 夜雨聆风
夜雨聆风





我把服务器密码给了 OpenClaw,10 分钟后一个 K8s 集群跑起来了
我盯着控制台里的两台 ECS 云服务器:4C4G、40G 硬盘、Ubuntu 22.04,这样的配置搭个一主一从的 K8s 集群勉强足够练手了。问题是我不想自己动手,我之前手动试过几次但都安装失败了…(╯_╰)
关 swap、装容器运行时、配 kubeadm、init、装 CNI、join worker……每一步我都干过,每一步都可能踩坑。想到要 SSH 进去敲一堆命令,再对着屏幕等进度条,我已经开始担心会在哪一步就踩坑里了。
我想到可以让 OpenClaw 来帮我干这个活。作为临时测试环境,我把两台服务器的 root 密码、公网和内网 IP都直接发给了它:
“帮我把这两台机器装成 1 主 1 从的 K8s 集群。”
“xxxxxxxx此处为服务器脱敏信息”
这里先说明一下,这两台机器不是生产服务器,只是个人临时测试环境,集群做完验证后都直接删除了。把 root 密码交给任何自动化系统都不是一个可以随意复制到生产环境的做法。
说实话,敲回车的时候我还是犹豫了一秒,因为这毕竟是 root 密码。
它没有回复“好的,以下是安装步骤……”然后丢给我一堆命令、代码让我自己复制粘贴,而是回复:
“先确认几个关键信息。Worker 节点的内网 IP 跟你刚说的不一致,我 SSH 进去看看实际是多少。”
等等,它已经自己 SSH 进去了?!这时候我也反应过来刚才复制的内网 IP 错了,一个低级的复制操作失误…
然后它又发来消息:
“两台都是 Ubuntu 22.04.5,内核 5.15,cgroup v2,4C/4G,无 swap,防火墙关闭。内网互 ping 延迟 0.2ms,同一个子网,没问题。”
“你偏好 kubeadm 还是 k3s?默认我按 kubeadm + containerd + Calico 来。”
它这干活太麻利了啊,开局先摸清环境再动手,还知道向我反问确认方案我回了句:
