代码改了8轮,文档还是第1版?我开源了一个专治Agent健忘症的Skill
有没有这种经历:你让AI Agent帮你改了一个多月的项目,代码重构了三轮,接口换了两批,数据库从SQLite切到PostgreSQL再切到TiDB……
然后有一天你打开项目的CLAUDE.md,发现里面写的还是“本项目使用SQLite”。再看看AGENTS.md,接口列表跟实际路由完全对不上。Agent的记忆里还在告诉新任务:“这个项目用的是SQLite”。
这就像一个每天练习新技巧的球员,但教练的战术板上还是他刚进队时的体能数据。
代码和文档之间的裁缝越来越大,最后连你自己都忘了到底改了什么。Agent在这种环境里工作,就像在一个持续加速的生产线上开车,路却是一张老地图。
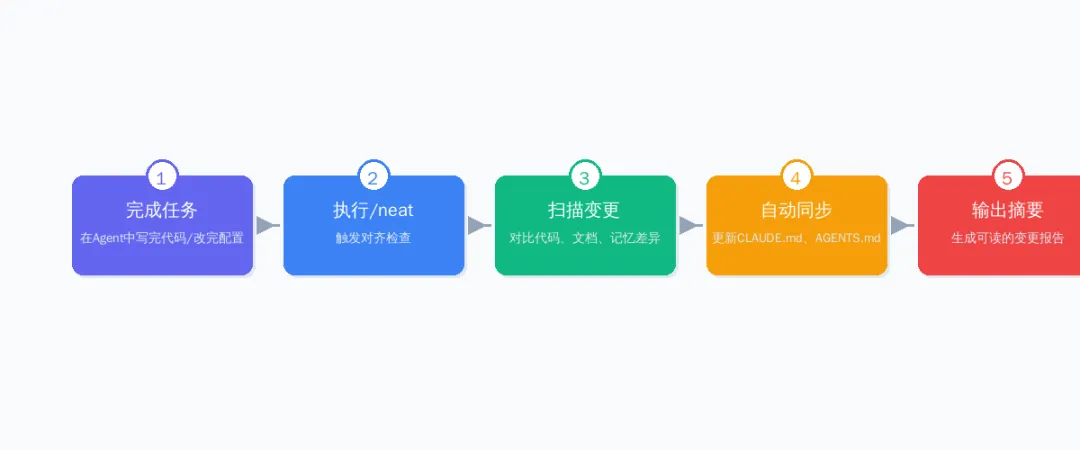
简单来说,它是一个给AI Agent用的“收尾工具”。每次你在Agent里做完一个任务,执行一个命令:
1. 扫描变更 — 对比你这次会话修改的代码和项目文档的差异
2. 自动对齐 — 更新CLAUDE.md、AGENTS.md和Agent记忆
用过AI Agent写代码的人都知道,Agent有一个天然的“短视颜命”:它只关注当前任务,很少回头检查自己留下的“尾巴”。你让它写一个API,它写得很开心,但不会想起来去更新接口文档。
文档沉没:代码里早就用上PostgreSQL了,但docs/目录下的部署文档还在教人家怎么安装SQLite。新来的同事照着文档操作,结果报错了一下午。
记忆错位:Agent的记忆系统里写着“使用MVC架构”,但实际上你上周已经把项目重构成了模块化方式。Agent在进行新任务时,会基于过时的记忆做出错误决策。
配置脱节:CLAUDE.md里的环境变量、构建命令、技术栈信息,和实际代码库已经不是一个世界。Agent在这个基础上继续工作,等于在沙滩上盖楼。
传统解决方案是“靠人”——靠开发者自己记得去更新。但人的记性是有限的,特别是当项目进入高速迭代期,每天有几十个提交的时候。
执行 /neat 后,你会收到一份类似Git提交日志的变更摘要:
