 夜雨聆风
夜雨聆风





当AI Agent学会“最小化意外”:一篇9年前的神经科学论文,可能是智能体的终极操作系统
从Friston 的自由能原理到2026 年的Agent 架构革命——感知、记忆、决策、遗忘,原来可以是同一件事
一个让整个行业尴尬的问题
2026 年春天,AI Agent 赛道热得发烫。
Mem0 拿下 4.8 万 Star ,Zep/Graphiti 在时序知识图谱上做出了差异化, Letta 用操作系统的思路分层 管理记忆, Hermes Agent 七周冲到 9.5 万 Star 号称”越用越聪明”。与此同时, ReAct 、CoT 、Tree-of- Thought 等推理框架在决策层卷生卷死, RAG 管道越做越复杂,认知科学启发的遗忘机制开始被引入 Agent 架构。一切看起来一片繁荣。
但如果你退后一步,会发现一个让人不太舒服的事实:
这些系统全是割裂的。
理解用户意图是一个模块,记忆存取是另一个模块,推理规划是第三个模块,遗忘是第四个模块,工具 调用是第五个模块。它们之间靠胶水代码和工程直觉拼接在一起,没有统一的理论框架,没有共同的优 化目标,甚至没有一个一致的数学语言来描述”一个 Agent 到底在做什么”。
这就像 1900 年代的物理学:电磁力、引力、热力学各自为政,每个领域都有自己的公式和直觉,但没 有人知道它们之间的关系。
有没有一个统一理论,能把 Agent 的所有认知活动纳入同一个框架?
答案可能藏在一篇 2017 年发表在 Neural Computation 上的论文里。它的作者是 Karl Friston——当今 被引用次数最多的神经科学家之一。论文标题是 “Active Inference: A Process Theory”(主动推理:一 个过程理论)。这篇论文提出了一个大胆到近乎疯狂的主张:大脑的所有活动——感知、学习、记忆、 决策、行动——都可以用一个单一的数学原理来解释:最小化变分自由能。
9 年后的今天,AI Agent 行业正在用工程手段重新发明这篇论文里的每一个概念。只是大多数人还不知 道。
一个公式统治一切:自由能原理到底在说什么
先别被”变分自由能”这个名字吓到。它的核心思想其实可以用一句话概括:
一切智能行为的本质,都是在最小化”意外”。
什么是”意外”?不是心理学意义上的惊讶,而是信息论意义上的:一个事件发生的概率越低,它的 “意外 度”(surprise)就越高 。一条鱼发现自己在水里——不意外;一条鱼发现自己在树上——极度意外。
Karl Friston 的自由能原理(Free Energy Principle, FEP)认为,所有自组织系统——从单细胞生物到 人类大脑——都在做同一件事: 维持自己处于”不意外”的状态。用更技术的语言说,它们在最小化一个 叫做”变分自由能”的数学量,这个量永远不会低于真实的意外度——你可以把它理解为意外度的一个”保 守估计”。
为什么不直接最小化意外度?因为直接计算意外度需要知道世界的完整概率分布——这对任何有限系统 来说都是不可能的。 变分自由能是一个可以用近似推理(变分贝叶斯)来计算的替代品,它永远大于等 于真实的意外度。最小化它,就是在间接最小化意外。
这个框架的威力在于,它把两件看似不同的事情统一了:
感知 = 更新内部模型来解释已有的观察(减少当前的意外)
行动 = 改变外部世界来匹配内部预期(减少未来的意外)
换句话说,大脑不是一台被动的摄像机,坐在那里等着接收信号然后做出反应。它是一台预测机器—— 不断生成关于”下一刻会发生什么”的预测,然后把预测和实际感知进行比对。如果预测错了(意外度高), 要么更新模型(感知/学习),要么采取行动改变世界(行为)。 两条路,同一个目标。
从理论到神经元: Friston 2017 年论文做了什么
“Active Inference: A Process Theory” 这篇论文的贡献,不是提出自由能原理本身——那是 Friston 更 早期的工作。这篇论文做的是一件更具体、更有野心的事:它证明了,如果你假设神经元的活动就是在 对自由能做梯度下降,那么你可以从这个单一假设出发,推导出大量已知的神经现象。
