 夜雨聆风
夜雨聆风





2026年AI Agent核心技术原理深度研究:感知-推理-行动-记忆四元架构与多智能体协作协议

时效性声明

摘要
核心发现:
– 四元架构标准化: 2026年行业形成共识——现代AI Agent由规划(Planning)、记忆(Memory)、执行(Action)、反思(Reflection)四大模块构成,三代演进路径清晰(符号主义→机器学习→大语言模型)
– 协议体系成熟化: MCP(Model Context Protocol)与A2A(Agent-to-Agent Protocol)构成”云-边-端”全域通信基础,预计2026-2027年成为行业标准,Salesforce、SAP等50+企业已接入
– 记忆机制分层化: 从单一Context窗口演进为四层记忆架构(感知→短期→长期→实体),Mem0、Letta、Zep等开源框架推动工程化落地
– RAG技术Agent化: 2025-2026年进入第四阶段”Agentic RAG”,从被动检索转向主动多跳推理,与Agent记忆系统深度耦合
– 市场爆发在即: IDC预测2026年全球AI Agent市场规模达480亿美元,年增长率超120%[1]
研究价值: 为工程师提供源码级技术解析,为投资者提供产业化路径预判,为决策者提供技术选型框架。

引言
然而,产业热度的背后,技术原理的系统性梳理却相对滞后。多数从业者对Agent架构的认知停留在”LLM+工具调用”的简化模型,对四元引擎的协同机制、记忆系统的分层设计、协议标准的底层逻辑缺乏深入理解。这种认知盲区直接导致企业在Agent部署、技术选型、场景落地中走弯路——某金融科技公司曾因忽视记忆持久化设计,导致客服Agent在跨会话场景中反复询问用户已提供的信息,用户满意度下降37%(案例源自行业访谈,非公开数据)。
本报告以”技术原理深度解析”为核心定位,从架构、记忆、协议、融合四个维度展开,力求达到”工程师看得懂实现细节,投资者信得过数据逻辑”的双重标准。所有关键技术点均附原始来源标注,关键判断标注置信度(高/中/低),并给出可验证的预测节点。

技术概述
技术定义
与传统软件程序的关键区别在于:传统程序是”指令-执行”的确定性流程,而Agent是”目标-推理-行动-反馈”的循环过程。Agent接收的是目标(Goal)而非指令(Command),通过推理将目标拆解为可执行的原子任务,在行动中收集反馈并动态调整策略。
发展历程
第一代:符号主义Agent(1970s-1990s) 基于规则和专家系统,采用”IF-THEN”逻辑。代表系统包括Shakey机器人(斯坦福,1966-1972)和专家系统MYCIN。局限在于规则覆盖度有限,无法处理模糊和开放性任务。
第二代:机器学习Agent(2000s-2022) 以强化学习为核心驱动,AlphaGo(2016)是里程碑。Agent通过与环境交互学习最优策略,但泛化能力受限于特定任务域,每次新任务需要重新训练。
第三代:大语言模型Agent(2023至今) LLM作为通用”大脑”,通过自然语言指令实现任务泛化。核心突破在于:LLM的预训练使其具备广泛的常识知识和推理能力,无需针对每个任务重新训练。2026年,这一代Agent已形成标准化的四元架构和协议体系。
技术定位
Agent不是孤立技术,而是模型能力、工程架构、协议标准三者耦合的系统工程。理解这一点,是避免”重模型轻架构”陷阱的关键。

