 夜雨聆风
夜雨聆风





AI知识库不该只会收藏:我想打造一个能自动加工的AI知识库,把 Dan Koe 和 LLM Wiki 合成 AIWiki
MaxKing宝藏
全栈开发者 × 量化交易 × AI 重度用户。这里记录我用 AI 提升效率、解决问题、优化流程 的真实实践,也分享工具背后的判断、踩坑和可复用方法。
AIWiki · 个人知识工厂 03
前两篇写完后,我反而更确定了一件事:
我真正想做的,不是一个普通知识库。
第一篇我讲的是收藏吃灰的问题。很多人收藏了大量文章、链接、笔记、教程,但真正要写文章、做方案、整理思路时,还是要从零开始。【为什么你收藏了那么多文章,最后还是写不出来想要的文章?你要打造自己的个人知识工厂】
第二篇我讲的是 Karpathy 提出的 LLM Wiki。它给我的启发是:知识库不应该只是资料堆,也不应该每次都靠 RAG 临时翻资料、拼答案,而应该让 AI 持续把资料读懂、拆解、整理、更新,形成一个不断生长的 Wiki。【Karpathy 的 LLM Wiki 给了我一个启发:知识库不该只是收藏夹,而是加工成可调用、可维护、可产出的内容资产,提写作和内容创作效率】
但到这里,我发现还差最后一块。
知识沉淀之后,到底怎么变成内容产出?
如果一个知识库只是越来越完整,但不能帮我写文章、做选题、产出方案,那它仍然离我的真实工作流有一段距离。
所以,我开始想:有没有可能把这两条线合在一起?
01
-MaxKing.cc-
Dan Koe 让我重新理解了内容创作
Dan Koe 给我的启发,不是某个具体模板,而是一种内容生产的思路。
很多人以为,持续输出靠的是灵感。今天有灵感,就写一篇;明天没灵感,就断更。看到好文章就收藏,看到好观点就记下来,期待未来某一天能用上。
但真正到了要写的时候,还是打开空白文档,从标题开始重新想。
每次创作都像重新开工:重新找资料,重新想角度,重新设计结构,重新找案例,重新组织表达,重新说服自己这篇文章值得写。
不是因为没有输入,而是输入没有变成可复用资产。
一篇文章如果只是被收藏,它还是别人的文章。只有当它被拆出来,变成观点、钩子、结构、案例、金句、转化弧、选题和大纲,它才开始变成你的素材。
我现在越来越觉得,内容创作不是从空白页开始,而是从素材库里长出来。
Dan Koe 这条线解决的是:内容如何持续输出。
02
-MaxKing.cc-
LLM Wiki 让我看到知识沉淀的另一种方式
但只解决内容输出还不够。
如果所有素材只是散落在一堆文档里,时间久了,还是会乱。
这时候,Karpathy 的 LLM Wiki 给了我另一个启发:
知识库不应该只是临时检索资料,而应该被 AI 持续编译和维护。
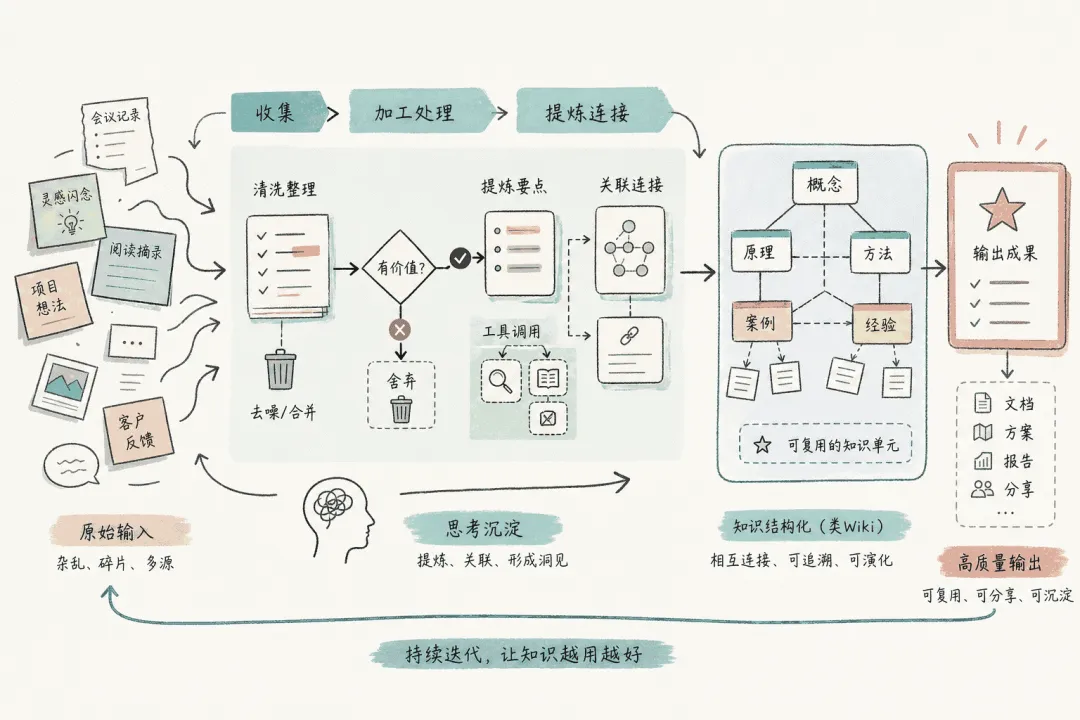
传统 RAG 更像“临时翻书”。你问一个问题,系统去资料堆里找相关片段,然后临时拼出一个答案。
这当然有用。但问题是,这次回答结束之后,知识有没有真正沉淀?下次再问类似问题时,是不是还要重新检索、重新拼接、重新组织?