具体来说,论文用马尔可夫决策过程(MDP)作为生成模型,推导出了一套信念更新方程, 然后展示这 些方程可以复现:
. 重复抑制(repetition suppression):同一个刺激重复出现时,神经响应减弱——因为预测越 来越准,预测误差越来越小
. 失匹配负波(mismatch negativity):意外刺激引发强烈的神经响应——因为预测被违反了
. 位置细胞活动(place-cell activity):海马体中编码空间位置的神经元——对应于生成模型中对 隐藏状态的信念
.Theta-gamma 耦合:不同频率的脑电波之间的嵌套关系——对应于不同时间尺度上的信念更新
. 证据累积(evidence accumulation):决策前逐渐积累证据的过程——对应于对策略的后验概 率的更新
. 多巴胺响应转移 :奖励信号从无条件刺激转移到条件刺激——对应于精度(precision)预测误差 的变化
一个公式,十几种现象。这不是事后拟合——这些现象是从同一组方程中自然涌现出来的。 但论文最关键的贡献不是复现已知现象,而是它提出的统一架构。在这个架构中:
. 感知是在每个策略下估计隐藏状态(状态估计)
. 决策是评估每个策略的期望自由能,然后用 softmax 选择策略 学习是更新生成模型的参数(类似赫布学习)
. 行动是通过贝叶斯模型平均预测下一个状态,然后执行最可能实现该状态的动作
. 精度编码(对应多巴胺)调节策略选择的信心
所有这些——感知、决策、学习、行动、不确定性编码——都是在最小化同一个量 :变分自由能。没有 五个独立的模块,没有五套独立的优化目标。一个原理,一套方程,一个统一的计算架构。
2026 年的 AI Agent 行业,正在重新发明这一切
现在,让我们把目光从神经科学拉回到 AI Agent 行业。
如果你用 Friston 的框架来审视当前的 Agent 系统,你会发现一个有趣的事实:行业正在用工程手段 , 一个模块一个模块地重新发明主动推理早已统一描述的东西。但因为缺乏统一框架,这些模块之间的关 系是混乱的。
我们可以画出一张对应表:
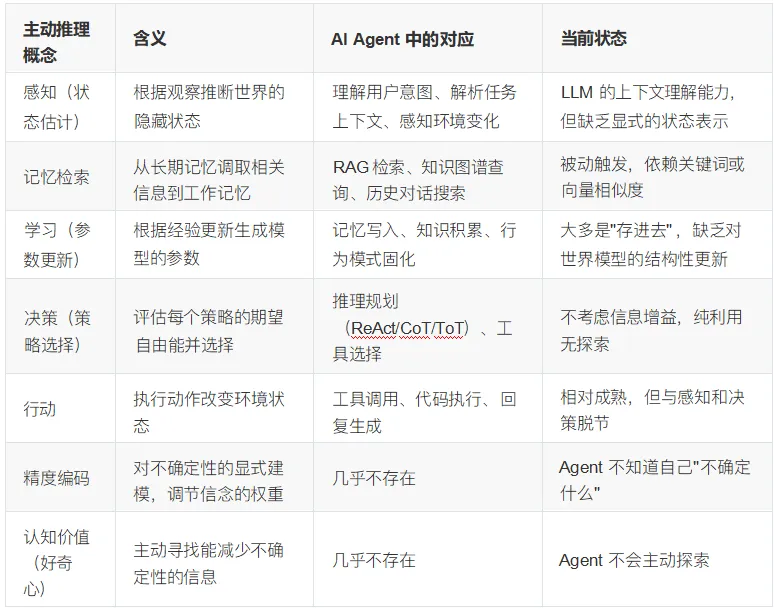
最后两行是最关键的。
在 Friston 的框架中,期望自由能可以分解为两个部分:实用价值(pragmatic value ,即期望效用 —— 做对用户有用的事)和认知价值(epistemic value ,即信息增益——做能减少不确定性的事)。一个健 康的智能体会在两者之间动态平衡:当它对世界的认知充满不确定性时,它会优先探索(最大化认知价 值); 当它已经足够确定时,它会转向利用(最大化实用价值)。
这正是当前 AI Agent 最缺失的能力。
今天的 Agent 几乎全是”利用型”的——你给它一个任务,它直接执行。它不会主动说”等等,我对这个项 目的数据库架构不太确定,让我先查一下再动手” 。它不会在执行任务前主动寻找能减少不确定性的信 息。它没有好奇心。
有趣的是,行业已经在用最原始的方式试图弥补这个缺陷。打开任一个 AI 编程助手的系统提示词,你大 概率会看到类似这样的指令 :”Before answering complex questions, first ask clarifying questions one at a time, until you are confident you understand the request.” 这本质上就是在用自然语言硬编 码”认知价值”——强迫 Agent 在不确定时先探索再行动。
但这种方式是脆弱的:它依赖提示词的措辞,没有数学保证,而且 Agent 无法自己判断”我现在够确定了吗” 。在主动推理中,这个判断是自动的—— 当期望自由能中的认知价值项趋近于零时,Agent 自然从探索切换到利用,不需要任何外部指令。