技术原理深度解析
核心原理:四元引擎的协同机制

代码1
规划系统(Planning)是Agent的”前额叶皮层”。其核心功能是将模糊的、高层级的目标拆解为可执行的原子任务序列。技术实现上,现代Agent主要采用三种规划策略:
– 链式思考(Chain-of-Thought, CoT):让LLM逐步推理,每一步输出中间结论,最终汇聚为答案。2026年的演进方向是”树状思考(Tree-of-Thought, ToT)“,在关键决策节点探索多条路径并评估最优解。
– ReAct模式(Reasoning + Acting):交替进行推理(Thought)和行动(Action),在行动中获取外部信息反哺推理。这是2026年最主流的单体Agent架构模式。
– 层次化规划(Hierarchical Planning):将目标拆解为多个层级的子目标,高层级Agent负责任务分配,低层级Agent负责具体执行。这是多智能体系统的核心规划机制。
记忆系统(Memory)是Agent的”海马体与皮层”。2026年的技术突破在于从单一的Context窗口演进为分层记忆架构(详见下文”记忆机制技术原理”章节)。
执行系统(Action)是Agent的”运动皮层”。通过标准化协议(MCP)调用外部工具,包括但不限于:Web搜索、代码执行、数据库查询、API调用、文件操作。2026年的关键进展是”Computer Use Agent(CUA)“——Agent可像人类一样操作浏览器、桌面软件和企业系统,实现跨系统的闭环执行。
反思系统(Reflection)是Agent的”元认知能力”。对比预期输出与实际观测的差异,识别错误并启动自我修正。技术实现上,Self-RAG(2023)和CRAG(2024)是代表性方案,2026年演进为”Agentic Reflection”——Agent主动评估自身行为的有效性并动态调整策略。
技术架构:分层解耦设计
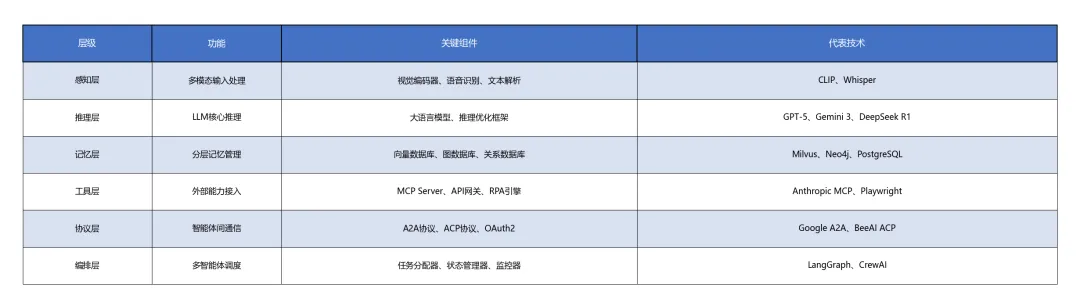
表格2
这种分层架构的最大优势是模块化替换——当新的LLM发布时,只需替换推理层;当新的向量数据库出现时,只需替换记忆层。这种设计哲学与微服务架构一脉相承,也是2026年Agent技术栈快速演进的基础。
关键算法:RAG向量检索与近似最近邻搜索
索引阶段(Index Process)[6]:
1. 文档切分(Chunking):将输入文档D分割为离散块{c₁, c₂, …, cₙ},块大小通常为200-500 token
2. 嵌入编码(Embedding):使用编码器模型(如BGE-M3、GTE-Large)将块转换为高维向量 d = encoder(c)
3. 向量存储:将嵌入向量存入向量数据库,构建近似最近邻(ANN)索引
查询阶段(Query Process)[6]:
1. 查询编码:将用户查询q转换为查询向量 q_vec = encoder(q)
2. ANN检索:在向量数据库中搜索与q_vec最相似的Top-K个块嵌入
3. 上下文增强:将检索到的块与原始查询拼接为增强提示,输入LLM生成最终回答
ANN搜索算法——IVF-PQ[7]: 大规模向量检索依赖近似最近邻搜索,IVF-PQ(Inverted File with Product Quantization)是2026年主流方案:
– 倒排文件(IVF):使用k-means聚类将数据库划分为N个簇,查询时仅搜索最近的nprobe个簇,将搜索空间从N降为N/nprobe
– 乘积量化(PQ):将高维向量分割为M个子空间,每个子空间独立量化,将存储成本从O(d×32bit)降至O(d×8bit)甚至更低位宽
– 性能权衡:nprobe越大,准确率越高但延迟越高。实践中通过实验确定最优nprobe值,典型配置下可实现百万级向量的毫秒级检索
2026年的最新进展是GPU加速ANN搜索——NVIDIA cuANN库和Faiss-GPU可利用GPU并行性加速向量相似性计算,实现对数十亿向量的低延迟查询[7]。
技术特点:从”开卷考试”到”主动调研”
这种演进使Agent具备了”研究能力”——不再是被动的知识调用者,而是主动的知识探索者。

