 夜雨聆风
夜雨聆风





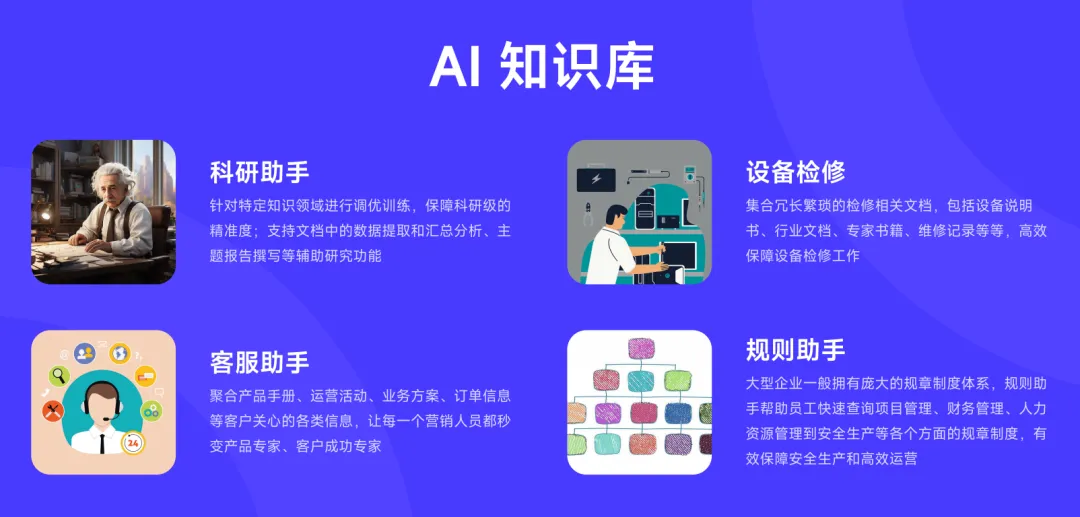
企业AI知识库不好用?先别换模型,查查这四件事
很多企业搭完AI知识库,用了一周就放那了。问它个问题,要么答非所问,要么编一段听起来像那么回事但实际不对的内容。老板一问”这个知识库到底能不能用”,没人敢接话。
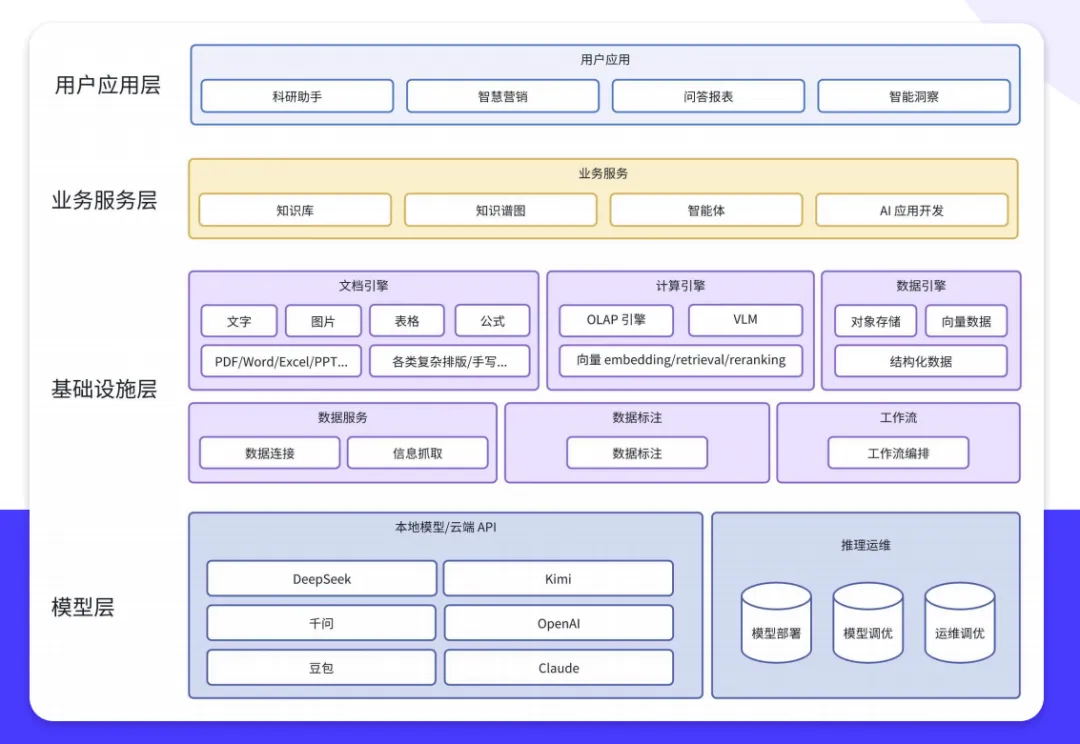
大多数情况下,问题不在模型,在数据。 图博数智帮企业搭知识库这两年,见得最多的就是:模型花了不少钱,但前面的数据处理根本没做到位。
文档直接丢进去,等于没搭
这是最常见的坑。很多团队觉得知识库就是”把文档传上去,AI自动学会”。
现实是,企业文档质量参差不齐。有的是扫描版PDF,连文字都识别不清;有的是好几版的合同,改过的条款混在一起;有的是口头约定的流程,从来没写成文档。
知识库的第一步不是选模型,而是把数据洗干净。 去重、去噪、统一格式,该拆的拆,该合并的合并。这一步没做好,后面模型再强也是白搭。

分块方式决定了回答质量
知识库背后的技术叫RAG(检索增强生成),原理很简单:先把文档切成小块存起来,用户提问时找到最相关的几块,交给模型组织回答。
问题出在”切块”上。
按固定字数切,一句话可能被切成两段,上下文全丢了。按段落切,有些文档段落特别长,检索出来的内容全是冗余信息。
分块策略需要根据文档类型来定。 产品手册按章节切,合同按条款切,技术文档按功能模块切。切对了,检索精度直接提升30%以上。
检索不到,再强的模型也没用
用户问”报销流程怎么走”,知识库里明明有,但模型说”未找到相关信息”。这种情况非常普遍。