还有一个更致命的场景 :OOD( Out-of-Distribution)和长尾问题。当前的 LLM Agent 在训练分布内 表现优秀,但一旦遇到训练数据中罕见或从未见过的情况——一个冷门的 API 用法、一个非标准的部署 架构、一个小众语言的边界条件——它们往往会自信满满地给出错误答案, 因为它们根本不知道自己已 经”出界” 了。这正是精度编码缺失的直接后果。
在主动推理框架中,Agent 面对陌生输入时,其生成模 型的预测误差会飙升,精度会自动下降,认知价值项会变大——Agent 会自然地切换到探索模式:承认 不确定性、主动寻找信息、谨慎行动。它不需要一条 “if you’re unsure, say so” 的提示词来告诉它该怎 么做。不确定性本身就是驱动行为的信号。
当然,你可能会说 :好的Agent 已经会搜索了啊——Kiro 会在动手前先搜代码库,Cursor 会在不确定 时查文档。没错,但这些行为本质上还是被外部 harness(编排层)硬编码的:什么时候搜、搜什么、 搜到什么程度算够了,全靠工程师预设的规则或提示词。Agent 本身并不”理解”为什么要搜索——它只 是在执行一条指令。
而在主动推理中,搜索行为是从不确定性中自发涌现的:Agent 感知到自己的世界 模型和当前观察之间存在偏差,认知价值自动升高 ,探索行为自然发生。 区别在于:一个是”被告知要探 索” ,另一个是”因为不确定所以探索” 。前者脆弱且不可泛化,后者是一个通用的认知机制。
更深层的问题是精度编码的缺失。在主动推理中,精度(precision)是一个核心概念——它编码了Agent 对自己每一个信念的确信程度。高精度意味着”我很确定” ,低精度意味着”我不太确定” 。这个信 号直接影响决策:低精度的信念会被降权,高精度的信念会主导行为。 Friston 的论文将精度编码对应 到多巴胺系统——多巴胺不是”奖励信号” ,而是”确信度信号”。
当前的 LLM Agent 完全没有这个机制。它们对自己的每一个输出都同等自信——无论是在回答一个它训 练数据中见过一万次的问题,还是在猜测一个它从未见过的领域知识。这就是为什么 Agent 会自信满满 地给出错误答案(幻觉),也是为什么它们无法在”我该直接行动”和”我该先搞清楚状况”之间做出合理 的判断。
Friston 在 2026 年 4 月接受diginomica 采访时一针见血地指出了这个问题。作为 VERSES AI 的首席科 学家,他认为主动推理框架能在 LLM 结构性无法做到的地方胜出——因为它能编码不确定性并产生好奇 心 。 LLM 本质上是一个巨大的条件概率表,它不知道自己不知道什么。 而主动推理的 Agent 天然具备这 种元认知能力。
从论文到产品:谁在真正构建这个未来
自由能原理不再只是理论物理学家的玩具。2024-2026 年,一系列研究和产品开始把它变成可运行的代 码。
VERSES AI 和 Genius 平台
Friston 本人担任首席科学家的 VERSES AI ,正在把主动推理变成企业级产品。他们的 Genius 平台是一 个”智能体企业智能平台” ,专门针对数据波动大、不确定性高 、环境复杂模糊的场景。
2025年8月 ,VERSES 获得了一项关键专利——用自然语言定义主动推理Agent 的领域模型。2025 年下半年,他们的 研究团队发表了主动推理在机器人移动操作中的突破性成果,展示了Agent 在长时间任务中的实时适应 和从意外变化中恢复的能力。
与传统强化学习不同,VERSES 的 Agent 不需要海量预训练数据。它们通过构建世界的生成模型来推 理,而不是通过记忆大量的输入-输出映射来反应。用 VERSES 自己的话说 :”与其学习策略,不如推理 原因。”
“Active Inference for Self-Organizing Multi-LLM Systems”(2024)
这篇 2024 年 12 月的 arxiv 论文,可能是把主动推理和 LLM 结合得最直接的一次尝试。研究者在 LLM Agent 之上加了一个主动推理的”认知层” ,用它来动态调整提供给 LLM 的提示词和搜索策略。