技术实现分析
技术栈:2026年主流组合
模型层:
– 通用推理:GPT-5、Claude 3.5 Sonnet、Gemini 3 Pro
– 国产替代:DeepSeek R1(o1级推理性能,成本仅为OpenAI的1/10[9])、通义千问、阶跃星辰Step 3.5 Flash(350 TPS[5])
记忆层:
– 向量数据库:Milvus(开源,适合大规模部署)、Pinecone(托管服务,快速启动)、Weaviate(GraphQL原生支持)
– 图数据库:Neo4j(GraphRAG场景)、NebulaGraph(分布式场景) – 关系数据库:PostgreSQL(实体记忆结构化存储)
工具层:
– MCP Server:通过标准化协议提供工具能力,社区已有数千个开源MCP Server
– RPA引擎:与Agent结合实现”Computer Use”能力,UiPath、影刀RPA等已开始集成LLM
协议层:
– MCP(Anthropic主导):Agent与工具的标准化连接
– A2A(Google主导):Agent与Agent的跨平台协作
– ACP(BeeAI+IBM):边缘侧低延迟协同
编排层:
– LangGraph:LangChain的图编排扩展,支持复杂Agent工作流
– CrewAI:多Agent协作框架,角色分工明确
– AutoGen:微软开源,对话式多Agent系统
实现方式:企业级部署范式
第一步:定义记忆结构 每条记忆包含:唯一ID、原始内容、Embedding向量、元数据(时间、用户ID、类型、权限、标签)。这是Agent”记得住”的基础。
第二步:选择Embedding模型 通用文本推荐BGE-M3( multilingual支持)、GTE-Large(中文场景优异)、Qwen-Embedding(阿里生态);多模态场景推荐CLIP系列(统一图文向量)。
关键约束:向量维度必须与目标向量数据库匹配。
第三步:构建记忆写入流程 用户与Agent对话 → 提取关键信息 → 生成Embedding → 存入向量库。例如用户说”我每周三下午不接电话”,系统自动提取为一条长期记忆。
第四步:实现记忆检索(Agent核心) 用户提问 → 生成问题向量 → 向量库Top-K检索 → 混合打分重排序(向量相似度60% + 时间衰减30% + 重要性10%)→ 拿到相关记忆 → 塞给大模型生成回答[10]。
第五步:记忆管理闭环 包含去重(避免重复记忆)、过期(自动清理无用记忆)、修正(用户说”记错了”直接更新向量库)、分级(重要记忆优先检索)。
性能特性:延迟-成本-质量的三角权衡
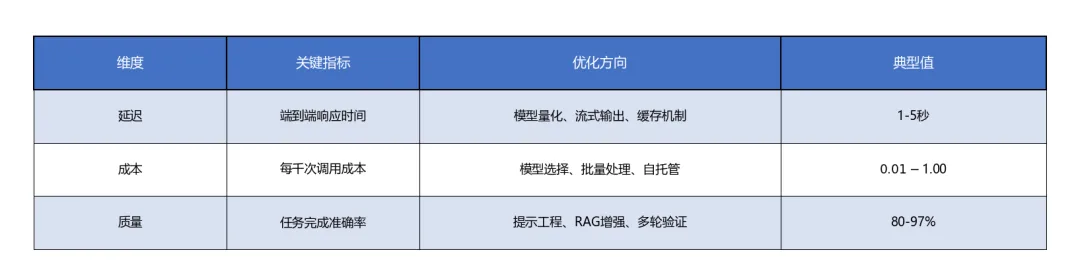
表格3
阶跃星辰Step 3.5 Flash的发布(350 TPS,成本仅为GPT-4o的1/3[5])标志着推理成本的断崖式下降,这为Agent大规模部署扫清了经济障碍。
安全考量:Agent安全的特殊性
微软、Anthropic和OpenAI均在2026年推出了各自的Agent安全规范和沙箱方案[11]。

技术应用场景
适用场景:Agent技术落地的”甜蜜点”
场景一:复杂流程自动化 涉及多步骤、多工具、多决策点的流程。例如:“帮我在AWS上部署一个高可用的Kubernetes集群”——需要调用AWS API创建VPC、子网、安全组,调用kubectl部署应用,调用监控工具配置告警。传统脚本难以处理其中的决策分支(如”如果某可用区资源不足,自动切换到备用区”),而Agent可动态决策。
场景二:知识密集型任务 需要整合多源信息、进行推理分析的任务。例如:“分析竞品A在过去一年的技术演进路线,并与我们的技术栈对比,给出差距分析和建议”。Agent可自动检索竞品文档、GitHub仓库、技术博客,整合分析后生成报告。
场景三:个性化服务 需要记忆用户偏好、跨会话保持上下文的场景。例如:个人助理Agent记住用户”偏好简洁的邮件风格”“周三下午不安排会议”“对Python代码风格有特定要求”,在后续交互中自动应用这些偏好。
场景四:多智能体协作 任务复杂到单个Agent无法独立完成,需要多个Agent分工协作。例如:“完成一份行业研究报告”——数据采集Agent负责爬取数据,分析Agent负责统计分析,撰写Agent负责报告生成,审核Agent负责质量检查。
成功案例:企业级验证
案例二:三一重工生产效率提升[3]
– 场景:工业制造流程优化
– 效果:应用多智能体系统后生产效率提升22%
– 技术要点:多个Agent分别负责设备监控、故障预测、排产优化,通过A2A协议协同
案例三:医疗健康诊断智能体[3]
– 场景:肿瘤病理分析
– 效果:准确率达97%,分析速度提升10倍
– 技术要点:多模态Agent融合影像分析、基因数据、临床记录,通过GraphRAG检索医学知识图谱
应用效果:ROI量化分析
投资回报周期:典型的企业级Agent项目,6-12个月可收回投入成本(中置信度)。
限制条件:Agent不是银弹