原因通常有两个:用户的表述和文档的表述不一致(用户说”报销”,文档写”费用申请”);或者检索只做了关键词匹配,没有语义理解。
图博数智的做法是在检索层加上语义重写——先把用户的问题”翻译”成和文档一致的表述,再去检索。同时结合关键词检索和向量检索两条路走,命中率会高很多。
没有反馈机制,知识库不会变好
很多企业搭完知识库就交差了,没有人持续维护。用户发现回答不对,最多抱怨一句,不会有人去标注和修正。
但好的知识库需要持续迭代。哪些问题答错了?哪些文档没覆盖到?哪些表述用户根本看不懂?这些信息都需要收集。
知识库不是搭完就结束的项目,是搭完才刚开始的产品。 需要有人定期看反馈日志,补充缺失内容,修正错误回答。一个月维护一次,效果就能持续提升。
怎么判断你的知识库该优化了
三个信号,出现任何一个都该动手:
回答准确率低于70%。 随机抽20个常见问题测试,有6个以上答不准,说明数据层或者检索层需要调整。
用户主动使用率持续下降。 第一周大家觉得新鲜会试试,到第三周如果没人用了,说明体验没有达到预期。
同类问题反复出错。 说明不是偶发问题,而是某类数据或者某个检索路径有系统性的缺陷。
正确的搭建顺序
总结一下图博数智的项目经验,企业知识库搭建的正确路径是:
- 1. 先梳理业务场景:知识库要服务谁?回答什么类型的问题?优先级是什么?
- 2. 再做数据治理:清洗、整理、结构化你的文档,这一步占总工作量的40%以上
- 3. 然后选技术方案:根据数据量和场景需求选模型和部署方式
- 4. 最后持续运营:上线后每周看反馈,每月做优化
很多企业把第3步放在第1步做,选了最贵的模型,结果发现数据根本没准备好,钱白花了。
如果你正在评估企业知识库方案,或者现有知识库效果不理想,可以找我们聊聊,帮你做个快速诊断。
