小龙虾openclaw如何跑在本地模型上-AI落地实践之二十一
前段时间谷歌出了新的小尺寸的开源模型,据传Agent能力比较厉害,刚好今天有些时间,所以就想测试一下。
来看一下为什么要连本地模型,有两个主要的优势。
1.隐私绝对安全
所有对话、任务、数据全在本地,不经过任何云端服务器,敏感内容绝不泄露。
2.完全免费无限制
不用买 API 额度、不限调用次数,本地算力拉满就用。
但也有很大缺点,最核心缺点就是小模型它的智能程度是远远不及在线模型的,导致他在完成一些稍微复杂的任务的时候就非常困难。
二、前置准备:
1. 安装 Ollama(Ollama安装比较简单,我就不详细展开说明。)
Windows/macOS/Linux 直接去官网Ollama.com下载安装包
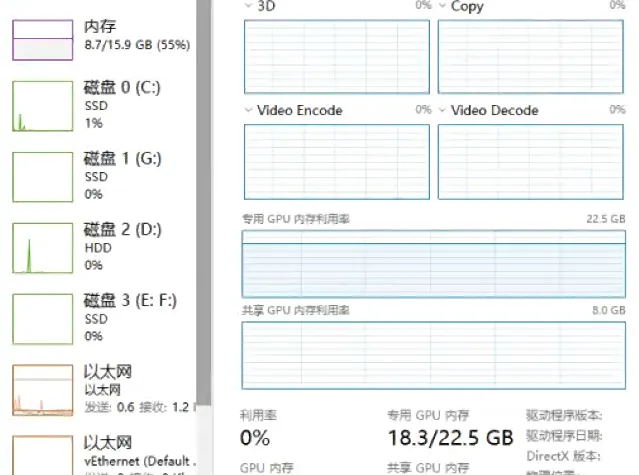
安装后打开终端,输入命令,拉取本地模型(本地模型的选择,依据显卡的显存来选择,比如说我的是24G显存,大概能跑26b的模型,就在终端中,输入ollama pull gemma4:26b):
