 夜雨聆风
夜雨聆风





大模型是怎么切词的?了解BPE、WordPiece、Unigram和SentencePiece
我们平时和大模型聊天,输入的是一句话、一段文字,甚至是一篇文章。但模型真正看到的,并不是这些文字本身。在进入大模型之前,文本通常要先经过一个步骤:
Tokenize,也就是分词。
简单来说,tokenize的作用就是把一整段文本,切成一个个模型能够处理的小片段。这些小片段就叫token。
比如一句话:
我喜欢大语言模型在人看来,这是一句话。但对模型来说,它可能会被切成:
我 / 喜欢 / 大语言 / 模型也可能被切成:
我 / 喜 / 欢 / 大 / 语言 / 模型甚至在不同模型里,切法还不一样。这就引出一个问题:
大模型到底是怎么切词的?
为什么大模型不能直接读文字?
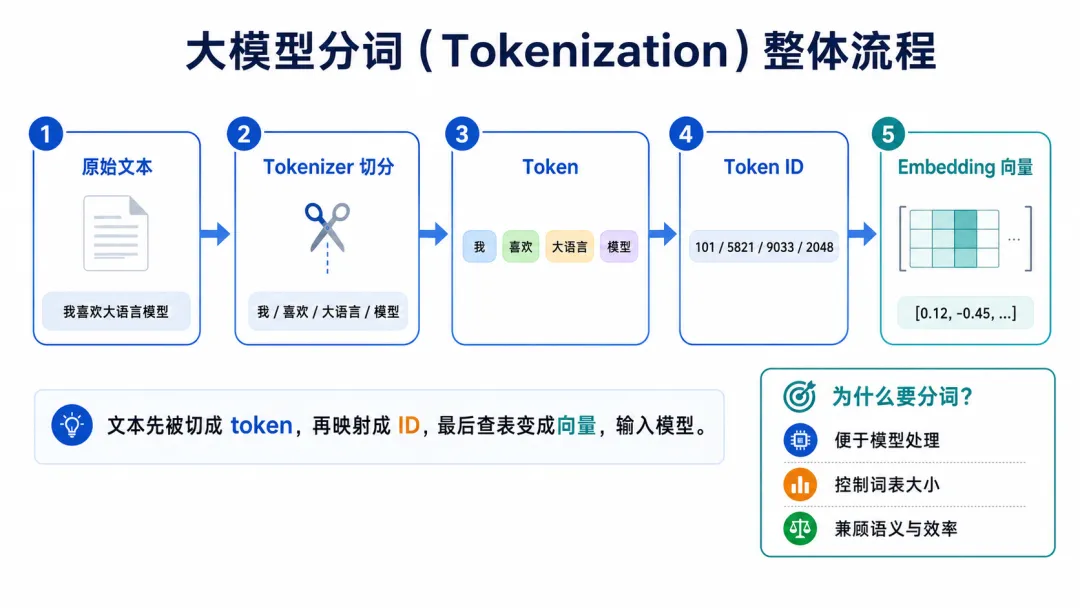
因为模型本质上处理的是数字。文字进入模型之前,一般要经历三个步骤:
文本 → token → token ID → embedding 向量也就是说,模型不是直接理解“我喜欢大语言模型”这些文字,而是先把它们变成token,再把token映射成数字编号,最后查表得到向量。这个切成token的过程,就叫tokenizer。
tokenizer切得好不好,会影响很多事情:
-
序列长度 -
词表大小 -
计算成本 -
模型理解能力 -
新词处理能力
所以,分词不是一个小细节,而是大模型输入系统里非常重要的一环。
最基础的三种切分粒度
大模型分词,最基础可以分成三种粒度:
-
word:按词切
-
char:按字符切 -
subword:按子词切
1、按词切:最符合人类习惯,但词表太大
按词切是最自然的方式。比如:
I like language models可以切成:
I / like / language / models中文也可以切成:
我 / 喜欢 / 大语言模型这种方式的优点是很好理解,每个token往往具有比较完整的语义。
但问题也很明显:
词太多了。
自然语言里有大量长尾词、专有名词、缩写、拼写变化、生僻表达。
比如:
ChatGPTTransformerbioconcentrationnon-targeted......