LLM Wiki 的思路不一样。它不是每次都临时找答案,而是在资料进入系统时,就开始做整理:保留原文、提取概念、更新页面、建立关联,把原始资料变成可维护的 Wiki。
这样,知识不是问的时候才被临时拼出来,而是在平时就被持续整理、更新和沉淀。
LLM Wiki 这条线解决的是:知识如何长期沉淀。
03
-MaxKing.cc-
一个偏输出,一个偏沉淀,但单独看都不完整
这两条线单独看都很有价值。
但我越想越觉得,单独做其中一个,都不够完整。
如果只学 Dan Koe 的内容系统,我会更重视选题、表达、内容资产、写作结构。但这些素材如何长期沉淀?如何更新?如何关联?如何避免越积越乱?这仍然是问题。
如果只做 LLM Wiki,我可能会得到一个更好的知识系统。它能保存原文、整理概念、更新 Wiki、建立知识关联。但这些知识如何变成选题、文章、公众号内容、视频脚本、项目方案?这条输出链路还不够直接。
我理解的两条线
Dan Koe解决内容资产、持续输出、选题和表达的问题。
LLM Wiki解决知识沉淀、持续维护、结构化 Wiki 的问题。
AIWiki要把资料变成知识资产,再让知识资产持续服务内容产出。
所以我不想只做一个能存资料的知识库,也不想只做一个写作素材库。我想要的是二者之间的闭环。
04
-MaxKing.cc-
所以我想把它们合成 AIWiki
这就是 AIWiki 的定位。
它不是普通 Obsidian 模板,不是提示词合集,不是另一个收藏夹,也不是单纯的 RAG 知识库。
我想做的是:把资料加工成知识资产,再让这些知识资产持续服务内容产出。
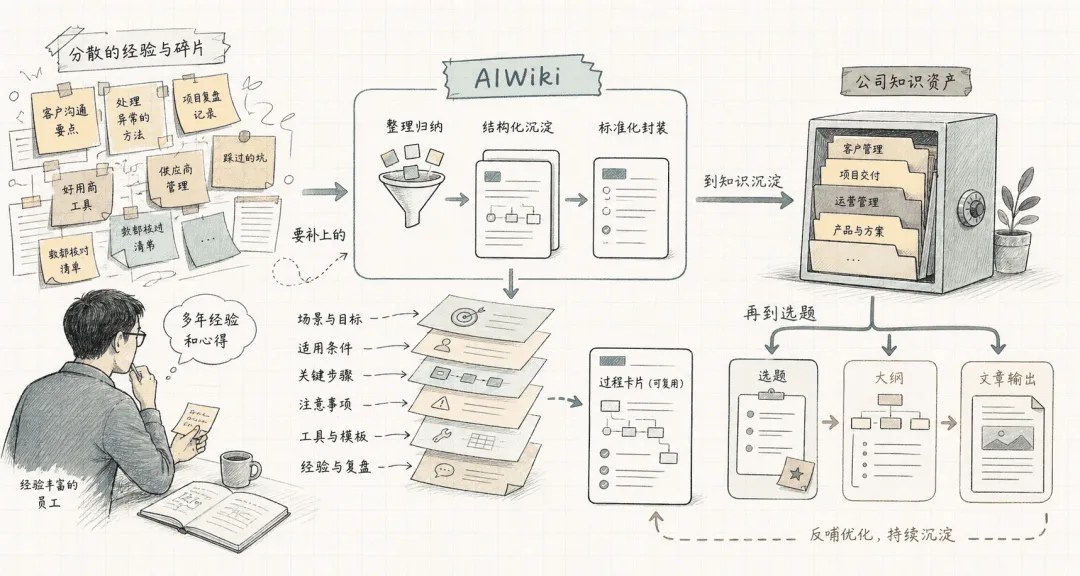
一篇文章或一个链接进入 AIWiki 后,不应该只是被保存。它应该经历一轮加工:先保留原文,再生成资料卡,再提取关键观点,再沉淀到相关知识页面,再拆出创意积木,再生成可写选题,再生成文章大纲,最后支撑内容产出。
文章 / 链接
↓
Raw 原文归档
↓
Source Card 资料卡
↓
Wiki 知识沉淀
↓
Creative Assets 创意积木
↓
Topics 选题 / Outline 大纲
↓
内容产出 / 反馈回流
这才是我理解的个人知识工厂。
不是资料进来就结束,而是资料进来后,要继续被拆、被连、被用、被复盘。
05
-MaxKing.cc-
AIWiki 的核心是加工,而不是收藏
我现在越来越觉得,知识库最容易被误解的地方,就是大家太关注“存”。
存在哪里?怎么分类?怎么打标签?用 Notion 还是 Obsidian?要不要双链?要不要图谱?
