 夜雨聆风
夜雨聆风





给每个还在用 OpenClaw 的用户的忠告
OpenClaw 推出到现在已经快五个月了,那一波热潮也终于过去了。现在我不知道还有多少人留下来还在用,你们拿 OpenClaw 是用来做什么的?
我身边的朋友,有做投资金融的,有做项目管理的,还有做自媒体的。无一例外,都是看中了 OpenClaw 的多 Agent 优势。
虽然我现在主要用的是 Claude Code 和 Codex。
但 OpenClaw 的多 Agent 功能应该是目前为止市面上比较好的,所以我选择把一部分工作留了下来。
这几个月用下来,我摸清了它的边界,也找到了到底什么工作才适合放在 OpenClaw。
今天把这些实操经验整理出来,给还在用的朋友一个参考。

▶一个暴论,OpenClaw 压根就不适合中大型编程任务
有些人可能会说:不不不,我可以在 OpenClaw 里通过 ACP 或者 tmux 调用 Claude Code、Codex 去执行编程任务啊?
但既然你可以直接找他们,为什么要多一层中转?直接在对应的 Agent 工具里进行流转、进行会话的不是更好吗?
现在 Codex App 的功能性,可视化的程度也远远要高于 OpenClaw了。
而且每一层转发都在烧 Token。 Agent 间的沟通也不一定能完整传达你的意思。你跟龙虾的 agent 说”重构登录模块”
到 Codex 那可能变成了”改一下登录页面的样式”。就算单一 Agent 执行任务,OpenClaw 自身的动作执行也经常跑偏,花在纠偏上的时间,可能比你自己动手还多。
有人说“我就是想在手机上看到编程任务的进度”——那你装一个远程桌面 app,不比这方便多了。
就算你用最好的模型,Opus 4.7 或者 GPT 5.5,在 OpenClaw 里用的体验,都比不上直接在 Claude Code 或 Codex 里用。
那 OpenClaw 到底适合什么?
▶多 Agent 协作,是它最擅长的事
我日常手上同时推进四五个项目。
在没有多 Agent 之前,我的状态是这样的:每天早上打开飞书,看到一堆待办,先愣三分钟——不知道该先干哪个。
好不容易选了一个项目 A 推进,干到一半又想起来另一个项目还有个截止日期。下午在项目 A 和项目 B 之间反复横跳,晚上复盘发现每个项目都没推进多少。
我现在在 Openclaw 里拆成了三个 Agent,虽然执行者还是我,但是我把每天最头疼、最内耗的“脑力劳动”转移了一部分给 Agent。

第一个:任务管理 Agent
它只负责一件事:进度记录。不负责任何执行。
我和它以飞书 CLI 的任务管理功能为沟通中台,每天早中晚三个时间点:早上记录任务,中午同步进度,晚上复盘。
每周和每月还会做周期复盘,包括项目推进进度和细节执行情况。
它就像一个秘书,告诉我每天应该先做哪些事情,并且及时提醒我哪些事情推进到哪里了。
写周报或者月报的时候,也可以通过跟他对话来了解自己到底干了什么,而不用一直翻聊天记录或者会话记录。

第二个:Idea Coach
这是整个架构里最关键的环节。
任务管理 Agent 完成记录之后,通过 Session Send 把今天的内容发给 Idea Coach。然后逐个分析每个项目今天该干什么。
目的就是把”搭建某某中台”这种抽象概念,拆到你能直接上手的每一步——具体做什么、先做什么、拿到就能干。

第三个:写稿 Agent
负责帮我写文章和管理知识库,偏向文案类工作。如果是文字类的工作,Idea Coach 就会先 发给他,让他帮我进行工作。
当然,他还负责热点搜索、知识库编译。
如果当天的项目里有编程任务,Idea Coach 会直接给我一个接力提示词,我自己去找 Claude Code 或者 Codex 执行。回到传统的 CLI 或 Codex App 里接续代码工作。
我现在完全用飞书文档 + 多维表格做中台,飞书 CLI 把整个流程串起来。
任务管理 Agent 记录的东西全落到飞书,Idea Coach 从飞书里读,写稿 Agent 又从 Idea Coach 的输出里继续工作。
省心,丝滑。
▶选对模型才能多快好省
如果说当下只讨论 token 最低成本的话,那么 M2.7 当之无愧的 Top1 了。
但在 OpenClaw 里用过的朋友应该都有体会。你需要给它非常强的约束,它才能”正常”执行任务——注意是”正常”,不是”完美”。
它只适合那些只想玩一下 OpenClaw,但又不想折腾 API 或者各种模型的用户。但如果是长期使用的话,MiniMax 的当,上一次就够了。
要论质量,GPT 5.5是目前最适配 OpenClaw 的 SOTA 模型。但如果你对上下文 Token 管理做得不好,一个 Plus 套餐可能也撑不到周限额。好处是它性价比已经很高了,土区仅需 80 大洋。

