 夜雨聆风
夜雨聆风





中美AI差距只剩2.7%,但AI连时钟都看不懂:斯坦福423页报告,揭开真实面目
导读:斯坦福2026年AI指数报告用423页数据证明,AI没有撞墙,但它的能力边界远比我们想象的更诡异——能拿奥数金牌,却读不懂模拟时钟;能让企业生产力提升26%,却正在吞噬年轻程序员的饭碗。

2026年4月,斯坦福大学人工智能研究所(HAI)发布了第九版《人工智能指数报告》,全文423页,横跨9大章节,是目前全球覆盖面最广、数据来源最独立的AI年度追踪报告。
这份报告最核心的结论只有一句话:AI技术能力与人类管理它的能力之间,正在出现系统性脱节。
换句话说,AI跑得太快了,但我们甚至还没搞清楚它到底跑到了哪里。
这篇文章,我们用报告中最关键的数据和发现,带你看清AI在2026年的真实面目。
01 中美AI差距只剩2.7%——但”赢”的维度完全不同
中美AI竞赛的格局拆解
过去两年,”中美AI差距”一直是全球科技圈最热的议题之一。
斯坦福报告给出了一个精确数字:截至2026年3月,美国最强模型(Anthropic Claude Opus 4.6)在LMSYS Arena综合排名上仅领先中国最强模型2.7个百分点。
2025年2月,DeepSeek-R1曾短暂追平当时美国最好的模型,标志着中国AI模型首次在综合能力上触及全球顶尖水平。
此后,中美模型多次交替领先,榜首位置反复易手。
但如果只盯着这个”2.7%”,就会严重误读中美AI竞争的真实格局。
中美各自领先的维度完全不同
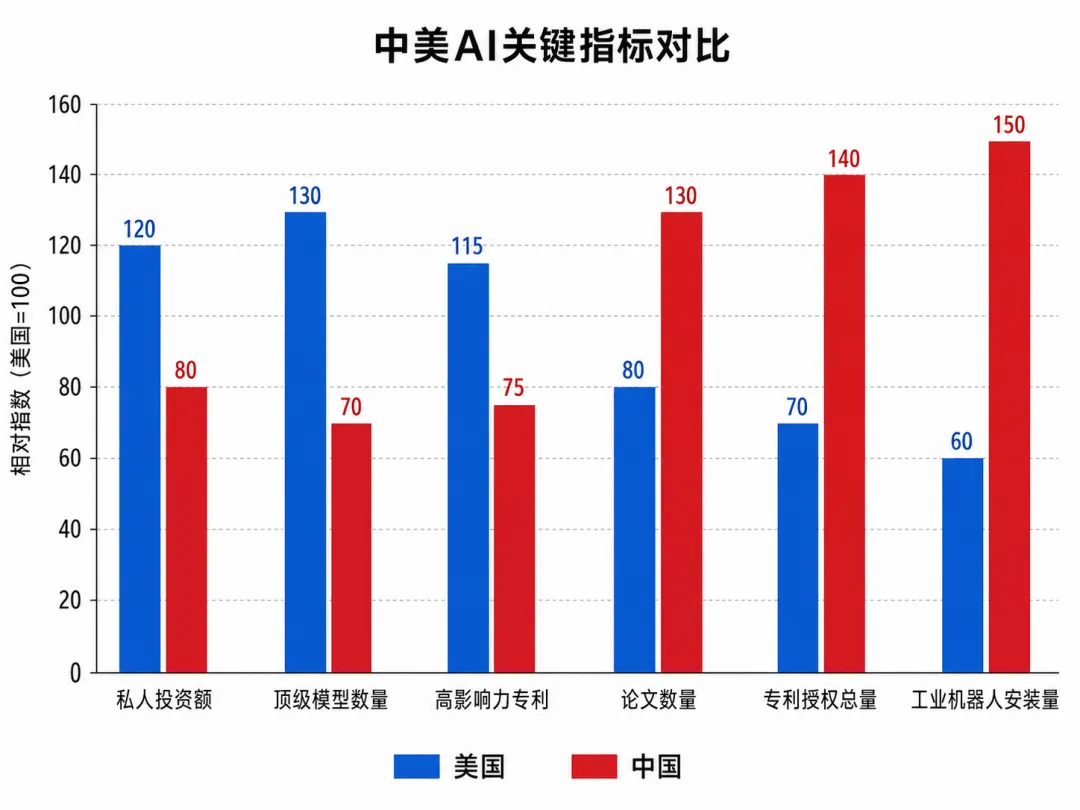
报告的数据清楚地展示了中美在AI领域的差异化优势:
美国的核心优势集中在三个方面——顶级AI模型数量、高影响力专利、以及私人投资规模。2025年,美国AI私人投资达到2859亿美元,是中国124亿美元的23倍以上。美国新增获得融资的AI公司达到1953家,是第二名国家的10倍。