这些都重要,但它们不是最核心的问题。
真正核心的问题是:这条资料最后有没有被用起来?
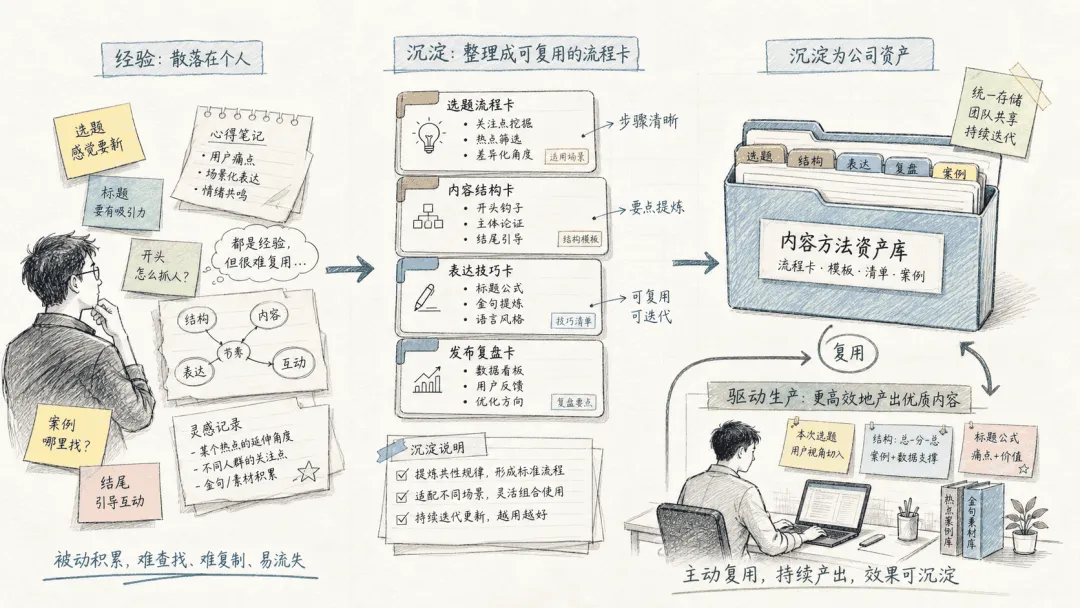
一条资料进入 AIWiki 后,至少应该变成一个知识页面、一张资料卡、一个创意积木、一个选题、一份文章大纲,或者一篇内容。
如果它什么都没有变成,只是静静躺在文件夹里,那它和普通收藏没有本质区别。
06
-MaxKing.cc-
第一版只解决一件事
AIWiki 后面当然可以做很多事情。
比如自动收集资料、批量处理链接、接入飞书群、接入微信和 Discord、接入 OpenClaw / QClaw、做团队知识流。
但第一版我不想一上来做大而全。
第一版只解决一件事:把一篇资料加工好。
用户手动给一篇文章或一个链接。AIWiki 能自动生成原文归档、Source Card、创意积木、选题和文章大纲。
这一件事先跑通。
如果一篇资料都加工不好,批量只会批量制造垃圾。
所以第一版要克制。先把最小闭环跑起来。
07
-MaxKing.cc-
下一篇,我会把流程图画出来
到这里,AIWiki 的定位就清楚了。
Dan Koe 解决输出。LLM Wiki 解决沉淀。AIWiki 要做的是把二者连成一条工作流。
这条工作流不是为了让收藏夹更大,而是为了让资料真正变成可沉淀的知识、可复用的积木、可延展的选题、可写作的大纲、可发布的内容。
下一篇,我会把整个 AIWiki 的流程图画出来。
一篇文章或一个链接,如何从 Raw 原文归档,变成 Source Card 资料卡,再变成创意积木、选题和文章大纲,最后进入内容产出和回流。
如果你也想看这套系统怎么搭,可以关注公众号,回复:
AIWiki
我会继续整理《AIWiki 个人知识工厂流程图》,
也会在群里同步最新开发进度。
AIWiKi永久免费
下一篇预告
AIWiki 个人知识工厂流程图:一篇文章如何变成内容资产?
– END –
关于 MaxKing宝藏
我是 MaxKing,全栈开发者、量化交易实践者,也是 AI 重度用户。这里分享的不是遥远概念,而是我在真实使用、搭建和踩坑后留下的判断。
如果这篇文章对你有启发,欢迎点赞、在看、转发,也欢迎加我好友交流 AI 工具和自动化实践。