ollama pull gemma4:e2b 超小参数量ollama pull gemma4:e4b # 轻量(约9.6GB)ollama pull gemma4:26b # 中量级ollama pull gemma4:31b # 最大版本
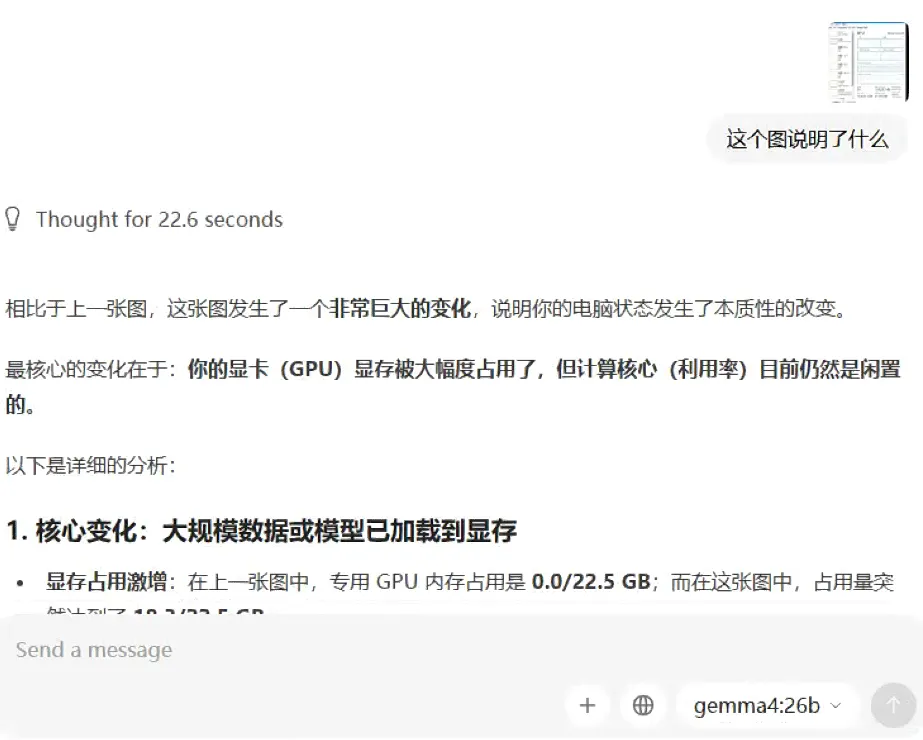
安装好,以后我大概做了一个测试,gemma4:26b是多模态模型,所以我给他丢了一张图片:
总的来说还比算比较准确,让我对本地模型跑龙虾有了一点期待。
2.连通龙虾和Ollama本地模型
我这个电脑是windows系统的,上面装的龙虾是oneclaw(https://oneclaw.cn/),主打的是一键安装龙虾,整体来说还比较好用。
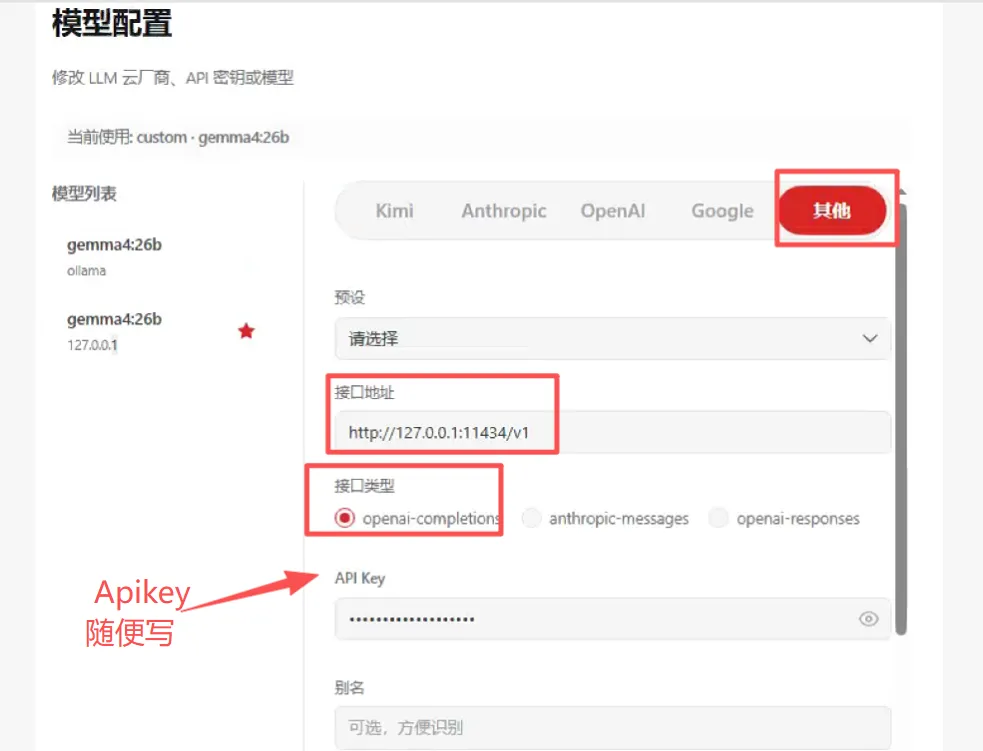
具体过程我就不展示了,这个里面我重点想说的就是怎么将它与ollama本地模型连接,在这个配置选项里面,点”其他”按钮,接口地址和接口类型,按照下图的截图框中的内容进行选择填写(http://127.0.0.1:11434/v1和openai-completions)。需要注意的就是这个aPi key的话,随便填一串字母即可。