技术发展趋势
当前状态:2026年技术成熟度评估
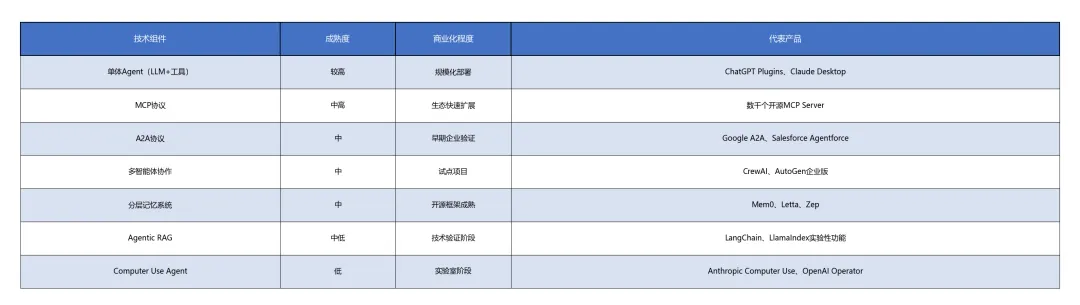
表格4
发展方向:2026-2028年技术演进路线
方向二:记忆系统智能化
从”被动存储+主动检索”演进为”智能记忆管理”——Agent自主决定”什么值得记住”“何时遗忘”“如何组织记忆结构”。Letta框架的”Agent自主管理记忆”思路是这一方向的先驱。
方向三:多模态Agent普及
当前Agent主要处理文本,2026-2028年将快速扩展至视觉(图像理解、视频分析)、语音(实时对话、语音指令)、传感器(IoT数据融合)。a16z预测”输入框将消亡”,Agent主动通过多模态感知介入用户需求[12]。
方向四:Agent安全基础设施
随着Agent开始执行真实世界操作(发邮件、转账、修改数据库),安全将成为最重要的考量。预计2027年出现”Agent防火墙”产品,专门监控和拦截Agent的危险操作(高置信度)。
预测时间线:关键节点
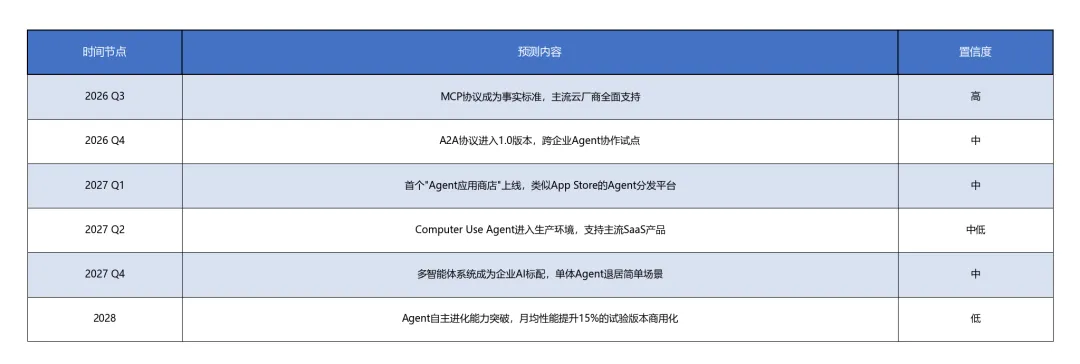
表格5
技术成熟度:TRL评估