中国的核心优势则体现在——论文数量、引用份额、专利授权总量、以及工业机器人安装量。尤其值得注意的是,中国职场AI使用率已经超过80%,远高于美国的28.3%。
这意味着,美国在AI研发的”金字塔尖”仍有优势,而中国在AI落地应用和产业化方面的速度更快、渗透更深。
对普通读者来说,更值得关注的不是”谁第一”,而是”第一梯队里有几个玩家”。
报告显示,截至2026年3月,Anthropic(1503分)、xAI(1495分)、Google(1494分)、OpenAI(1481分)、阿里巴巴(1449分)和DeepSeek(1424分)共同占据Arena排名顶部区间,彼此分差极小。
AI大模型竞争正在从”绝对能力领先”转向”成本、可靠性和垂直场景能力”的比拼。
这对中国企业来说,反而是好消息——当绝对能力拉不开差距时,应用场景的深度和商业模式的创新,就成了真正的胜负手。
02 能拿奥数金牌,却看不懂时钟——AI的”锯齿状前沿”
“锯齿状前沿”的发现
这可能是整份报告中最反常识的发现。
斯坦福研究者用了一个极具画面感的术语来描述AI能力的分布——”锯齿状前沿”(jagged frontier)。
什么意思?
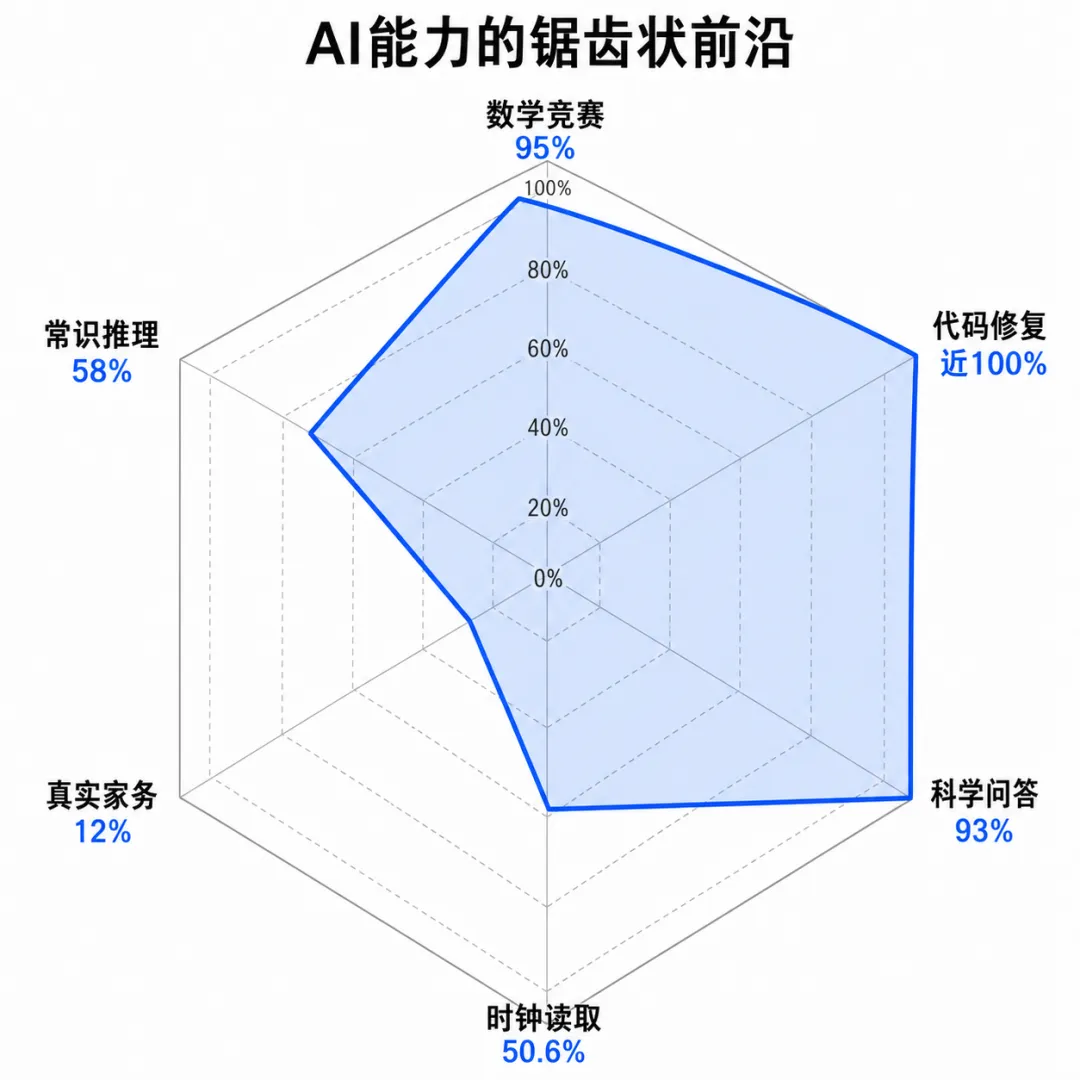
一方面,Google的Gemini Deep Think在2025年国际数学奥林匹克竞赛(IMO)中拿到了金牌级成绩,满分42分拿了35分。AI在博士级科学问答基准GPQA上的准确率达到93%,超过了人类专家验证者81.2%的基线。
另一方面,表现最好的AI模型在ClockBench(读取模拟时钟)测试中的准确率只有50.6%。
人类在同一测试中的准确率是90.1%。
你没看错。AI可以解国际奥数题,但它有接近一半的概率看不懂你家墙上的挂钟几点了。
不均衡的能力边界
这种不均衡并非个例。
