 夜雨聆风
夜雨聆风





让AI学会“不穿模”:CoInteract如何用双流训练逼出物理直觉
CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
你有没有发现,现在的视频生成模型画人已经相当逼真了,可一旦让人拿起东西——比如演示一个水杯、拆个快递——立刻原形毕露:手指穿过杯壁、物体悬浮在手心、脸在快速转头时糊成一团。这几乎是所有 RGB-centric 扩散模型的通病:它们从像素里学到的只是外观关联,根本没有“物体表面不可穿透”这种物理概念。
清华大学与阿里合作的这篇 CoInteract,直接冲着这个痛点来了。他们没走传统那条“先检测关键点再约束生成”的绕路,而是在 Diffusion Transformer 骨架上同时训练两条流——一条正常生成 RGB 视频,另一条生成纹理剥离的“交互结构图”——并设计了一套专家路由来专门照顾手和脸。最妙的是,结构流只在训练时用,推理时一卸了之,零额外开销。
下面我们就来仔细拆解,他们是怎么让模型在看不见结构图的情况下,依然老老实实遵守物理规则的。
为什么现有方法总在“穿模”上翻车
先简单梳理一下现状。音频驱动的数字人已经能做出相当自然的说话动作,但一旦从“说话”升级到“演示产品”,难度陡增。目前搞 HOI 视频合成的路子大体分两种:
• 多条件控制流:提前提取每一帧的人体姿态、物体坐标等信息,作为条件喂给扩散模型。这需要繁重的预处理,泛化性也成问题,换个没见过的东西就容易崩。
• 多参考图注入流:直接给模型人物参考图和产品参考图,让模型自己学着组合。灵活是灵活,但缺乏显式的交互几何约束,结果就是手和物体经常出现穿模。
这些问题的根源,在于扩散模型从像素级损失里学不到 3D 空间关系和身体拓扑。它看到的只是“这里有一片肤色像素,那里有一片金属色像素”,至于肤色像素该停在金属像素前面还是后面,它没有先验。
CoInteract 的核心思路很朴素:与其让模型去猜,不如在训练时直接告诉它“正确的交互结构长什么样”。
核心方法:双流共生成 + 人体感知 MoE
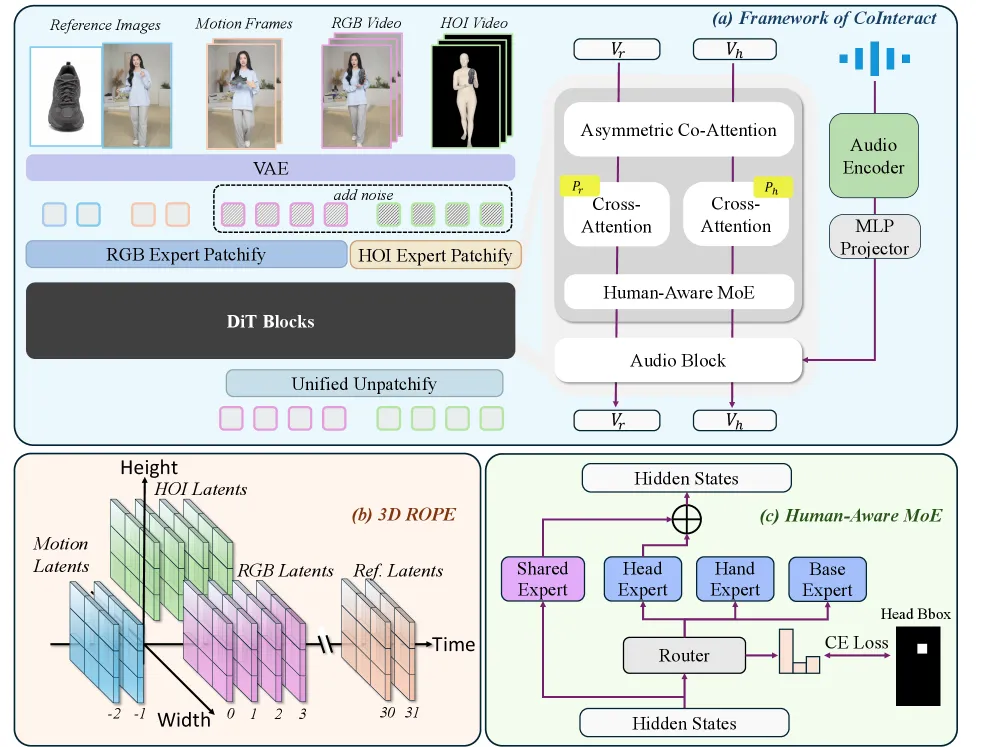
图1: 框架总览:双流 RGB-HOI 共生成与 Human-Aware MoE,HOI 分支推理时移除。
上面这张架构图把 CoInteract 的两大创新点串在了一起。左侧是双流输入:正常的 RGB 视频潜变量和辅助的 HOI 结构流潜变量,一起送进共享的 DiT 模块。右侧是插入在每个 DiT 块里的 Human-Aware MoE,通过空间监督的路由器把手和脸区域的 token 分发给专门的轻量专家。
我们分别展开。
双流共生成:给模型配一个“结构教练”
这里的设计非常巧妙。所谓 HOI 结构流,是把原始视频中的人物部分替换成人体网格投影(类似剪影),而物体部分保留原始 RGB 外观。这样一来,结构流清晰标出了人体轮廓与物体之间的接触边界,但去除了纹理、肤色等外观信息。