如果每个词都放进词表,词表会变得非常大。词表越大,embedding表也越大,占用的显存和内存也越多。所以,单纯按词切,在大模型里并不是最理想的方案。
2、按字符切:词表小,但句子会变长
另一种方法是按字符切。
比如英文:
hello切成:
h / e / l / l / o中文:
大语言模型切成:
大 / 语 / 言 / 模 / 型这种方法的优点是词表很小。英文就是字母、数字、符号;中文虽然字符更多,但也比完整词表小很多。它还有一个好处:
几乎不会遇到完全没见过的词。
但缺点也很明显:
句子会被切得很碎,序列长度变长,计算成本增加。更重要的是,每个字符本身包含的信息有限。比如“模”“型”分开看,语义并不完整;只有组合成“模型”,意思才更清楚。
所以,按字符切虽然简单,但表达能力有限。
3、按子词切:现代大模型最常用的折中方案
现在很多大模型采用的是第三种方式:
subword,子词切分。
它介于“词”和“字符”之间。核心思想可以用一句话概括:
常见词尽量保留,生僻词拆成更小的片段。
比如:
Transformers可能会被切成:
Transform / ers再比如:
unbelievable可能切成:
un / believe / able这样做的好处是既不会像按词切那样导致词表爆炸,也不会像按字符切那样把句子切得太碎。所以,子词切分是目前大模型tokenizer的主流思路。
常见tokenizer方法有哪些?
常见的大模型词表构建方法主要有四类:
-
BPE -
WordPiece -
Unigram -
SentencePiece
它们的目标都差不多,构建一套合适的token词表,让文本既能被稳定表示,又不会让词表过大。
但它们的做法不一样。
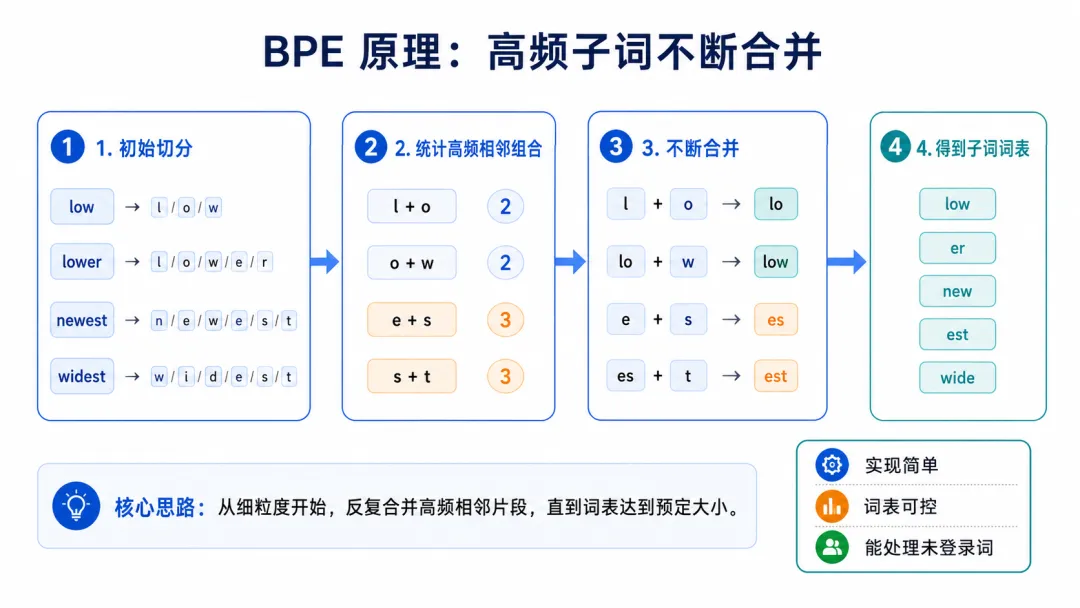
1、BPE:从字符开始,不断合并高频组合
BPE,全称是Byte-Pair Encoding,字节对编码。它最早来自数据压缩思想,后来被用到NLP分词中。BPE的核心逻辑很简单:
谁经常挨在一起,就把谁合并。
举个简单例子。假设语料里有这些词:
lowlowernewestwidest
一开始,BPE会先把它们拆成字符:
l / o / wl / o / w / e / rn / e / w / e / s / tw / i / d / e / s / t
然后统计相邻字符组合出现的频率。如果发现:
e + s经常一起出现,就把它们合并成:
es接着继续统计。如果发现:
es + t经常一起出现,就继续合并成:
est不断重复这个过程,直到词表达到预设大小。最后,词表里可能会有:
lowerestwidenew
这样新来一个词:
lowest就可以被切成:
low / estBPE的优点是:
-
简单 -
高效 -
能处理未知词 -
词表大小可控
很多GPT系列模型、RoBERTa等模型,都使用过BPE或类似BPE的方法。
2、WordPiece:不只看频率,还看组合是否更合理
WordPiece也属于子词切分方法。它和BPE很像,也会从小片段开始,逐步合并成更大的子词。但它和BPE的关键区别在于:
BPE更关注出现频率,WordPiece更关注合并后对语言模型概率的提升。
简单理解就是BPE会问:
哪两个片段最常一起出现?
WordPiece会问:
哪两个片段合并以后,更能提高语料的整体表示概率?
