 夜雨聆风
夜雨聆风





工业软件架构实录:状态机设计、领域划分与三次重构的决策复盘
工业软件的架构文章,大多在讲「怎么做好」。但这篇想讲的是另一件事:为什么选这个方案,而不是那个。
以一套 TOS(码头操作系统)的架构演进为主线,拆三个阶段的设计决策、技术选型和踩过的坑。每部分配一张架构图,最后附一个可直接套用的决策框架。
一、工业软件架构的核心矛盾
先明确一个前提:工业软件和互联网软件的架构出发点完全不同。
互联网软件追求的是弹性——流量来了能扩容,流量走了能缩容。数据可以最终一致,用户刷新一下就好。
工业软件追求的是确定性——一个集装箱从进场到上船,经过闸口、堆场、泊位、船舶四个环节,每个环节的状态变更都必须精确且可追溯。状态错了,后续所有指令都会跟着错,而且没有「刷新重试」这个选项。
三个核心约束决定了架构选型的方向:
状态一致性 > 可用性 > 演进灵活性。 这不是理论排序,是生产事故排出来的。
15 年的生命周期。 中间要经历数据库迁移、硬件换代、协议升级,架构不能让这些变成推倒重来的理由。
断网自理。 码头网络说断就断,边缘节点必须有自治能力,能独立运行至少 30 分钟。
二、第一版:单体架构 + 统一状态机(2009-2012)
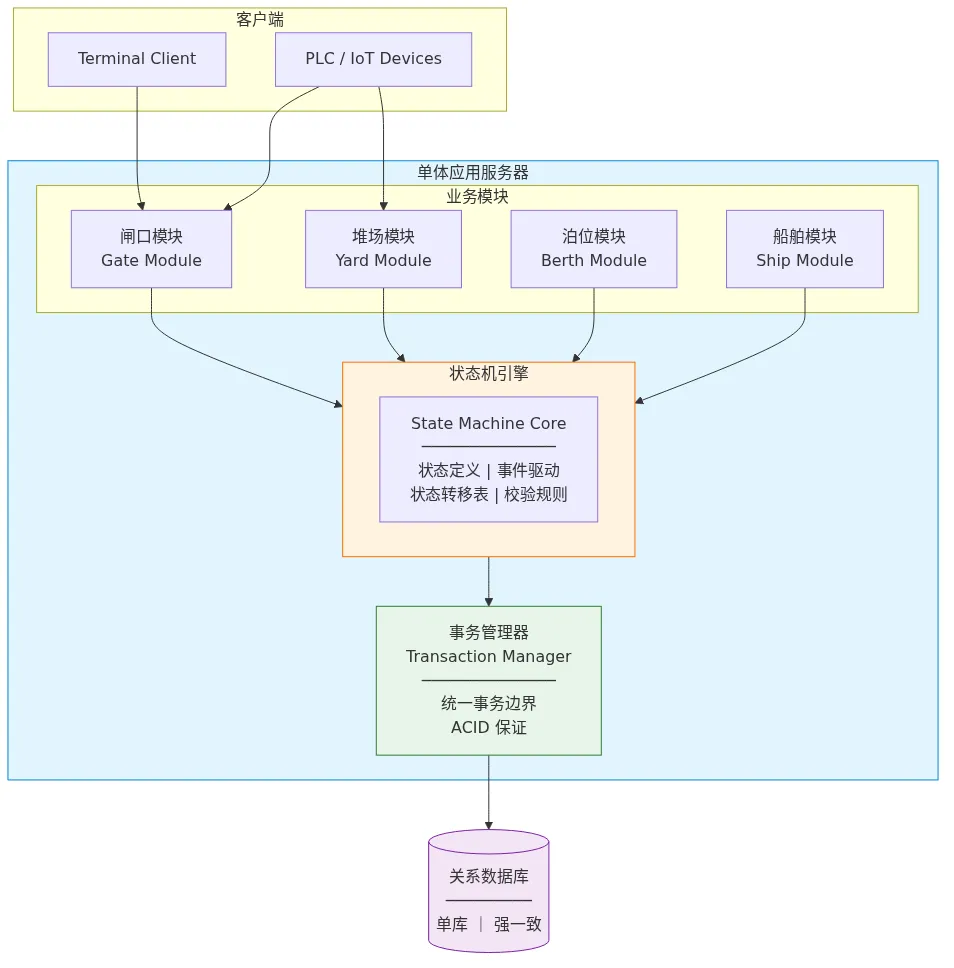
为什么选单体
团队二十人,产品从 0 到 1,需求方自己都说不清楚码头到底要跑哪些流程。
选单体不是不知道微服务好——是问题还没复杂到那个程度。架构复杂度必须和业务复杂度匹配,超前设计比欠债更危险。
状态机引擎的设计
这一版做得最对的一件事,是设计了一个全局统一的状态机引擎。
核心结构是状态、事件、转移表三段式:
状态定义:ENTRY → YARD_IN → YARD_STACKED → YARD_RETRIEVAL → BERTH → SHIP
事件驱动:ContainerArrived, StackAssigned, Retrieved, Loaded
转移表:当前状态 + 事件 → 新状态(附校验规则)
所有模块共用这套状态机。闸口改了状态,堆场直接读到最新值,不需要额外同步。代价是不允许模块自定义状态——全系统只有一套状态定义。
事务边界的设计
事务边界按业务操作划分,不是按 HTTP 请求。一笔完整操作——比如「集装箱进场登记 + 堆场位置分配 + 生成作业指令」——包在一个数据库事务里,要么全成功,要么全回滚。
这么做的问题在三年后暴露了:这个事务太大了,高峰期数据库锁冲突频繁。
这个架构撑了三年
上线了 5 个码头,累计处理了 200 万+ 集装箱。性能瓶颈逐渐显现,但还不到不可接受的程度。
之所以能撑这么久,核心原因是:状态机和事务边界的设计从一开始就是对的。 后来换数据库、换部署方式,状态机引擎没动过一行代码。
三、第二版:服务化拆分 + 分布式状态管理(2012-2018)
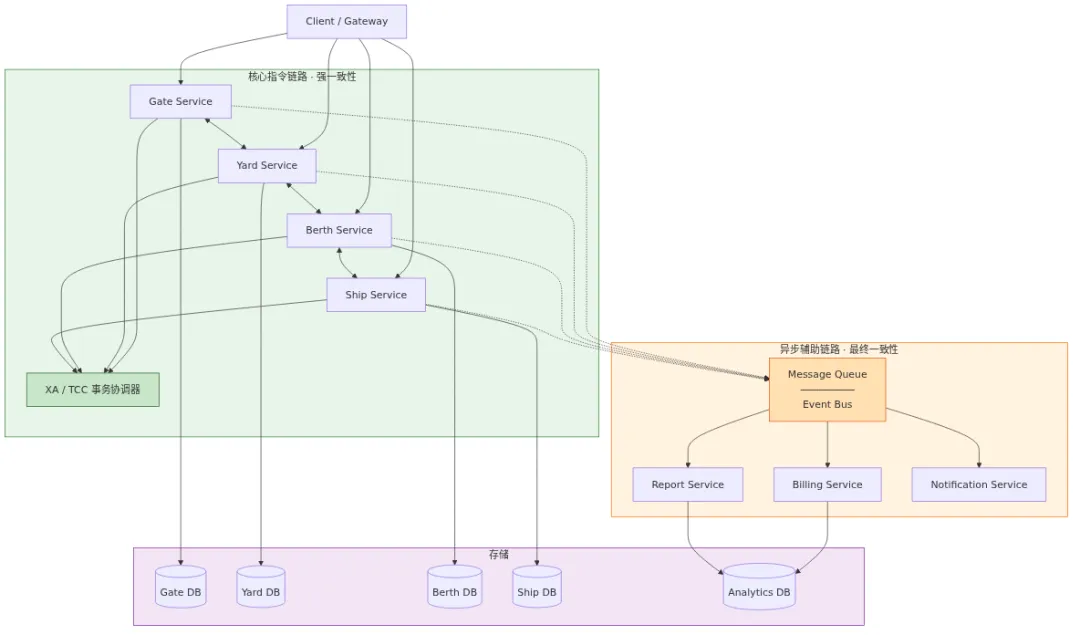
为什么必须拆
触发条件很具体:新的 RFID 实时指令模块需要和原有调度模块高频交互。在单体架构里,这两个模块耦合在一起,改一行要回归六个功能点。
拆分原则是按业务事件流拆,不按 CRUD 拆。 闸口进场、堆场调度、泊位计划、船舶配载——这是一条完整的事件链,每个环节一个服务。
核心指令链路的强一致策略
最关键的决策是:核心指令链路保留同步调用,不走异步消息。
方案对比:
| 方案 | 适用场景 | 在 TOS 中的表现 |
|---|---|---|