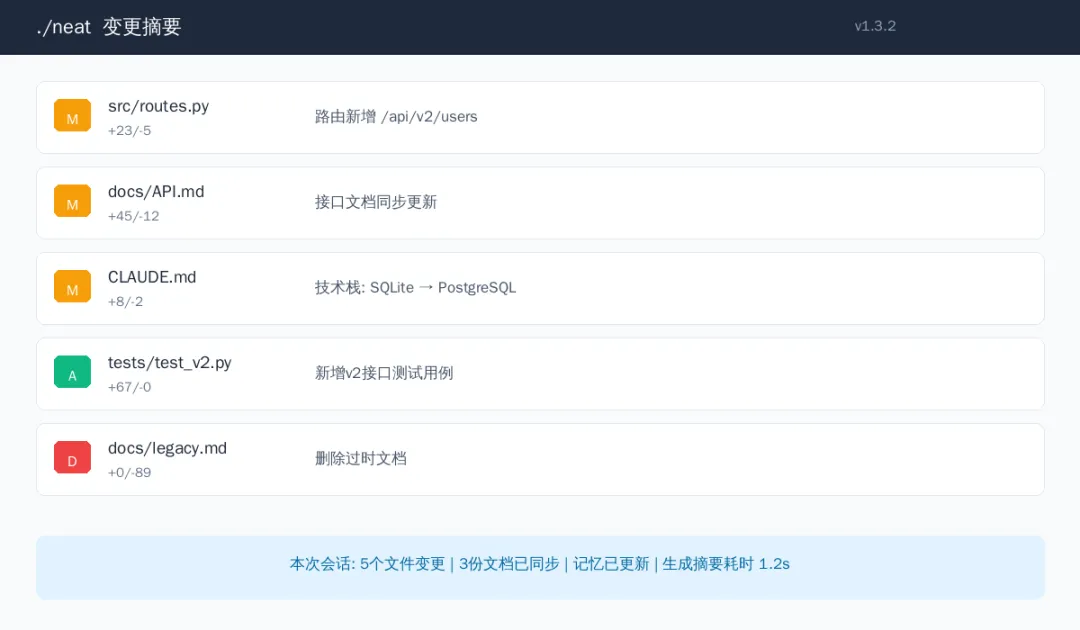
这份摘要不仅列出了哪些文件被修改、增加或删除,还会明确标注每一项变更对应的文档同步状态。你不需要手动检查每个文件夹,一眼就能知道项目的“健康状况”。
最关键的是:这些同步操作是自动的。你不需要手动复制粘贴,不需要记忆哪份文档该更新,不需要担心遗漏。运行一条命令,全部搞定。
目前这个Skill主要为Claude Code、Cursor等支持命令行的Agent环境设计。安装和使用都很简单:
git clone https://github.com/yourname/neat-freak.git
cd neat-freak && ./install.sh
/neat –sync –summary=detailed
它会自动识别你的项目结构,查找相关的文档文件(CLAUDE.md、AGENTS.md、README.md等),然后将代码变更与文档内容进行对比和同步。
支持的文档类型:CLAUDE.md / AGENTS.md / README.md / docs/目录下的所有markdown
支持的同步范围:技术栈、API接口、环境变量、构建配置、数据库方案
输出格式:简洁摘要 / 详细报告 / JSON格式(可配合CI使用)
这个Skill我自己已经用了一个多月,迭了七八个版本。最开始只是解决自己的痛点,但越用越觉得,这不是一个人的问题,而是所有用Agent开发的人都在面对的问题。
AI Agent的核心仸值是“减少重复劳动”,但如果它自己在生产过程中不断创造新的“重复劳动”——文档与代码不同步、记忆与现实脱节——那这个工具的仸值就大打折扣。
“洁癖.Skill”的意思,就是让Agent也有一点“洁癖”——做完一件事,必须把台面收拾干净。这不是鸡毛蒜皮的形式主义,而是对项目健康度的必然要求。一个连自己改了什么都记不住的团队,是不可能可持续的。
开源的目的不是让所有人都用一模一样的方案,而是想听听你们在实际使用中遇到的问题。
你的项目里有哪些“文档与代码不同步”的痛点?欢迎留言分享。
 夜雨聆风
夜雨聆风