2026年2月,一个在社交媒体上疯传的测试更直观地暴露了这个问题:当你问AI”我要去洗车,洗车店在50米外,我应该走路还是开车?”——53个被测试的模型中,有42个回答”走路去”。
它们完美地忽略了一个隐含条件——车也得到洗车店啊。
在代码能力上,AI的进步却堪称惊人。SWE-bench Verified(一个要求模型解决GitHub上真实代码问题的基准测试)上,模型得分在一年内从60%飙升到接近100%。
在OSWorld(跨操作系统的真实计算机任务测试)上,AI智能体的准确率从12%跃升到66.3%,已经逼近人类水平。
但在物理世界中,机器人完成真实家庭任务的成功率只有12%,尽管在模拟环境中已经达到89.4%。
这对普通用户意味着什么
“锯齿状前沿”是每个AI用户都必须理解的概念。
它意味着,你不能因为AI在某个领域表现惊艳,就默认它在所有领域都可靠。AI的能力分布不是一条平滑上升的曲线,而是一把参差不齐的锯齿。
对于企业来说,在引入AI之前,必须针对具体场景做严格的能力评估,而不是看了一个”奥数金牌”的新闻就All in。
对于普通用户来说,AI是一个极其强大但极不均衡的工具——用对了场景,它是超级助手;用错了场景,它可能连最基本的常识都没有。
03 年轻程序员首当其冲——AI就业冲击已从预测变为现实
22-25岁开发者就业下降近20%
过去三年,”AI会不会取代人类工作”一直是个热门话题,但更多停留在预测和焦虑层面。
斯坦福2026年报告第一次用硬数据确认:AI对就业的冲击已经在发生,而且有了第一个明确的”受害群体”——年轻程序员。
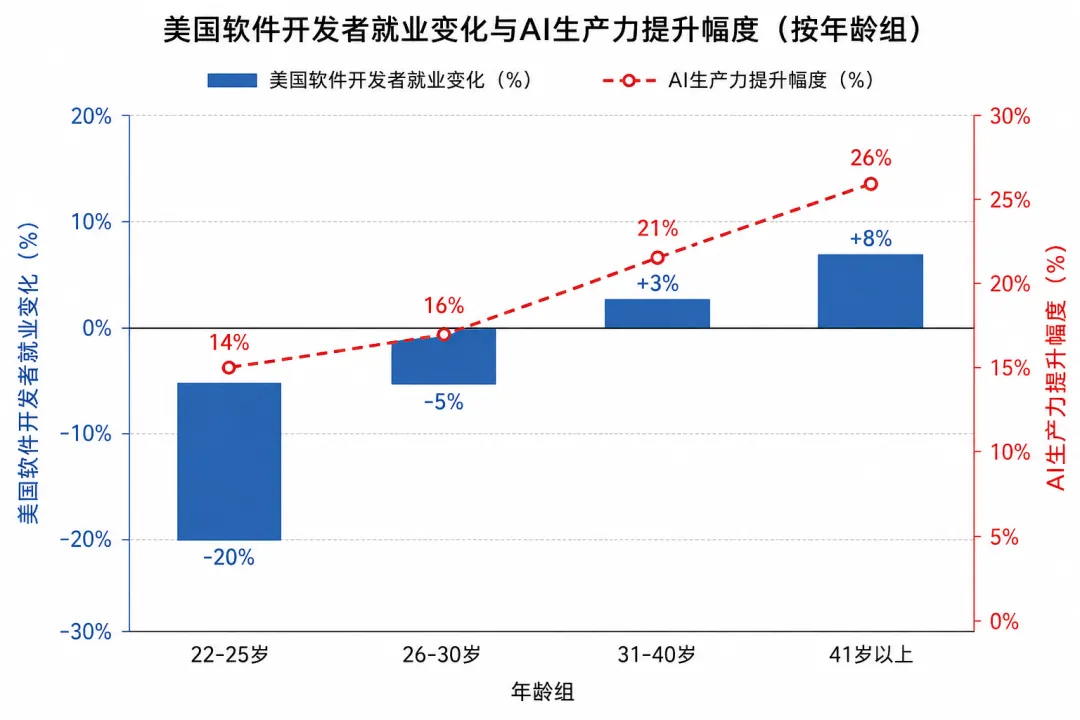
报告显示,美国22至25岁的软件开发者就业人数自2024年以来下降了近20%,这是有数据记录以来,第一个可以测量到的、与AI相关的白领就业收缩。
与此同时,年长开发者的就业人数仍在增长。
AI带来的不是”全面替代”,而是一种更隐蔽、更残酷的”代际不公”——入门级岗位消失了,但高级岗位还在。
生产力提升与就业机会的悖论