训练时,RGB 流和 HOI 流共享同一个 DiT 骨干的所有参数(注意力、FFN 等),只在自适应层归一化部分各自维护一套 scale/shift 参数。损失函数是两路的流匹配损失之和:
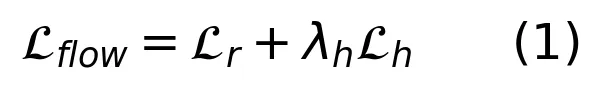
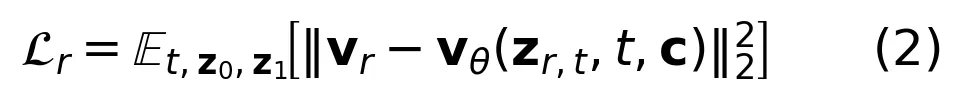
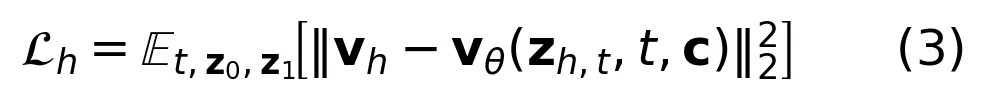
直觉上,这相当于让模型同时学两件事:一是“这个场景看起来应该是什么样”(RGB 流),二是“人和物体的空间关系应该怎么摆”(HOI 流)。由于骨干共享,模型被迫在内部形成对交互几何的表征,而不能只依赖外观捷径。
但这里有一个关键问题:如果两路一直双向注意,推理时就必须保留 HOI 分支,否则 RGB 流会因为缺少 HOI token 而输出异常。CoInteract 用了一个两阶段训练策略来解决。
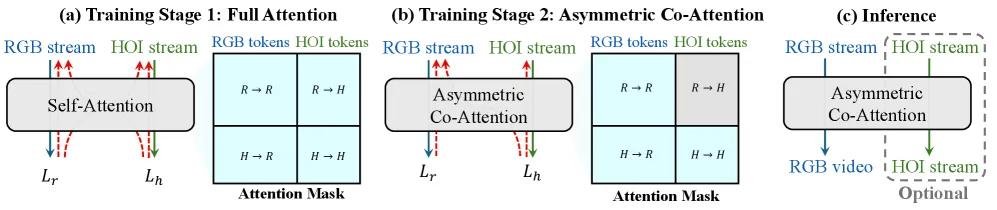
图2: 两阶段训练策略:Stage1 全注意力耦合双流,Stage2 非对称掩码使 RGB 独立。
如上图所示,Stage 1 采用标准双向注意力,让两路 token 充分交互,快速建立 RGB 与结构之间的对应关系。到了 Stage 2,他们引入一个非对称的注意力掩码:
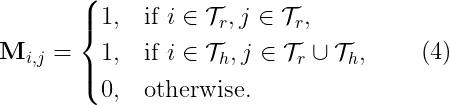
这个掩码的含义很清晰:RGB 查询只允许看 RGB 键,不能看 HOI 键;但 HOI 查询可以看所有 token,包括 RGB。这带来两个好处:
1. RGB 通路变得完全自给自足,推理时直接丢弃 HOI 分支即可,零额外计算。
2. HOI 损失通过 HOI→RGB 的交叉注意力回传到共享骨干参数,相当于 RGB 流在训练中“被动”吸收了结构监督。
3D RoPE:用坐标编码注入时空先验
要把运动帧、静态参考图、双流潜变量这么多异质输入塞进同一个 Transformer,位置编码必须精心设计。CoInteract 用 3D 旋转位置编码给每个 token 赋予 (h, w, t) 坐标,并做了几个关键设定:
• 双流空间对齐:RGB 和 HOI 在宽度维度上拼接,RGB 分配 w ∈ [0, W],HOI 分配 w ∈ [-W, 0],共享高度和时间索引。这样模型可以通过相对位置距离学习跨流对齐。
• 时间因果:历史运动帧用负时间索引(t ∈ -N, , -1\),生成帧用正索引,让模型自然理解时间先后。
• 参考图远场锚定:静态参考图被映射到极远的时间位置(如 t=30,31),迫使模型把它们当成全局身份锚点,而非相邻帧。
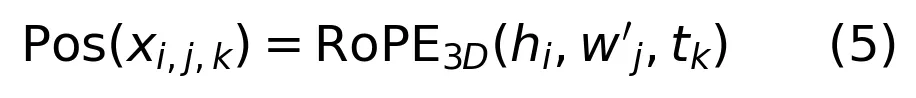