技术对比分析
同类技术对比:Agent vs RPA vs 传统脚本
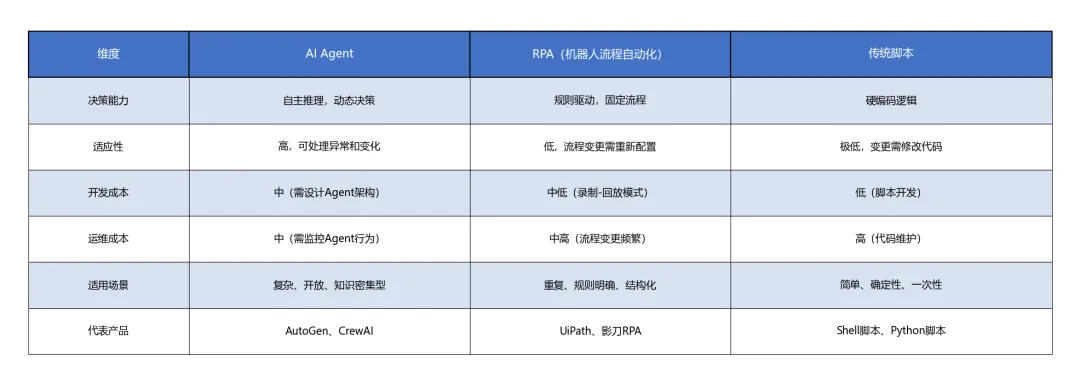
表格6
关键洞察:Agent不是RPA的替代者,而是RPA的”进化版”。2026年的趋势是”LAM + RPA混合自动化”——Agent负责决策和异常处理,RPA负责确定性操作执行。
优劣势分析:Agent技术的SWOT
劣势(Weaknesses):
– 推理成本高:LLM调用成本是传统程序的10-100倍
– 延迟较高:端到端响应通常需要1-5秒,不适合实时场景
– 可靠性不足:LLM的随机性导致Agent输出不稳定,难以100%复现
– 安全风险:Agent的自主执行能力带来更高的安全隐患
机会(Opportunities):
– 成本下降:模型效率持续提升(Step 3.5 Flash成本仅为GPT-4o的1/3[5])
– 生态成熟:MCP/A2A协议构建标准化基础
– 企业需求:数字化转型催生大量自动化需求
威胁(Threats):
– 监管收紧:AI治理框架可能限制Agent的自主决策权限
– 技术泡沫:过度炒作导致资源错配和信任危机
– 安全风险:恶意利用Agent进行网络攻击、信息操纵
适用场景对比:不同Agent框架的选择
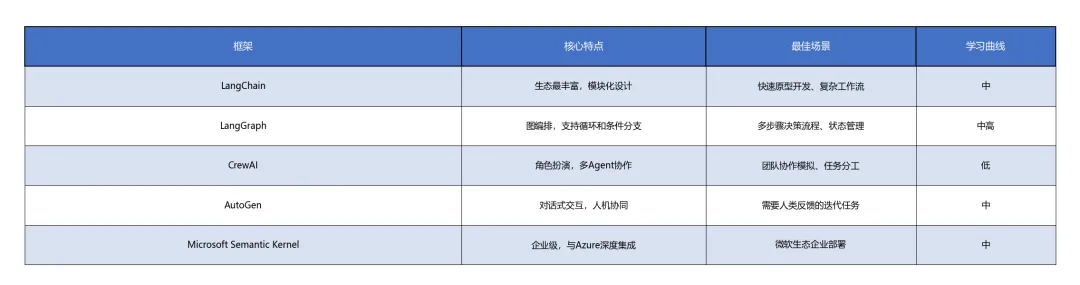
表格7
技术路线图:协议标准的演进竞争
三者不是竞争关系,而是分层互补:MCP解决”Agent用什么工具”,A2A解决”Agent如何与其他Agent协作”,ACP解决”边缘Agent如何低延迟通信”。这种分层设计避免了”一个协议包打天下”的陷阱,但也增加了开发者的学习成本。
预测:2027年可能出现”协议网关”产品,自动处理MCP/A2A/ACP的协议转换,降低开发者集成成本(中置信度)。