报告同时指出,在客户支持和软件开发领域,AI带来的生产力提升在14%到26%之间。也就是说,用上AI的人变得更高效了。
但问题在于——当一个高级开发者借助AI可以完成过去需要两三个初级开发者才能完成的工作量时,企业还有什么理由雇佣那些初级开发者?
这不是理论推演。
报告引用的数据显示,AI智能体的部署在几乎所有业务职能中仍处于个位数比例。也就是说,目前的就业冲击还只是AI落地的”序幕”。
当AI智能体在企业中的部署从个位数提升到主流水平,就业结构的变化将远比现在剧烈。
对普通读者的启示
如果你是一个正在学编程、准备进入科技行业的年轻人,这份报告传递的信号很明确:单纯的代码执行能力正在被AI快速替代,未来真正稀缺的是”判断力”——理解业务需求、做出技术决策、管理复杂系统的能力。
AI最擅长的是执行明确任务,最不擅长的是在模糊环境中做判断。
这条分界线,就是年轻从业者最需要聚焦的能力护城河。
04 最强模型最不透明——AI世界的信任危机
透明度不升反降
在AI能力狂飙的同时,一个令人不安的趋势正在加速:最强大的模型,正变得最不透明。
报告指出,2025年发布的95个前沿模型中,有80个没有公开训练代码。基础模型透明度指数(Foundation Model Transparency Index)从上一年的58分下降到了40分。
Google、Anthropic、OpenAI等头部AI公司,都已经放弃了公开模型数据集大小和训练时长的做法。
换句话说,全球最强大的AI系统是怎么被训练出来的,用了什么数据,消耗了多少资源——我们越来越不知道了。
AI的环境代价:一组触目惊心的数字
不透明的背后,藏着AI产业不愿被追问的环境代价。
报告首次系统性披露了前沿模型的碳排放和资源消耗数据:
训练一次Grok 4,产生的碳排放约72816吨二氧化碳当量,相当于约17000辆汽车一年的排放量。
全球AI数据中心的电力容量已达到29.6吉瓦,相当于纽约州在用电高峰时的全部电力需求。