这种显式的时空结构化编码,比让模型自己从数据里硬学位置关系要高效得多,尤其对于需要精确时空对齐的 HOI 任务。
Human-Aware MoE:手和脸的“专科门诊”
即使有了结构流监督,手和脸这些高频细节区域仍然容易出问题。CoInteract 在 DiT 的 FFN 层引入了一个轻量的 Mixture-of-Experts 模块。
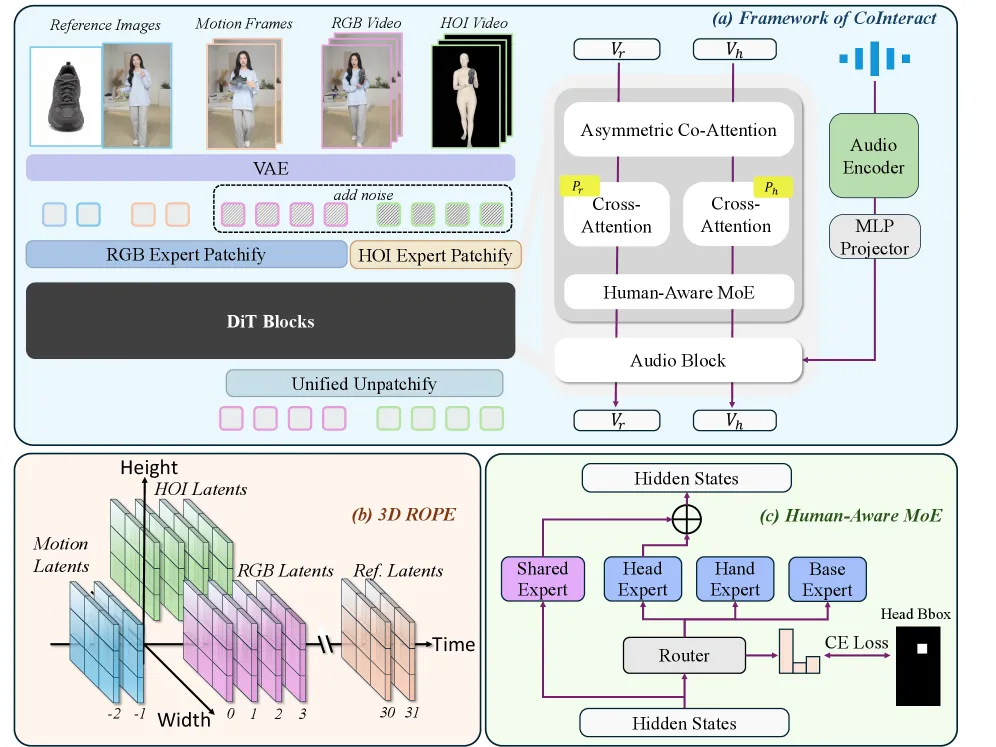
图3: Human-Aware MoE 路由机制:空间监督路由器将头、手 token 分发给区域专家。
这个 MoE 包含四个专家:一个共享专家直接复用原 DiT 的 FFN 作为捷径,外加三个轻量专家——Head、Hand、Base——每个只是隐层维度 256 的小 FFN。路由器是一个两层的 MLP,训练时通过人脸和手部检测框提供空间监督:
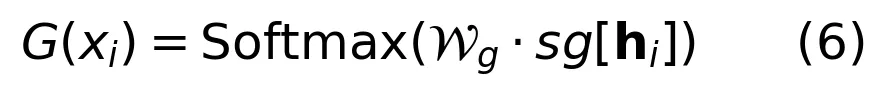
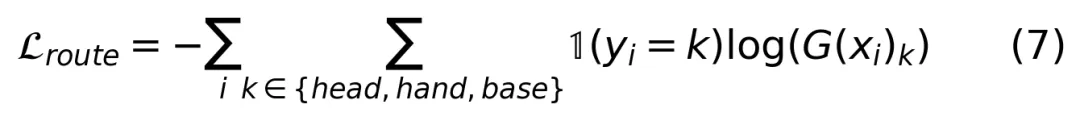
注意那个 sg[·] 是 stop-gradient 操作,目的是防止路由优化干扰 DiT 的主干表示学习。总损失为:
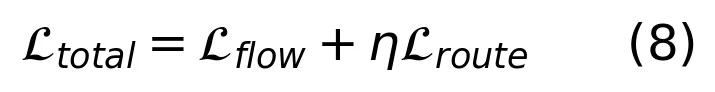
这套设计的聪明之处在于,它用极小的参数增量(仅 1.04× 推理开销)换来了手部清晰度和人脸身份一致性的显著提升。而且因为路由是空间监督的,不像普通 MoE 那样需要负载均衡损失,训练更稳定。
数据是怎么准备的

图4: 数据预处理流程:从原始视频构建成对的 RGB 与 HOI 结构表示。
上图展示了从原始 HOI 视频到训练数据的完整管线。首先用 Qwen-Edit 解耦人物和产品,生成独立的参考图,再经过一个验证模块过滤不匹配的三元组。几何监督方面,用 SAM3 提取物体掩码,用 SAM3D-body 恢复人体网格并投影到图像平面,融合后形成纹理剥离的 HOI 结构流。最后,RGB 视频和 HOI 结构流通过预训练 VAE 编码到共享潜空间。
这套流程保证了结构流的像素级对齐,让模型能在训练中精确学习交互边界。
实验结果:数字会说话
论文在 12K 高质量 HOI 视频片段上训练,测试集 50 个片段覆盖多种品类和未见身份。对比方法包括 AnchorCrafter、Phantom、Humo、VACE、InteractAvatar、SkyReels-V3 等近期工作。
定量对比
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| CoInteract | 0.554 | 0.749 | 0.9951 | 0.72 | 0.724 | 0.671 | 0.624 | 0.696 | 5.87 |
解读:
• VLM-QA 上 CoInteract 拿到 0.72,比第二名 InteractAvatar 高出 10 个百分点,说明 Gemini-3-Pro 判断它的交互更合理。