比如两个片段A和B,如果A和B各自出现很多,但它们并不是强绑定关系,那么WordPiece不一定优先合并它们。
WordPiece更倾向于合并那些经常一起出现,并且彼此关联很强的组合。例如:
playing可能会切成:
play /##ing
这里的##ing表示它不是一个独立开头的词,而是接在前面的子词后面。BERT、DistilBERT、ELECTRA 等模型中,常见tokenizer就是 WordPiece。
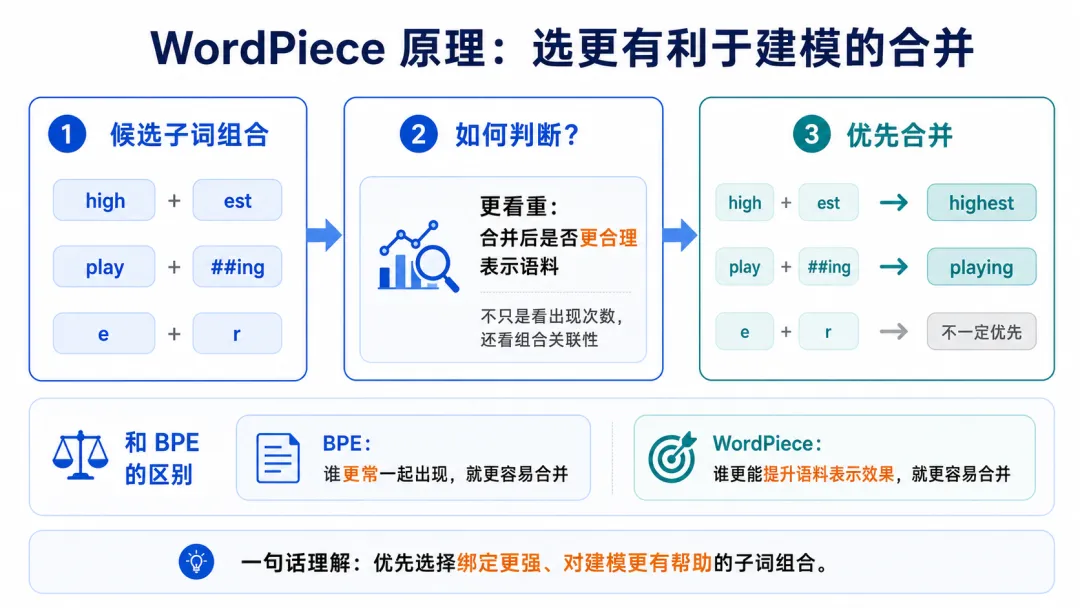
一句话理解WordPiece,它也是合并子词,但不是单纯看谁出现次数多,而是看合并后是否更有利于建模。
-
那么问题来了,啥叫更有利于建模?
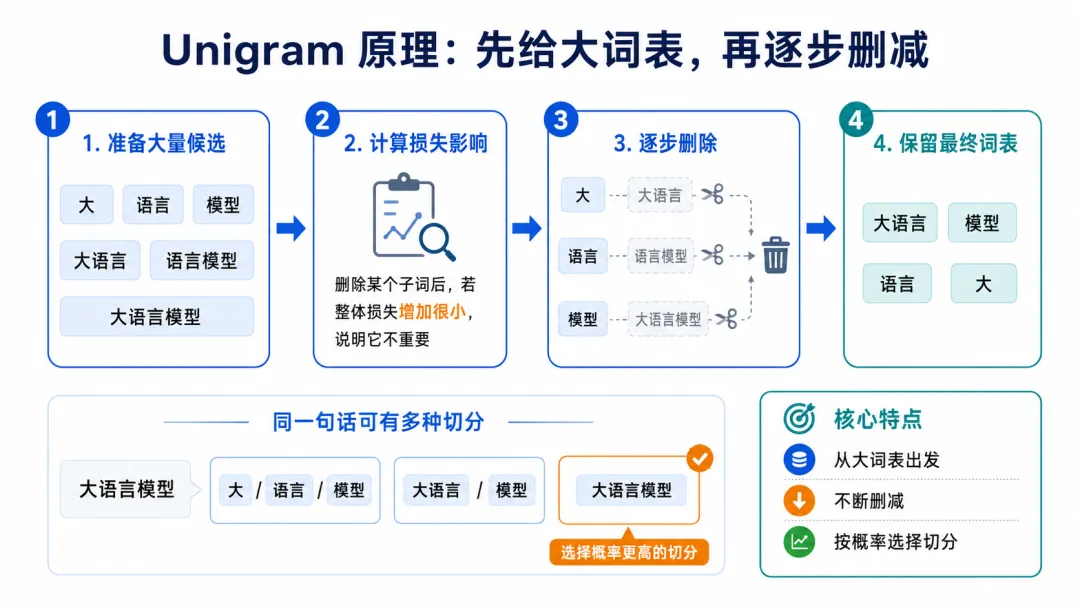
3、Unigram:先给很多候选,再逐步删掉不重要的
Unigram 的思路和BPE、WordPiece不太一样。BPE和WordPiece大体是从小到大,不断合并。而Unigram更像是先准备一个很大的候选词表,再慢慢删。比如一开始,它可能准备很多候选token:
大语言模型大语言语言模型大语言模型
然后根据概率模型判断哪些token更有用,哪些token删除后对整体损失影响较小。每次删除一批影响最小的token,最后保留一个大小合适的词表。
Unigram的特点是同一个句子可能有多种切分方式,模型会根据概率选择更合适的一种。比如:
大语言模型可能有几种切法:
大 / 语言 / 模型大语言 / 模型大语言模型
Unigram会根据训练得到的概率,选择更合理的切分。
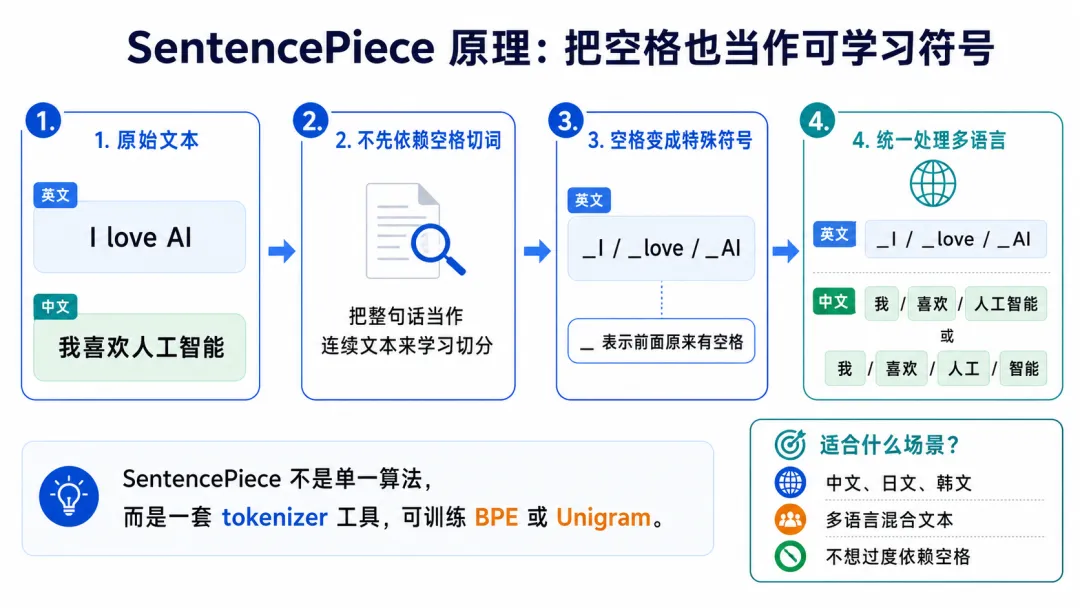
4、SentencePiece:不是单一算法,而是一套分词工具