“用 kubeadm”
然后它就继续了。
它先是写了一个 Shell 安装脚本,然后同时 SCP 复制发送到两台机器上并行执行。
这里有个细节是它自动把镜像拉取地址换成了 registry.aliyuncs.com,它知道我这是阿里云 ECS 如果从 gcr.io 拉会卡到天荒地老。这种聪明的表现,让我觉得它更像是在基于环境感知做上下文判断,而非简单套模板。
几分多钟后,两台机器依赖全部装好——kubeadm、kubelet、kubectl、containerd,版本锁定,一个不落。
然后 kubeadm init,控制平面就绪、Calico 网络插件就绪、Master 节点 Ready……这也太顺了!
接着Worker 节点 join 集群之后,它回复:
“Worker 加入成功。验证集群状态。”
然后 kubectl get nodes 的结果弹出来,其中 worker 节点结果如下:
izj6cj6uwbplwaayrmpwcbz NotReady ...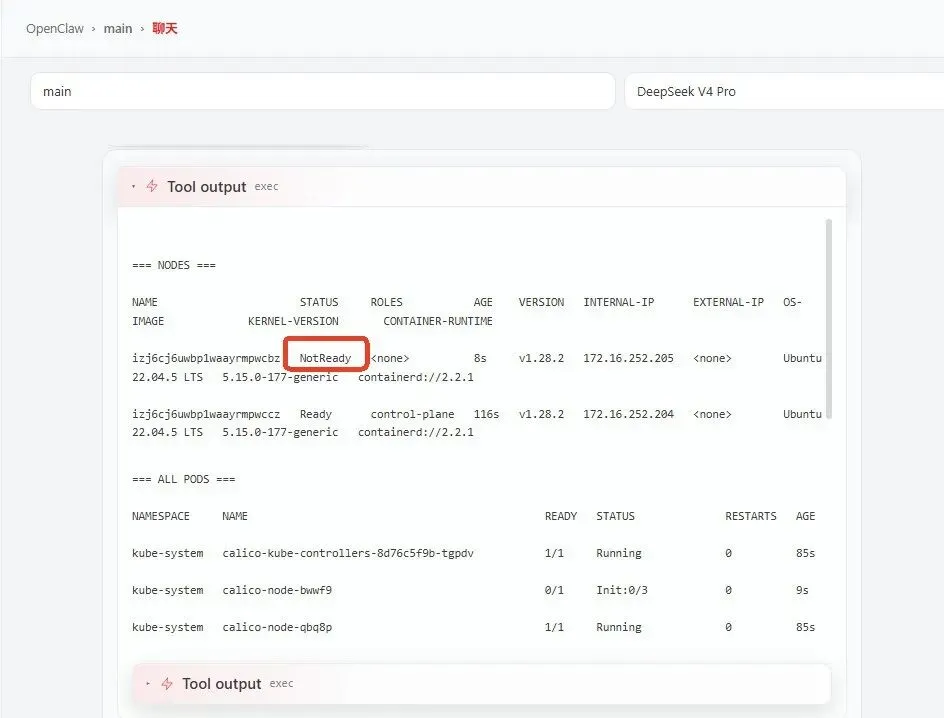
图:kubectl get node命令输出结果,woker节点NotReady
看到 “NotReady…” 的那一刻,我心头一紧:果然,太顺了就要翻车吗?我就知道事情没那么简单啊。端口不通?证书错误?还是 CNI 冲突?问题到底在哪里?排错时间到了。
但 OpenClaw 立马接的一句回复让我转忧为喜,刚才的担心都多余了:
“Worker 正在初始化 Calico 和 kube-proxy,等几秒就好。”
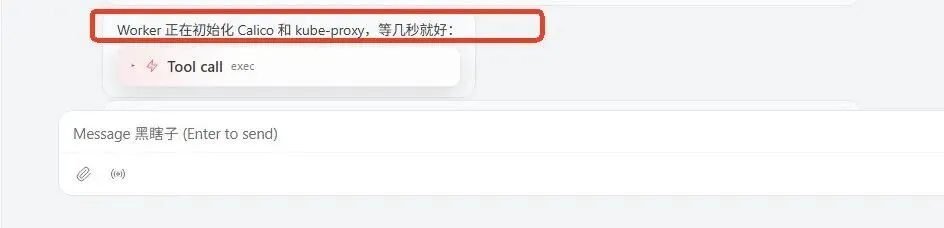
图:说明worker节点当前状态是正常的
它没有把这个当成一个问题,也知道这是正常现象,这只是正常流程还没有跑完。
果然,等一会儿后 worker 节点正常了:
izj6cj6uwbplwaayrmpwcbz Ready ...它还没结束。自动跑了一个 nginx 进行测试,确认调度到了 Worker 节点、拿到了分配的 Pod IP(192.168.221.129),端到端验证通过。这个过程里我一个字没敲,它把验收都做完了。
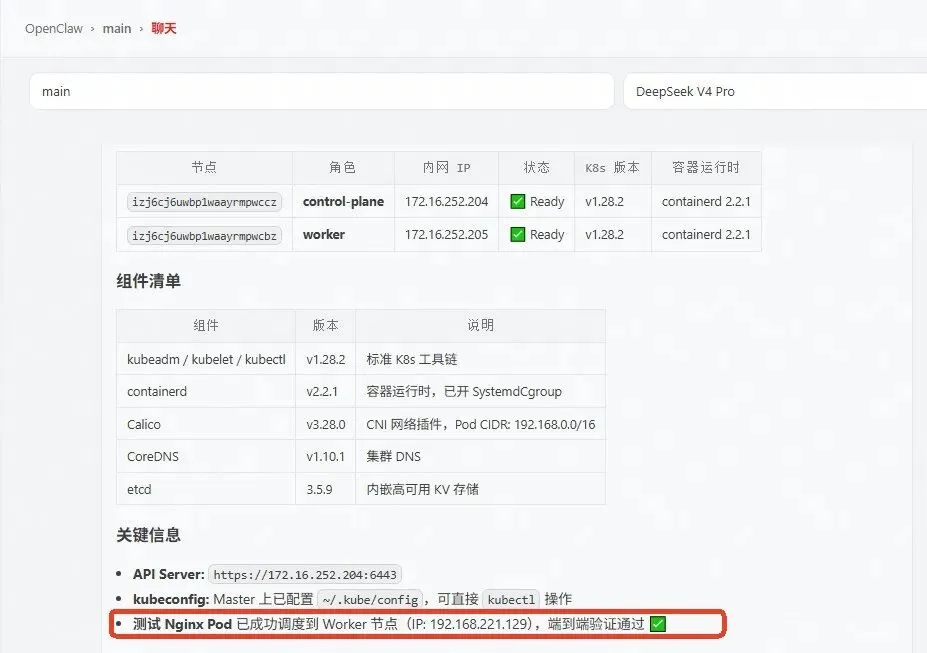
图:自动完成端到端验证
黑屏终端看到工作负载都正常运行了,终端查看总有些不习惯,于是我说:
“我想在 web 页面查看。”
它立马给我装了 Kubernetes Dashboard 用于 web 页面访问。部署 Dashboard、创建 cluster-admin 账号、改 NodePort 暴露到 30443、生成 10 年有效期的登录 Token,又一次一气呵成。
装完后它还从自己这边 curl 公网 IP 测试连通性,结果返回失败。这次它没有说“等几秒就好”而是立即判断:
“内网 200 OK,Worker 到 Master 也通,问题确认是阿里云安全组没开放 30443 端口。”
“你去安全组加一条入规则:TCP 30443,授权对象先填全部IP。加好了告诉我。”
我加了规则并告诉它加好了,它三秒后回复:HTTP 200 ✅。
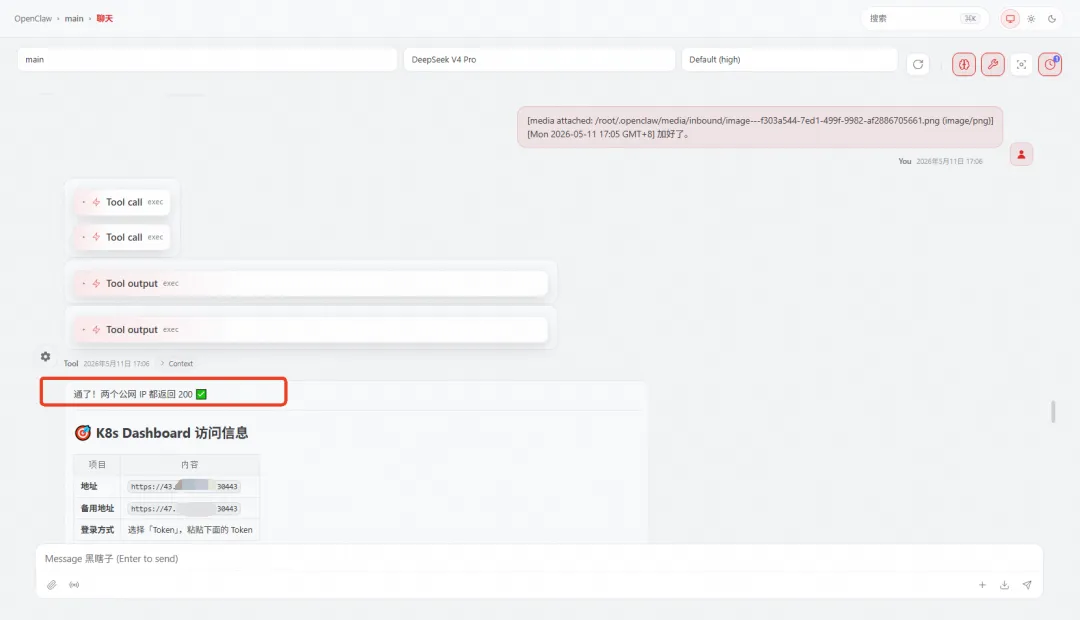
图:改安全组规则后,成功通过公网访问web页面
这个排查路径:内网自测 → 跨节点测试 → 排除服务故障 → 定位到安全组 → 给我精确的修复指令,一个运维人员可能要十几分钟才能走完,它用了不到两分钟。
最后我在本地浏览器访问这个 k8s 集群,看着这个集群里的一个个资源在 web 页面上展示,兴奋过后有些沉默了。
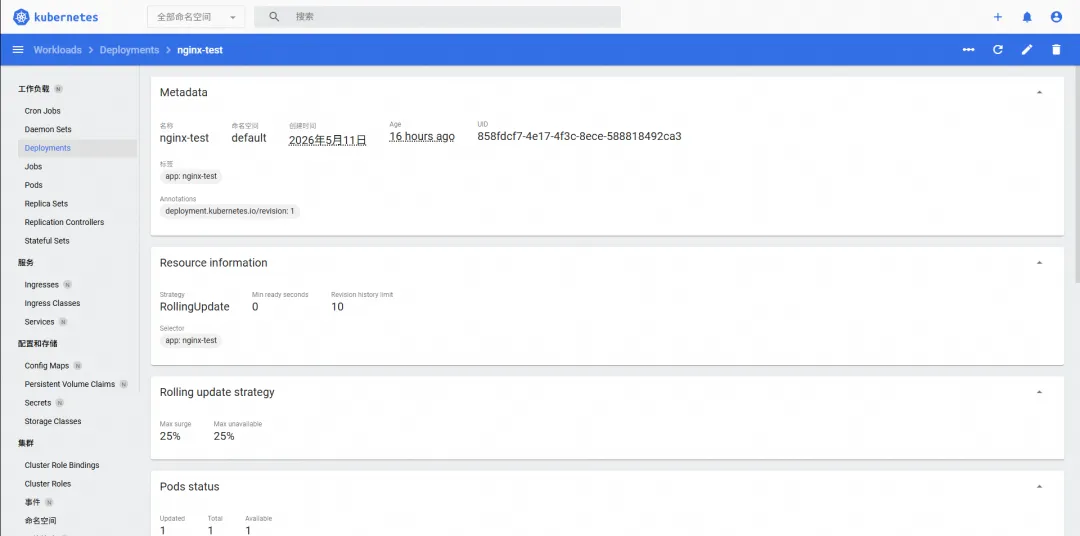
图:本地浏览器访问集群web页面
从下表可以很直观地看到, 在这次目标明确、环境干净的测试里,OpenClaw 的执行时间明显短于手动操作。运维人员中间还要查文档、搜报错、喝杯水压压惊。OpenClaw 不需要这些中断,直接把流程跑完了。