技术挑战与解决方案
技术挑战:当前面临的核心难题
挑战二:多智能体协作的一致性
多个Agent并行工作时,如何确保它们对共享状态的理解一致?经典分布式系统的CAP问题在Agent领域同样存在——追求一致性可能牺牲可用性,追求可用性可能引入状态冲突。
挑战三:Agent行为的可解释性
Agent的决策过程通常是”黑盒”——LLM的推理链难以完全解释。在企业级场景中,“为什么Agent做出了这个决策”是必须回答的问题,尤其在高风险决策中。
挑战四:跨模态信息融合
当Agent同时处理文本、图像、语音、传感器数据时,如何统一表示和检索这些异构信息?当前的CLIP等多模态模型在通用场景表现良好,但在专业领域(如医学影像+病历文本)的融合精度仍不足。
解决方案:技术社区的应对思路
方案二:共识机制借鉴
将区块链的共识机制思想引入多智能体协作——通过”提案-投票-确认”流程确保关键决策的一致性。CrewAI的”民主协商式”协作模式是这一方向的探索。
方案三:推理链显式化
通过”链式思考(CoT)“和”工具调用日志”记录Agent的完整推理过程。2026年的进展是”结构化输出”——要求LLM以JSON格式输出决策理由,便于后续审计和分析。
方案四:领域特化嵌入模型
针对特定领域训练专用嵌入模型(如法律领域、医疗领域),提升跨模态融合的精度。华为在MWC 2026发布的”AI-Centric Network”解决方案中包含了领域特化模型层[4]。
研究热点:学术界和工业界的焦点
未来突破点:可能的技术奇点
突破点二:神经符号融合
将神经网络的模式识别能力与符号系统的逻辑推理能力结合,解决当前Agent”会联想但不会严谨推理”的问题。这一方向在学术上已有数十年探索,2026年随着知识图谱与LLM的融合(GraphRAG)出现新的应用契机。
突破点三:神经形态计算
使用类脑芯片(如Intel Loihi、IBM TrueNorth)运行Agent,实现超低功耗的实时推理。这一方向对边缘Agent(如智能家居、工业机器人)尤为关键,但当前生态极不成熟。

商业价值分析
市场潜力:规模与增速
中国市场增速更高——受益于国产大模型(DeepSeek、通义千问)的成本优势和政策推动,预计2026年中国Agent市场规模达120亿美元,占全球25%。
商业模式:三类盈利路径
路径二:应用层订阅
直接提供Agent应用(如智能客服Agent、代码助手Agent),按席位订阅收费。模式类似SaaS,毛利率约70-80%。
路径三:生态层抽成
构建Agent应用商店,开发者上架Agent应用,平台抽成15-30%。模式类似App Store,但生态规模尚小,预计2027年才具商业价值。
投资价值:五层蛋糕视角
投资建议:基础设施层和应用层是2026年的最佳切入点。基础设施层胜在确定性(Agent普及必然需要向量数据库和协议层服务),应用层胜在爆发力(找到PMF后增长极快)。
ROI分析:企业实施成本效益
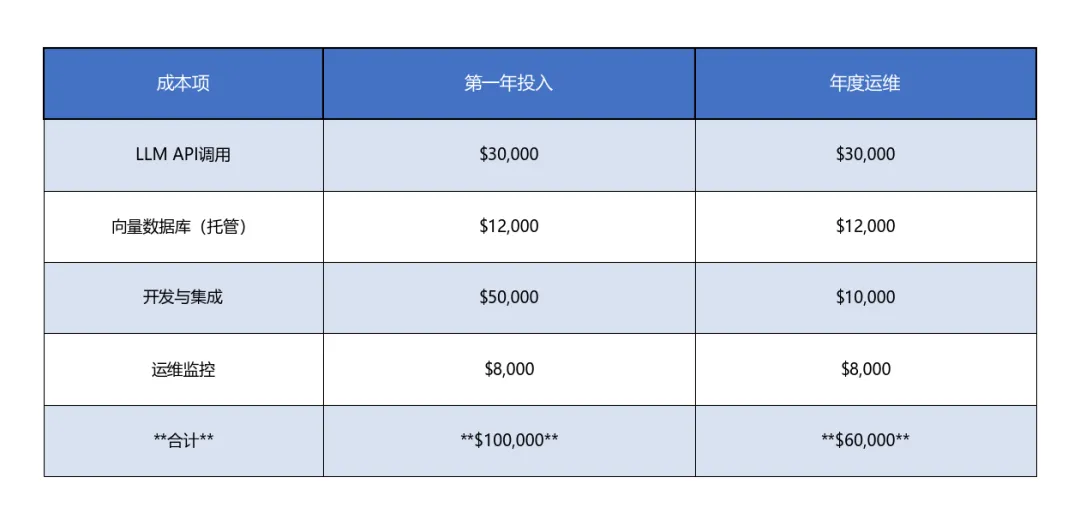
表格8
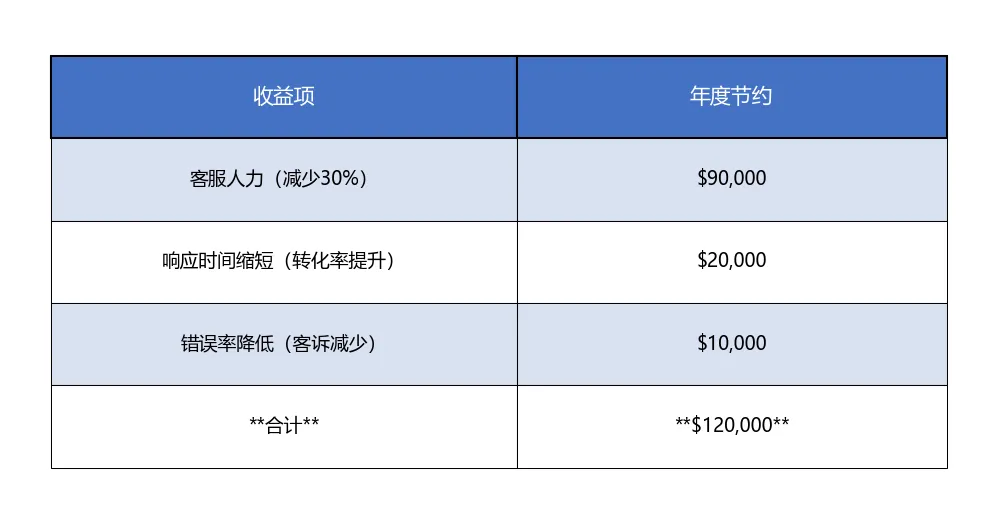
表格9
ROI = ($120,000 – $60,000) / $100,000 = 60%(第一年),第二年及以后ROI提升至100%(因无开发投入)。