| XA 两阶段提交 | 跨库强一致 | 锁表时间长,吞吐下降 40% |
| TCC(Try-Confirm/Cancel) | 业务可补偿 | 适合,但补偿逻辑复杂 |
| Saga | 长流程最终一致 | 不适合物理操作指令 |
| 最终方案:同步 RPC + TCC 补偿 | 核心指令 | 确认阶段走同步,补偿阶段加人工确认 |
选的方案是「核心指令同步调用 + TCC 补偿模式」。同步调用保证指令及时下发,TCC 保证出错能回滚——但每一笔回滚都加了人工确认。
踩过的坑:分布式事务的状态丢失
事故是这样的:下游服务收到了确认消息,更新了设备状态。上游事务超时回滚了——但下游的状态已经变了。两小时后,堆场里三个集装箱的位置对不上,码头停了半小时人工核对。
从那之后定了一条死规矩:任何涉及物理操作的指令,都不能用最终一致性。
CQRS 的落地
查询端压力大的问题通过 CQRS 解决:
指令写入 → 单体式强一致路径(各服务自己的数据库)
查询读取 → 分布式缓存(Redis 集群,TTL 60s)
写入端保证数据准确,读取端保证响应速度。不一致的窗口期控制在 60 秒以内——对查询场景来说完全可以接受。
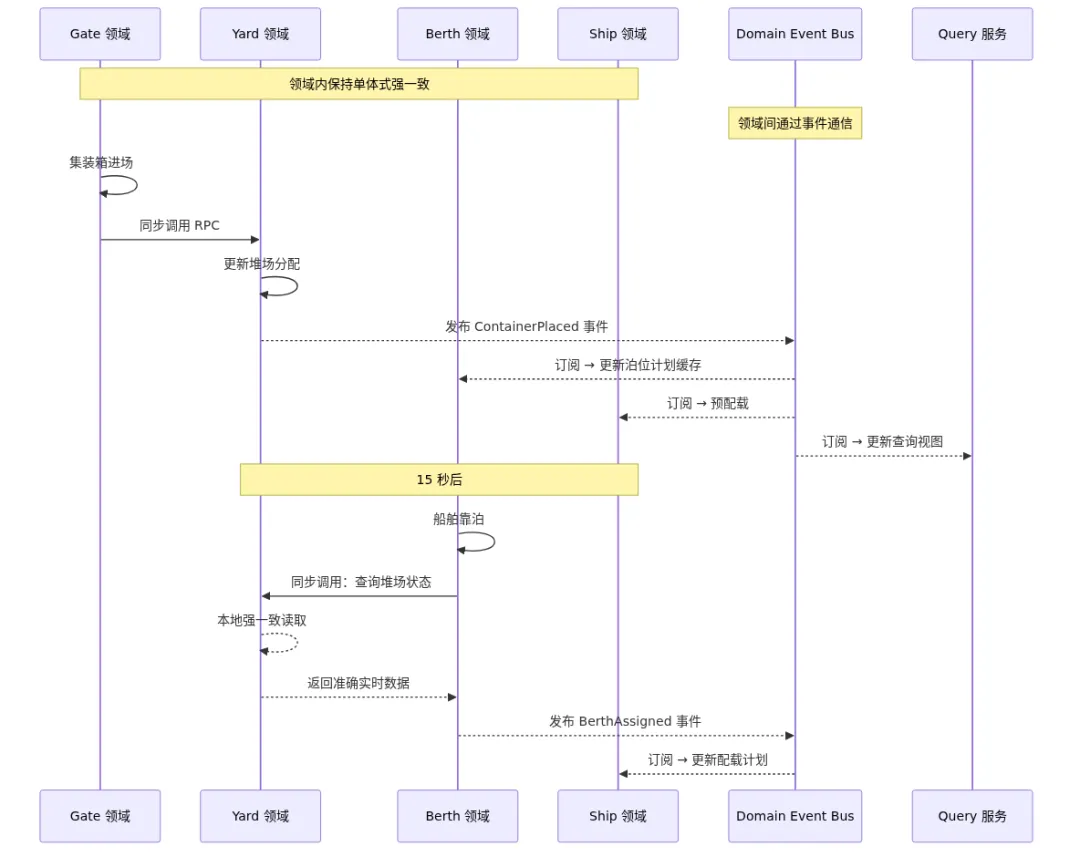
四、第三版:领域内单体 + 领域间事件驱动(2018-至今)
治理成本的临界点
微服务跑了五年后,团队画了一张成本曲线图。关键数据:
-
服务数:14 个 -
每次联调部署:6 个服务 -
每次回归测试:从 2 天变成 5 天 -
边际收益拐点:12 个服务之后为负
独立部署的价值,被运维和联调成本吃掉了。
合并策略
把高频协同的模块合并回领域服务。领域内部保持单体式强一致,领域之间通过事件通信。
具体来说:
-