• HQ(手部质量)以 0.724 领先,比去掉 MoE 的变体高出近 7 个点,验证了区域专家的有效性。
• DINO_id 和 FaceSim 均为最优,说明身份保持能力最强。
• AES 略低于 Phantom 和 Humo,但这是因为后两者倾向于“脑补”出更美观但与参考图不一致的背景,CoInteract 则忠实保留参考场景,牺牲了一点美学分换来了更高的一致性。
用户调研
24 名评估者对三个维度打分(均值排名,越低越好):
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
2.17 |
|
|
|
|
|
|
|
|
1.92 |
|
|
|
|
|
|
|
|
1.79 |
解读:
• 三个维度全部第一,交互合理性优势最大(1.79 vs 第二名 3.33),与 HOI 结构流的设计目标完全吻合。
• InteractAvatar 在物体一致性上表现不错(3.08),得益于 Qwen-Image 合成的初始帧质量高,但交互合理性仍不如 CoInteract,说明初始帧好不代表整个序列的物理约束能持续。
定性结果

图5: 与现有方法定性对比,CoInteract 交互保真度更高且更贴合输入提示。
上面这张对比图很能说明问题。其他方法在不同程度上出现了手-物穿模、产品外观漂移、背景偏离参考等典型失败模式。AnchorCrafter 在训练集内见过的物体上表现尚可,但遇到未见物体时身份漂移明显。InteractAvatar 虽然有强初始帧,但随着生成进行,抓取姿势逐渐变得不自然。CoInteract 则在整个序列中保持了物理上合理的交互和结构稳定。

图6: 双流共生成与 MoE 路由可视化,HOI 流与 RGB 流时空对齐,路由精准分离手脸区域。
这张内部机制的可视化非常有说服力。上半部分显示 HOI 结构流与 RGB 视频帧精确时空同步,即使在打开垃圾桶盖子这种剧烈动作下,结构骨架依然稳固,为 RGB 生成提供了可靠的几何约束。下半部分的路由热力图表明,MoE 路由器能准确锁定人脸和手部 token,把它们分发给对应的专家处理,从而在快速运动中保持高频细节。
消融实验
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Full Model | 0.554 | 0.749 | 0.995 | 0.72 | 0.724 | 0.671 | 0.624 | 0.696 | 5.87 | 1.04× |

图7: 消融实验定性对比,去除共生成导致交互不自然,去除 MoE 导致手部坍塌与面部模糊。
解读:
• 去掉 MoE 后,HQ 从 0.724 跌到 0.658,FaceSim 从 0.696 跌到 0.662,证明区域专家对手脸质量的贡献是实实在在的。