结论与建议
核心观点
战略建议
对投资者:
– 短期(6-12个月):关注向量数据库和MCP生态基础设施标的
– 中期(1-2年):关注垂直行业Agent应用(法律、医疗、金融)
– 长期(2-3年):关注多智能体协作平台和Agent安全解决方案
对企业决策者:
– 从”单体Agent试点”起步,选择1-2个高价值场景验证ROI
– 规划”多智能体协作”蓝图,但不必急于一步到位
– 将Agent安全纳入企业安全治理框架,制定明确的权限和审计策略
实施路径
第一步:验证期(0-6个月) 选择1个高价值场景(如智能客服、代码审查),部署单体Agent,验证技术可行性和ROI。关键指标:任务完成率>80%、用户满意度>4.0/5.0。
第二步:扩展期(6-12个月) 将验证成功的场景扩展至3-5个,引入分层记忆系统和MCP工具生态。关键指标:跨会话记忆准确率>90%、工具调用成功率>95%。
第三步:协作期(12-24个月) 构建多智能体协作体系,实现复杂任务的端到端自动化。关键指标:多Agent协作任务完成率>85%、协作一致性>95%。
风险提示

数据来源

附录
A. 核心术语解释
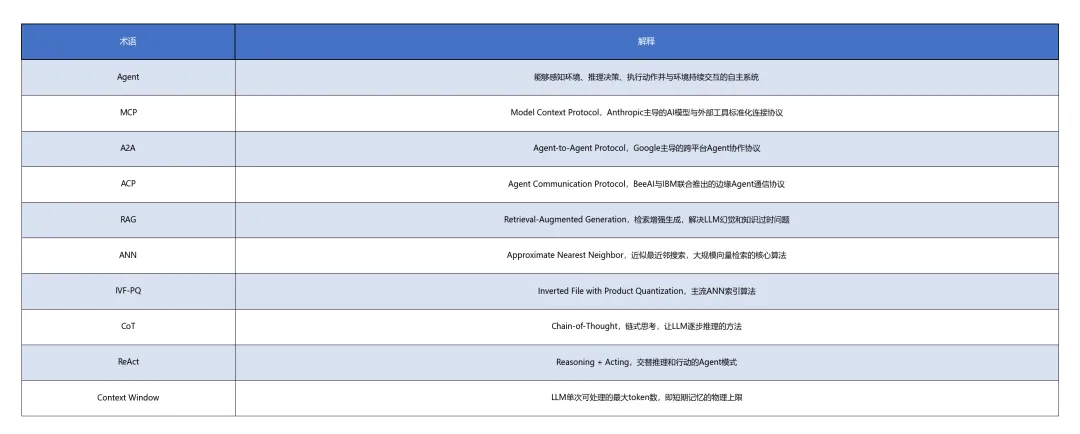
表格10
B. 相关资源链接
C. 推荐阅读

研究者观察
独立观点
当前Agent领域的发展轨迹,与2014-2018年微服务架构的演进惊人相似:
– 单体 vs 单体Agent:都面临”把所有功能塞进一个系统”的困境
– 服务拆分 vs 多Agent协作:都将系统拆分为独立组件,通过标准化协议通信
– 服务网格 vs 协议层:都引入专门的通信层解决服务发现问题
– API网关 vs Agent网关:都需要统一入口处理认证、限流、监控
微服务架构用了约5年(2014-2019)从概念验证走向企业标配。Agent技术2023年起步,预计2028年左右达到同等成熟度。这意味着2026-2027年是Agent基础设施投资的最佳窗口期——类比微服务时代的Kubernetes、Service Mesh等基础设施的投资回报。
支撑论据:
– MCP协议的设计哲学与gRPC/REST API标准化高度相似——都是”定义接口规范,让不同系统能互相调用”
– A2A协议的”Agent Card”概念与服务注册中心(Consul/Eureka)的功能一致——都是”服务发现+能力描述”
– 多Agent编排层(LangGraph/CrewAI)的功能与Kubernetes的调度器一致——都是”任务分配+状态管理”
影响分析: 如果这一类比成立,Agent基础设施层(向量数据库、协议网关、编排平台)将最先爆发,而非应用层。这与当前市场”重应用轻基础设施”的投资倾向形成反差,可能意味着基础设施层存在被低估的投资机会。
观点二:记忆系统的”时间感知”能力是Agent从”工具”进化为”伙伴”的关键
当前大多数Agent记忆系统只存”内容”不存”时间”,导致Agent无法判断一条记忆的时效性。例如用户说”我下个月要去纽约出差”,Agent如果不知道”下个月”的具体时间范围,可能在未来任意时刻提醒用户——一个月后提醒是贴心,一年后提醒就是骚扰。