Gate 领域:闸口登记 + 道口控制 + 车号识别,三个模块合并 -
Yard 领域:堆场分配 + 翻捣 + 冷藏监控,合并 -
Berth 领域:泊位计划 + 岸桥调度,合并 -
Ship 领域:配载 + 稳性计算,合并
领域之间通过 Domain Event 通信:
Gate → Yard:ContainerArrived 事件
Yard → Berth:StackAssigned 事件
Berth → Ship:BerthAllocated 事件
每个事件是异步的,但接收方处理时必须保证幂等——同一个事件处理多次结果不变。
为什么这不是回退
少一个服务就少一个故障点。在这个行业,故障的代价不是用户体验下降,是码头停摆。
五、架构决策框架(可直接套用)
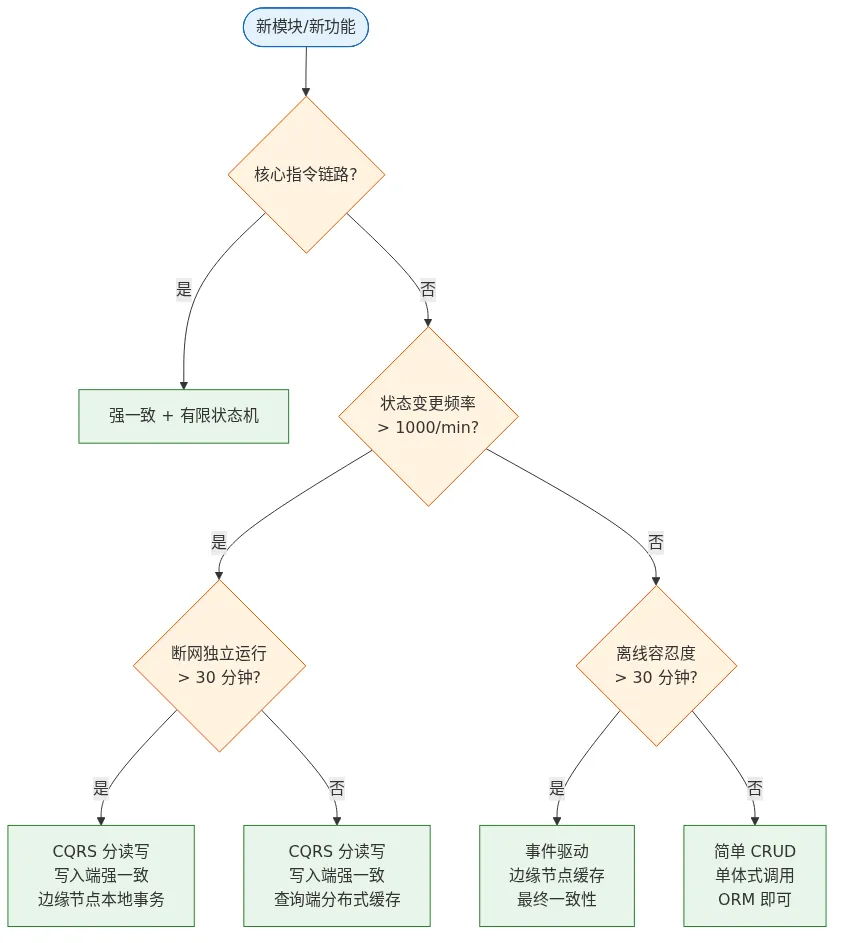
每个新模块/新功能上线前,用三个问题判断:
第一问:是不是核心指令链路?
是 → 强一致 + 有限状态机,不用考虑别的方案。
否 → 进入第二问。
第二问:状态变更频率 > 1000/min?
是 → 考虑 CQRS 分离读写。
否 → 进入第三问。
第三问:断网后需要独立运行 > 30 分钟?
是 → 边缘节点必须有本地事务能力,走最终一致性。
否 → 简单 CRUD 即可,ORM 层就能解决。
三个问题叠完,选什么方案就很清晰了。
几个实在的结论
架构没有银弹。所有告诉你「XXX 完美解决了所有问题」的人,要么没做过生产系统,要么正在踩坑的路上。
不要为了架构先进去拆,也不要为了省事不拆。临界点算笔账就行——维护成本和耦合成本,哪个更高?
对状态保持敬畏。时序错乱一个比特,对讲机就能炸。
真正好的架构不一定要酷——它得能陪着业务跑十来年不出大问题。