SentencePiece容易被误解成一种具体的分词算法。更准确地说,它不是单独的一种算法,而是一套tokenizer训练工具。它可以用来训练BPE,也可以用来训练Unigram。它最大的特点是:
不需要先按空格把句子切成词,而是直接从原始文本中学习怎么切分。
这点对中文、日文、韩文等语言很重要。因为英文句子里通常有空格:
I love AI人和程序都很容易先切成:
I / love / AI但中文没有天然空格:
我喜欢人工智能如果分词器过度依赖空格,就很难同时处理英文、中文、日文等多种语言。SentencePiece的做法是把整句话看成一串字符,空格也不丢掉,而是用一个特殊符号表示。比如:
I love AI在 SentencePiece 里,空格可能会被表示成:
▁I / ▁love / ▁AI这里的
▁可以简单理解为:这个token前面原来有一个空格,或者它是一个新词/新片段的开始。
这样做有一个好处:即使文本被切成token,模型也还能知道原文中哪里有空格。所以,SentencePiece特别适合多语言场景。它不强依赖英文那样的空格分词,而是把空格、汉字、字母、标点都统一放进同一套切分体系里。一句话理解:
SentencePiece不是一种单独的切词规则,而是一套tokenizer工具。它把原始句子整体处理,连空格也一起建模,因此更适合中文、英文等多语言混合场景。
这几种方法有什么区别?
可以简单对比一下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
不过要注意一点:这些方法不是互相完全割裂的。实际模型中,tokenizer的实现常常会结合具体工程需求进行调整。
比如GPT系列常用byte-level BPE思路,SentencePiece也可以训练BPE 或Unigram类型的tokenizer。