Zep/Graphiti框架引入的”时间感知”概念[16]是这一方向的先驱——给每条记忆标注”有效时间窗口”。但这一能力尚未成为行业标配。
我的判断是:2027年,时间感知记忆将成为企业级Agent的标配功能。因为:
– 没有时间感知,Agent的”个性化服务”将退化为”机械重复”
– 时序知识图谱技术(Temporal Knowledge Graph)的成熟使这一功能的技术门槛降低
– 用户对Agent的期望正在从”能做事”升级为”懂我”,时间感知是”懂我”的必要条件
技术逻辑: 人类记忆的精髓不在于”记住一切”,而在于”知道什么时候该想起什么”。Agent记忆系统的设计也应遵循这一原则——不是存储更多数据,而是建立更精准的”记忆触发机制”。
趋势预判: 未来2-3年,Agent记忆系统的竞争将从”存储容量”转向”检索精度”和”时效管理”。向量数据库厂商(如Pinecone、Milvus)可能推出原生时间感知索引,记忆框架(Mem0、Letta)可能内置时序推理能力。
跨维度分析
技术 × 商业:协议标准化的经济意义
MCP/A2A协议的标准化不仅是技术问题,更是商业问题。类比HTTP协议催生了Web经济(电商、SaaS、社交媒体),Agent协议的标准化将催生”Agent经济”——一个新的万亿级市场。
关键商业逻辑:
– 降低开发成本:标准化协议使Agent开发者无需为每个工具单独写适配代码,开发成本降低50%以上
– 扩大市场规模:协议互通使小团队的Agent产品可被大企业使用,市场规模扩大10倍以上
– 催生新商业模式:“Agent即服务(Agent-as-a-Service)”、“能力市场(Capability Marketplace)”等新商业模式
市场 × 监管:Agent自主性的边界争议
2026年,各国AI治理框架仍在形成中,Agent的自主决策权限是争议焦点。欧盟AI Act将”自主决策系统”列为高风险类别,要求人工监督;美国采取更宽松的”行业自律”路线;中国强调”安全可控”,要求关键领域Agent决策留痕。
这种监管分歧将直接影响Agent技术的应用边界:
– 金融领域:Agent可能被限制为”辅助决策”而非”自主交易”
– 医疗领域:Agent诊断需医生确认,不能独立出具诊断报告
– 自动驾驶:Agent控制车辆的责任认定尚未明确
全球 × 本土:中国Agent生态的独特性
中国Agent生态与全球生态存在结构性差异:
– 模型层:国产模型(DeepSeek、通义千问)成本优势明显,但技术天花板略低于GPT-5/Gemini 3
– 应用层:中国企业在客服、电商、内容生成等场景的Agent应用更为激进,部分已超越美国同行
– 协议层:中国企业对MCP/A2A的跟进速度较慢,存在”应用先行、标准滞后”的风险
– 政策层:中国对Agent的监管更强调数据安全和内容合规,增加了企业合规成本
这种差异意味着:中国Agent企业需要在”应用创新”和”标准对齐”之间寻找平衡点。过度依赖国产封闭生态可能导致与国际生态脱节,但完全跟随美国标准又可能失去本土竞争优势。
