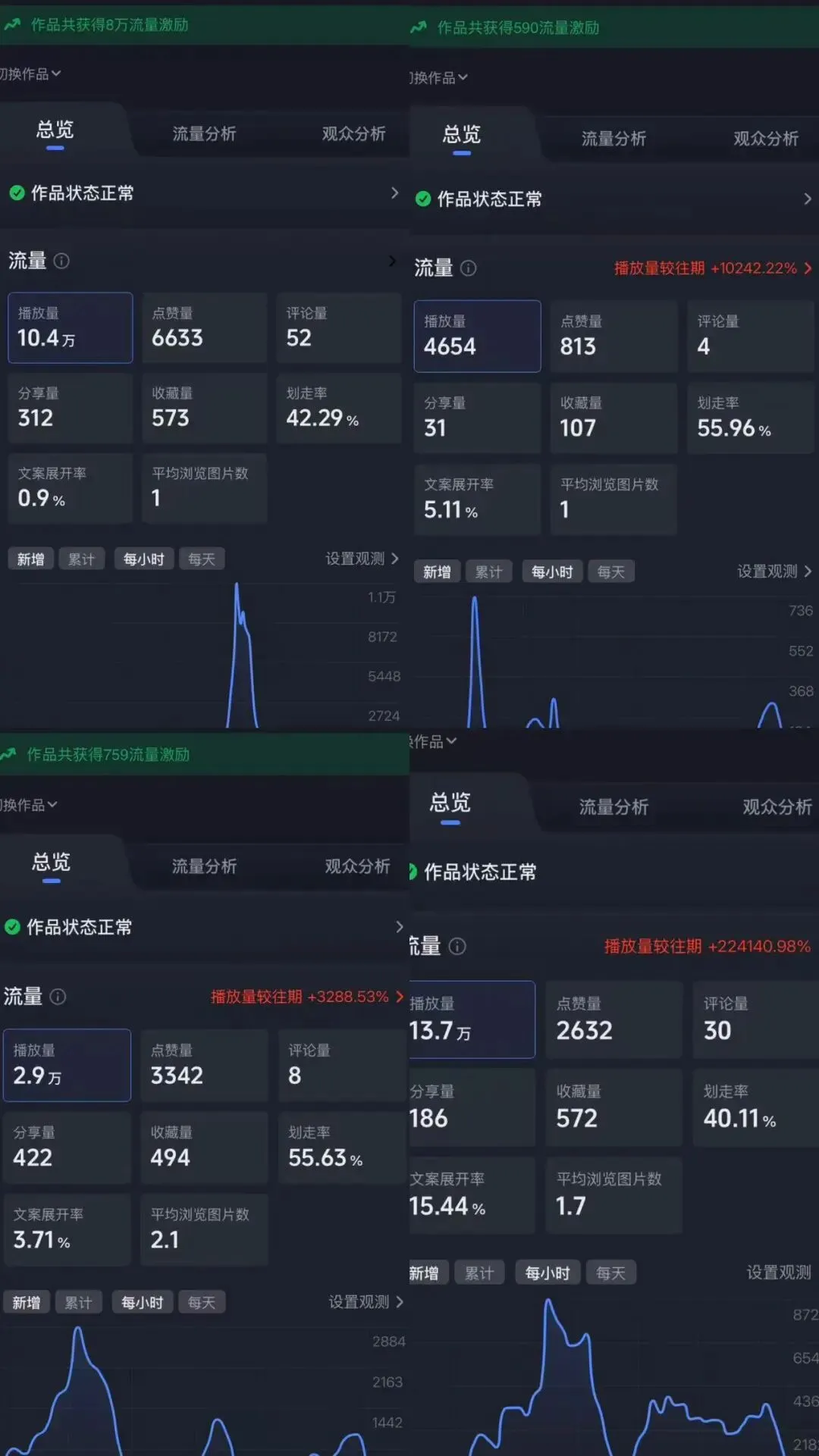
唉,还是要把焚诀交出来了吗这是流量来得最快,但也是最难变现的一种选题:做无版权 / 高质感风景素材分享、氛围感剪辑,或者是专门做壁纸 / 背景视频的二次创作,很多视频的播放量都不低,尤其是宇宙、风暴、经典 IP 改编类的内容,更容易出爆款这本质就是利用人类对宏大事物的好奇,满足震撼+治愈的情绪价值而且只需要简单运营(回复评论,点点赞)就能吃到激励流量,不需要关注私信(其实是根本没什么人私信你…….)BGM用系统推荐的就好,这些BGM会有一定的流量加成(具体我们放在算法分析来聊)ai可以用来做文案的输出,毕竟好的文案可以延长观众的停留时间(这没啥好聊的,我水一下就过了hhh)至于为什么抖音对ai又包容,又严格,我想用算法来解释会更清晰如果你有不一样的视角和思考,恳请我们私信交流我接下来的分析:
 夜雨聆风
夜雨聆风