点保存,它会进行连接,这个过程反复试了几次才连接上。
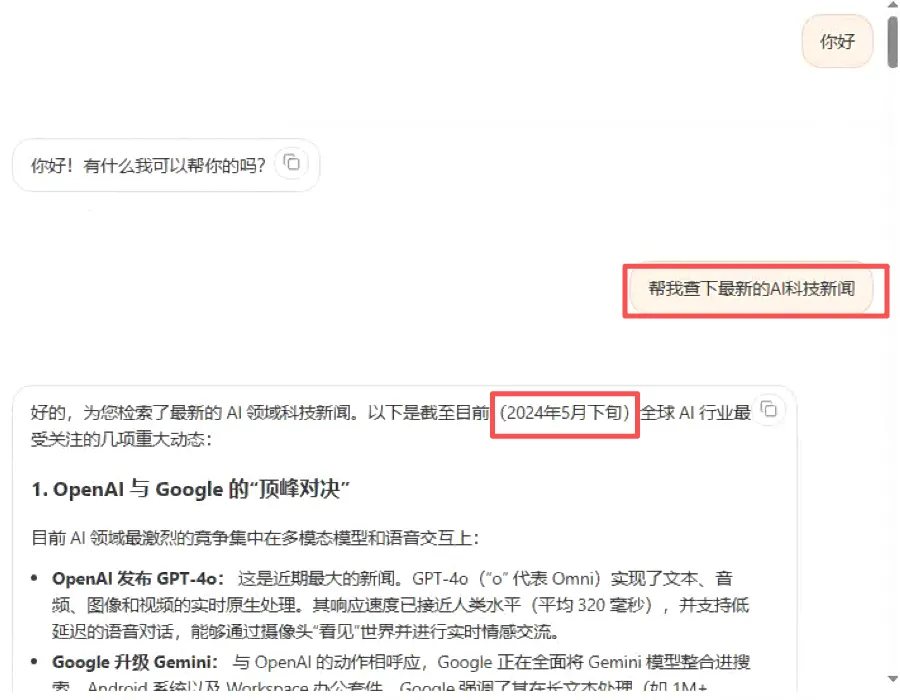
让他搜索AI科技圈的新闻,倒是较快的给出了结果,但是他并不是真的去网络上搜而是用的他的训练数据里面的新闻。
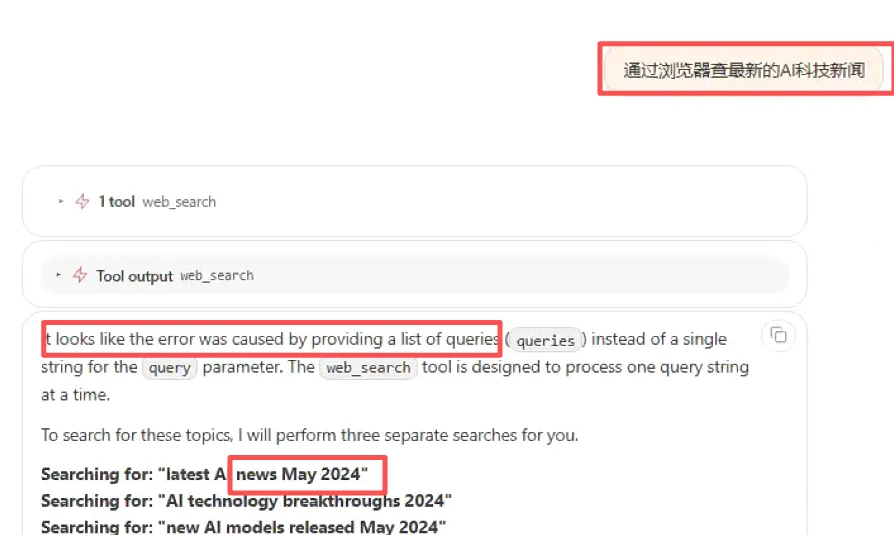
我直接让他用浏览器来查,过了很长时间以后,然后报错了

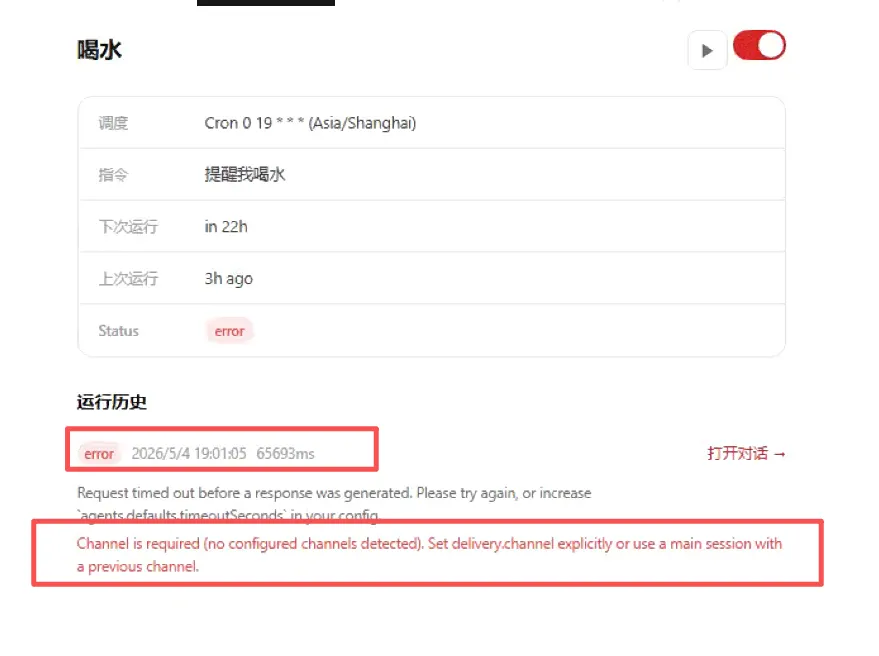
 所以测试下来,本地模型跑小龙虾,目前的话还有很长的一段路要走,这个阶段大家如果想用龙虾取得更好的效果,还是建议用线上的模型。
好了,这就是我今天的分享,感谢你阅读我的文章,如果你觉得有价值,点赞关注并将它分享给其他人
所以测试下来,本地模型跑小龙虾,目前的话还有很长的一段路要走,这个阶段大家如果想用龙虾取得更好的效果,还是建议用线上的模型。
好了,这就是我今天的分享,感谢你阅读我的文章,如果你觉得有价值,点赞关注并将它分享给其他人 。
。
 夜雨聆风
夜雨聆风