我自己现在用 DeepSeek V4,感觉是越用越好用了。想要快速快速低成本选 Flash ,想要深度推理更精确选 Pro。
思考模式开个High,效果还是很好的。
工具和 skill 调用上也很积极,实测下来工具调用能力在国模里仅次于 GLM。
而且OpenClaw 4.24 版本已经针对 DeepSeek V4 做了上下文缓存优化。我每天的缓存命中率做到 93%,甚至 97%。
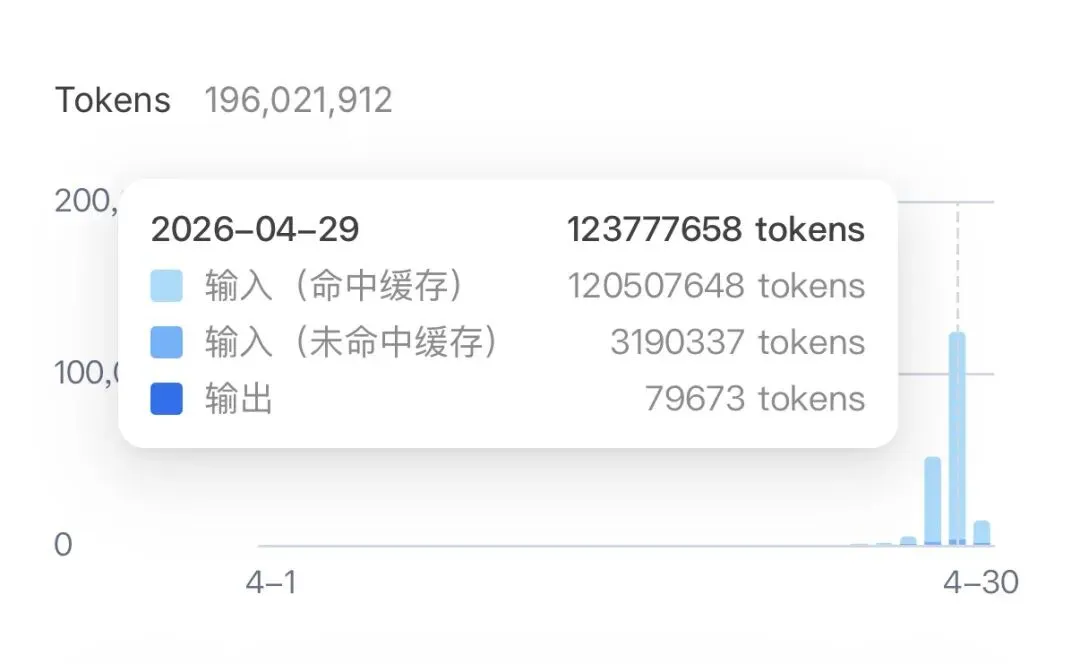
DeepSeek V4 刚出没几天我就接到龙虾了,其中有一天花了一亿两千万 token,一天下来3个会话在同时用 V4 Flash,实际花费5.75元
唯一缺点:没有多模态能力。如果你很需要,直接上 Kimi,能抢到 GLM 也行
▶降 Token 的四个重要技巧
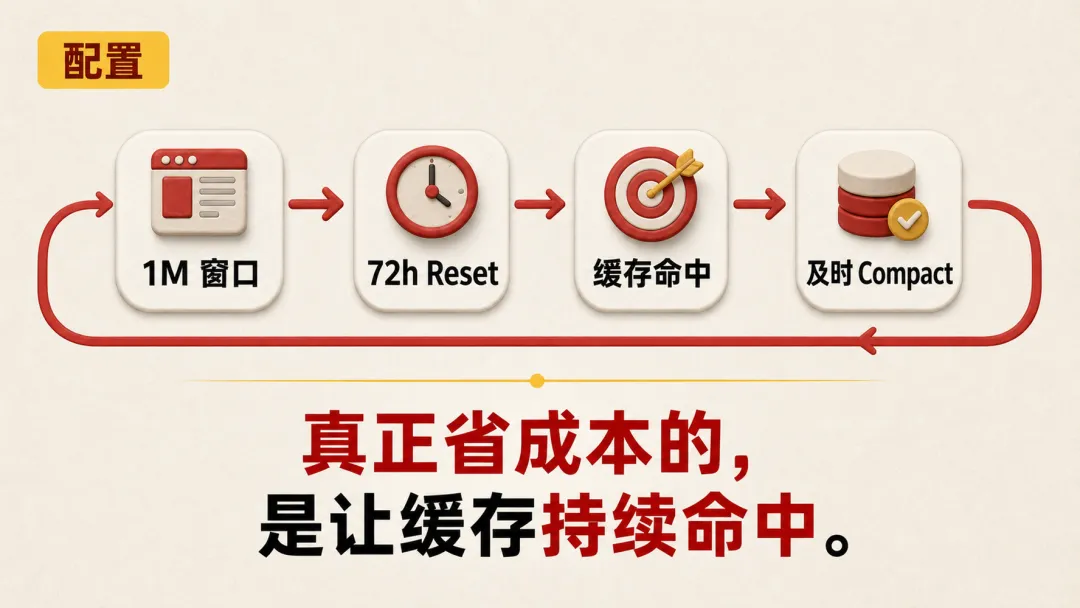
选对模型只是第一步,真正把成本压下来,靠的是四个配置调整。
1. 上下文窗口填 1M,不要用默认的 200K
OpenClaw 默认上下文窗口是 200K,但 DeepSeek V4 支持 1M。填模型配置的时候一定要改。这是后面所有优化的大前提。
2. 把”凌晨4点重置”改成”闲置72小时后重置”
OpenClaw 默认有一个凌晨 4 点重置会话的机制,目的是减少上下文污染,初衷是好的。
但这个设计的背景是大部分模型只有 200K 的上下文窗口,一天下来基本满了。
但 1M 窗口下,我一天的上下文占用大概 200K 到 300K。1M 完全可以撑好几天。
所以我把重置策略改成了“闲置 72 小时后自动重置”——只要我在 72 小时内跟它有过任何一次对话,会话就不会重置。
3. 缓存命中率是省钱的核心
只要不重置会话,缓存就都还在。1M 上下文窗口下,你可以持续跟它对话,源源不断地命中缓存。
DeepSeek V4 Flash 的缓存命中价格说他白菜价都贵了。。
大家可以对比下其他模型 API 的缓存命中价格,应该是很明显的(这里点名 Mimo的 Token Plan)
命中缓存省下的成本,远远高于偶尔建新会话时的缓存建立费用。
4. 700K-800K 时手动 compact