具体来说,这个认知层用三个状态因子(提示词状态、搜索状态、信息状态)和七个观察模态(质量指 标)来建模环境。通过最小化自由能, Agent 能够系统性地探索不同的提示词组合,评估它们的效果, 并在探索和利用之间自动切换。实验结果显示,Agent 的行为模式从初期的信息收集逐渐过渡到有针对 性的提示词测试——这正是主动推理预测的”先探索后利用 “的行为模式。
这篇论文的意义在于:它证明了主动推理不需要替代 LLM ,而是可以作为 LLM 之上的一个元认知层 ——让 LLM 保持其强大的语言能力,同时获得主动推理的自适应和探索能力。
DR-FREE:发表在 Nature 上的鲁棒决策框架(2025)
2025 年,一篇发表在 Nature Communications 上的论文提出了 DR-FREE(Distributionally Robust Free Energy)模型。它把自由能原理和分布鲁棒优化结合起来,让 Agent 在面对模型不确定性时依然 能做出可靠的决策。
在基准实验中,DR-FREE 让 Agent 在其他最先进模型失败的情况下依然能完成任务。论文的关键洞察是:传统的自由能最小化假设 Agent 的世界模型是准确的,但现实中模型总有偏差。 DR-FREE 通过在最 坏情况分布上优化,把鲁棒性直接编码进了决策机制。
这对 AI Agent 的意义是深远的:它意味着基于自由能原理的 Agent 不仅能在理想条件下工作, 还能在 模型不完美、环境有噪声的真实世界中保持可靠。
Orchestrator:多 Agent 长时间任务协调(2025)
另一个值得关注的工作是 Orchestrator 框架,它把主动推理应用于多 Agent 系统的长时间任务协调。 在部分可观察、需要多个 Agent 协作的复杂任务中,Orchestrator 使用注意力机制启发的自涌现协调 和反思性基准测试来优化全局任务表现。
这个框架的核心思想是:每个 Agent 不仅要最小化自己的自由能, 还要通过共享信念来协调集体行为 ——这和 Friston 论文中关于”马尔可夫毯”(Markov blanket)的概念直接对应。
重新理解记忆、遗忘和学习
如果你接受了自由能原理的框架, 那么 AI Agent 的记忆、遗忘和学习就不再是三个独立的工程问题,而 是同一个数学过程的不同面向。
记忆不是存储,是信念更新。
在 Friston 的框架中,”记忆”对应的是生成模型参数的更新。论文中的学习方程显示,参数更新本质上 是一种赫布学习——共同出现的状态之间的关联被增强,不常出现的关联被削弱。这不是”把信息存进数 据库” ,而是”根据经验调整对世界的信念”。
当前的 Agent 记忆系统——无论是 Mem0 的向量+图谱混合存储、Zep/Graphiti 的时序知识图谱,还是 简单的 Markdown 文件——本质上都是在做”存储和检索” 。它们把记忆当作一个数据库问题。但Friston 的框架暗示,真正的记忆应该是生成模型本身的一部分——不是”我存了什么” ,而是”我的世界 模型因为这些经验变成了什么样”。
这个区别不是语义上的吹毛求疵。它有实际的工程含义:如果记忆是生成模型的参数,那么”记住”一件 事就意味着这件事改变了Agent 对世界的预测方式——它会影响 Agent 未来的感知、决策和行动。 而如 果记忆只是数据库里的一条记录,它只有在被检索到的时候才有用,而且和Agent 的其他认知过程是脱 节的。
遗忘不是 bug,是精度加权的必然结果。
在主动推理中,每个信念都有一个”精度”(precision)——对这个信念的确信程度。精度低的信念对行 为的影响小 ,精度高的信念影响大。 随着时间推移和新证据的积累, 旧信念的精度自然衰减——这就是 遗忘。