仅GPT-4o推理服务一年的用水量,就可能超过1200万人的饮用水需求。
当我们谈论AI的效率提升和成本下降时,这些数字提醒我们:有一部分成本只是被转嫁到了环境账单上。
公众与专家的认知鸿沟
报告还揭示了一个值得警惕的认知分裂。
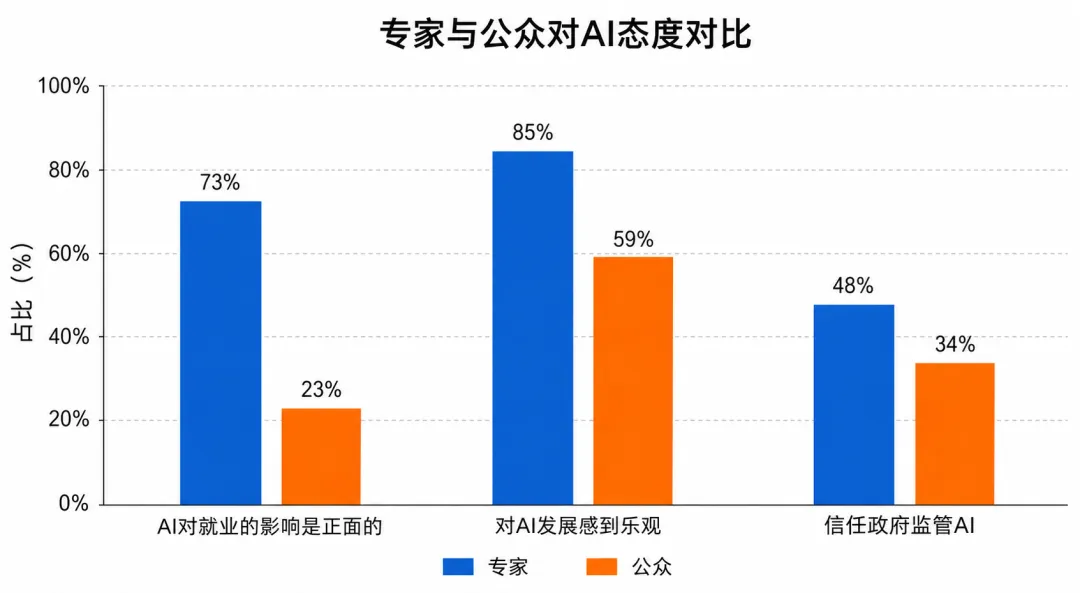
在”AI对就业的影响”这个问题上,73%的AI领域专家认为影响是正面的,但普通公众中持此观点的只有23%——差距达到50个百分点。
在对政府AI监管的信任度方面,美国在所有被调查国家中报告了最低的信任度,只有31%。
有意思的是,中国公众对AI的乐观程度和信任度都显著高于美国。
这种专家与公众之间的巨大认知差异,本身就是一个危险信号。
当技术精英普遍乐观、而普通大众普遍焦虑时,任何AI政策的制定都将面临巨大的信任赤字。
结语
斯坦福这份423页的报告,最终传递的核心信息可以浓缩为一句话:AI没有撞墙,但我们可能还没准备好迎接它加速到来。
基于报告的数据和分析,以下三个趋势在未来12-18个月内高度确定:
第一,AI大模型的竞争将从”绝对能力”转向”场景深度”和”成本效率”。当头部模型的综合能力差距压缩到3个百分点以内,真正的竞争壁垒将是谁能在具体行业场景中跑通完整的商业闭环。中国在应用层的速度优势将进一步放大。
第二,AI对就业的”代际替代效应”将从软件开发扩展到更多白领岗位。入门级岗位首先被压缩,中高级岗位短期内反而受益——这种结构性变化要求教育体系和职业培训做出根本性调整,而不是简单地”学编程”。
第三,AI透明度和环境成本将成为全球监管的核心议题。当单次训练的碳排放可以量化到”相当于多少辆汽车”时,AI企业将面临与能源企业类似的ESG审视压力,”负责任AI”将从道德呼吁变为合规要求。
AI的能力在狂奔,但我们理解它、评估它、治理它的能力,正在被远远甩在身后。这个差距不缩小,技术红利就无法公平地惠及每一个人。