1M 的窗口不是无限的。我测试到 700K 到 800K 左右时,会出现一些漂移现象
Agent 可能开始跑偏、理解出错。这个时候就需要手动执行 compact 或者 reset。
当然你不手动执行也行。当会话自动达到 1M 的时候,系统也会自动执行 compact。
虽然建新会话会产生稍高一点的缓存建立费用,但你在正常聊天过程中命中缓存所节省的成本,远高于这部分支出。
▶记忆:别整那么多花里胡哨的了,用日记 + 语义搜索
OpenClaw 的记忆一直是痛点。
我之前用 Hermes Agent 的时候,发现它恨不得把所有聊天内容都进化成 skill。好处是不怎么忘事了,缺点就是人味缺了一点,它更偏向单 Agent 自进化的设定,简称工具人。
OpenClaw 它不会主动把所有东西都做成 skill。但如果你想让它的记忆靠谱,不用加太多插件,更不要开启心跳,这东西真的很费 Token。
我现在稳定在用的方案就两步。
第一步:每天凌晨 3 点,定一个 cron 任务
让 Agent 总结从前一天 3:00 到当天 3:00 的内容,在 Tools 文档中写明写入规范,按照固定格式写入 Memory。
就像让 Agent 每天写一篇固定格式的日记。你先把 Memory 的格式标准化,之后 Agent 按格式去读的时候,整体会更清晰,知道你们发生过什么、它帮你做过什么。

第二步:本地 Ollama + 向量模型 + QMD 语义搜索
在本地用 Ollama 装一个向量模型接入 Openclaw,然后用 QMD 做语义搜索。这样 Agent 既能抓取 Memory,也能进行语义搜索。
两者结合,基本上 Agent 就不再会失忆了。
▶正确的人干正确的事
假如你下一次发现自己在 OpenClaw 里调试一个编程任务调了半小时还没调对,也许该想想:这个任务是不是该交给 Claude Code 了?
OpenClaw 的价值在于多 Agent 协作规划,在于让它当你的项目管理中台,帮助你更高效的处理项目进度,它不是一个全能选手。
现在各家 Token Plan 也早已不打价格战,甚至都限售了,趁现在还是多学一点省 token 的技巧吧。
这里是 Jetson,在人人追新 Agent 的时代,聊聊怎么把手里这个用好。