2026 年初,越来越多的研究者开始意识到这一点。一篇题为 “AI Agents Need Memory Control Over More Context” 的论文指出,当前基于转录回放或检索的记忆机制会导致无限制的上下文增长 ,容易受 到噪声召回和记忆污染的影响,最终导致 Agent 行为不稳定和漂移。
这正是缺乏精度编码的后果——系 统无法区分”高确信度的核心记忆”和”低确信度的噪声信息” ,只能一视同仁地保留或丢弃。
但这些工作和主动推理之间有一个关键区别:它们的衰减和组织规则是预设的,而主动推理中的精度是 从数据中推断出来的。换句话说,一个真正基于自由能原理的遗忘系统不需要人工设计衰减曲线——它 会根据信息的实际有用性自动调整遗忘速率。
学习不是微调,是减少意外。
当前 AI Agent 的”学习”通常意味着两件事:要么是知识库的更新(加入新文档),要么是提示词的优化 (根据反馈调整系统提示)。这两种方式都是局部的、被动的。
在主动推理中,学习是一个更深层的过程:Agent 通过与环境的交互,不断更新其生成模型的所有参数 ——不仅是”知道了什么新事实” ,还包括”世界的因果结构是什么样的” 、”不同状态之间的转移概率是多 少” 、”我的行动会产生什么后果” 。这种学习是全局的、主动的, 而且和感知、决策共享同一个优化目标。
Friston 论文中最优雅的结果之一,是展示了习惯如何从目标导向行为中自然涌现。在模拟实验中,Agent 最初通过主动探索来学习环境(认知行为), 随着对环境越来越熟悉,它逐渐形成了固定的行为 模式(习惯)——而这个过程不需要任何额外的机制,它是信念更新的自然结果。
这对 AI Agent 的启示是:与其手动设计”什么时候该探索、什么时候该利用 “的规则,不如让 Agent 在一 个统一的框架下自动完成这个转换。
一个美丽的理论,和一个残酷的现实
写到这里,你可能觉得自由能原理是AI Agent 的万能解药。但诚实地说,它面临着严峻的挑战。
可扩展性问题。 Friston 论文中的模拟实验用的是一个只有 8 个隐藏状态、4 个动作的 T 型迷宫。真实 世界的 AI Agent 面对的状态空间是天文数字级别的。虽然 VERSES AI 和其他团队在工程上取得了进展,但把主动推理扩展到 LLM 级别的复杂度,仍然是一个未解决的问题。2024 年的那篇 Multi-LLM 论 文是一个有希望的方向,但它的实验规模仍然有限。
计算成本。期望自由能的计算涉及对未来状态的枚举和评估。在离散状态空间中这还可以接受,但在连 续的、高维的状态空间中,计算成本会爆炸式增长 。正如一篇 2025 年的 arxiv 论文所指出的, “期望自 由能最小化的计算成本限制了其可扩展性”。
与 LLM 的整合。 LLM 本质上是一个自回归的 token 预测器,它的内部表示和主动推理的生成模型之间 没有直接的对应关系。把主动推理作为 LLM 之上的元认知层是一个务实的方案,但它也意味着两个系统 之间存在”阻抗不匹配”——LLM 的黑箱特性使得主动推理层很难准确建模 LLM 的行为。
理论争议。 自由能原理本身在学术界并非没有争议。一些批评者认为它过于宽泛——如果一切都可以用 最小化自由能来解释,那它是否真的解释了什么?这个批评有一定道理:一个能解释一切的理论,可能 什么都没解释。但 Friston 2017 年论文的价值恰恰在于它不只是一个抽象原理,而是一个具体的过程理 论——它给出了可以被验证(或证伪)的具体预测。
结语:下一个突破性 Agent,可能不是拥有最好的模型,而是拥有最好的世界模型
2026 年的 AI Agent 行业有一个讽刺的现象:工程师们花了两年时间,用工程直觉一个模块一个模块地 重建了神经科学家十年前就形式化了的认知架构。记忆系统对应参数学习,推理链对应策略评估,遗忘 机制对应精度衰减,RAG 对应从长期记忆到工作记忆的检索。只是没有人把它们放在同一个框架里, 也 没有人给它们一个共同的优化目标。
Friston 的自由能原理提供了这个框架。它不是一个需要从零开始的全新架构,而是一个可以统一现有 组件的理论透镜。当你用这个透镜来审视当前的 Agent 系统,你会看到缺失的拼图:认知价值(好奇心 驱动的探索)、精度编码(对不确定性的显式建模)、以及统一的优化目标(而不是五个独立模块各自 为政)。