• 去掉共生成(即纯 RGB 单流训练)是杀伤力最大的操作:VLM-QA 直接腰斩到 0.48,降幅 33.3%。这说明没有结构流教练,模型根本学不会物理交互约束。
• 保留 HOI 分支推理(w/o Asym. Mask)虽然 VLM-QA 和 HQ 略有提升,但推理开销暴涨到 4.13×。CoInteract 用两个点的交互分换来了近 4 倍的推理加速,这个 trade-off 非常划算。
个人视角:为什么这件事值得关注
CoInteract 的真正贡献不在于它又刷了几个 SOTA 指标,而在于它提供了一套可推广的“结构注入”范式。
传统思路是“先检测再约束”——用外部模型提取姿态、分割,然后作为条件输入。这条路的问题在于,外部模型本身就有误差,而且模型并没有真正内化物理规则,只是在条件信号的“拐杖”下走路。一旦条件信号不准或缺失,立刻摔跤。
CoInteract 换了一种思路:让模型在训练时亲眼看到正确的结构,然后通过巧妙的注意力掩码设计,把这种结构理解内化到共享参数里,推理时不需要任何额外输入。 这类似于老师上课时给你看解题步骤,考试时你虽然看不到步骤了,但思路已经刻在脑子里。
这种“训练时多流、推理时单流”的范式,其实可以迁移到很多其他任务上。比如,训练时加一流通用深度图或法线图来监督 3D 一致性,推理时去掉;或者训练时加一流通用分割图来改善物体边界,推理时去掉。CoInteract 的非对称注意力掩码提供了一个干净的模板。
当然,这篇工作也有几个明显的局限:
1. 数据依赖:HOI 结构流的构建需要人体网格恢复和物体分割,这两个步骤的精度直接影响训练质量。SAM3 和 SAM3D-body 虽然强,但在严重遮挡、极端姿态下还是会出错,这些错误会被模型学到。
2. 结构流的信息瓶颈:目前 HOI 流是纹理剥离的剪影+物体 RGB,虽然能标出接触边界,但缺乏深度信息。对于需要精确 3D 理解的复杂操作(如拧瓶盖),仅靠 2D 投影的边界约束可能不够。
3. MoE 路由的泛化性:空间监督的路由器依赖检测框,对于训练集中没见过的极端视角或遮挡情况,路由可能不准。论文没有讨论这方面的鲁棒性。
后续值得关注的方向:一是把结构流从 2D 剪影升级为带深度的 2.5D 表示,甚至直接引入点云监督;二是探索更灵活的 MoE 路由策略,比如用可学习的 token 聚类代替固定的空间监督,让模型自己发现哪些区域需要专门处理;三是把这种范式推广到多人物、多物体的复杂交互场景。
一句话总结:CoInteract 用双流训练和区域专家,给视频扩散模型装上了“物理直觉”,而且这套机制推理时完全隐身——这可能是 HOI 视频生成走向实用的关键一步。
❤️❤️❤️如果这篇内容对你有帮助,欢迎点个赞、点个在看,也欢迎转发给更多有需要的朋友。你的每一次互动,都是我持续更新的动力。❤️❤️❤️
论文原文: https://arxiv.org/abs/2604.19636