下一个真正的突破性 Agent,可能不是拥有最大的上下文窗口、最快的推理速度、或者最多的工具调用 能力。它可能是第一个拥有真正的世界模型的 Agent——一个能预测、能探索、能遗忘、能学习的生成 模型,而所有这些能力都从同一个原理中涌现。
Karl Friston 在 2017 年写下那篇论文时,可能没有想到它会和 AI Agent 产生交集。但 9年后,当整个 行业都在问”Agent 的下一步是什么”的时候,答案可能一直就在那里——藏在一个关于大脑如何最小化 意外的优雅数学框架里。
参考来源
1.Karl Friston et al., “Active Inference: A Process Theory”, Neural Computation, 2017 年 1 ⽉ (pubmed.ncbi.nlm.nih.gov/27870614)
2.Karl Friston et al., “Active inference and learning”, Neuroscience & Biobehavioral Reviews, 2016 (pmc.ncbi.nlm.nih.gov/articles/PMC5167251)
3.”Active Inference for Self-Organizing Multi-LLM Systems: A Bayesian Thermodynamic
Approach to Adaptation”, arxiv, 2024 年 12 ⽉ (arxiv.org/html/2412.10425v3)
4.”Distributionally robust free energy principle for decision-making”, Nature Communications, 2025 (nature.com/articles/s41467-025-67348-6)
5.”Active Inference for Multi-Agent Systems in Long-Horizon Tasks” (Orchestrator), arxiv, 2025 (arxiv.org/html/2509.05651)
6.”AI Agents Need Memory Control Over More Context”, arxiv, 2025 (arxiv.org/html/2601.11653)
7. diginomica, “Why Karl Friston is betting on cultivating curiosity for sustainable AGI”, 2025 年 4 ⽉ (diginomica.com)
8. VERSES AI, “Active Inference for Robot Planning & Control”, 2025 (verses.ai)
9.VERSES AI, “VERSES Receives Patent for Specifying Domain Models with Active Inference Agents”, 2025 年 8 ⽉ (verses.ai)
10.”Active Inference and the Free Energy Principle: How Agents Minimize Surprise Instead of Maximizing Reward”, 2026 年 2 ⽉ (notes.muthu.co)
11.”A Framework for Inherently Safer AGI through Language-Mediated Active Inference”, arxiv, 2025 (arxiv.org/html/2508.05766v1)

推荐阅读



关注红熊AI实验室,了解AI技术前沿~