|
环节 |
手动操作 |
OpenClaw |
|
环境检查 |
~15 分钟 |
~1 分钟 |
|
装依赖 |
~20 分钟 |
~2 分钟 |
|
集群初始化 + CNI |
~15 分钟 |
~3 分钟 |
|
Worker join + 排错 |
~10 分钟 |
~2 分钟 |
|
Dashboard + 公网暴露 |
~15 分钟 |
~2 分钟 |
|
总计 |
~1.5 小时 |
~10 分钟 |
不仅仅是快,让我在电脑前面沉默了十几秒的是 OpenClaw 真的把事情做完了。而且就像我前面提到的,这件事情之前我手动尝试过两三次了都没成功。
说明:
上表时间基于个人经验和临时测试环境对话记录估算,不代表所有环境。
需要强调的是,把 root 密码交给任何自动化系统都不是一个可以随意在生产环境中执行的操作。更合理的方式是使用临时账号、最小权限、短期凭证、堡垒机审计,或者只在隔离测试环境中验证能力。
我只是做了个实验:把一件我之前一直想做但没做成、知道很繁琐有难度的工作,完全交给一个 AI 去做。
最后统计整个过程花了约 10 分钟,期间我没有手动执行任何命令,也没有介入排错。
这件事让我触动的地方是它开始具备一种过去工具很少具备的能力:在一个明确边界内,理解目标、感知环境、接管执行,并对任务结果负责到最后一步。这还是一个我自己动手没能完成的任务 (^_^)
我建议你也做一次类似的实验,但最好从隔离测试环境和低风险任务开始。找一件你熟悉、繁琐、容易出错、但边界清楚的脏活累活,让 OpenClaw 完整跑一遍。你可能会和我一样,在某个它自己完成排查和验收的瞬间突然意识到:它不只是会回答问题,它已经开始能接手一部分真实工作了。
实操环境说明:
两台用于临时测试的阿里云 ECS(4C4G、40G)云服务器,位于中国香港可用区 D,10M 固定带宽,操作系统 Ubuntu 22.04;(按需付费的 ECS 用来搞测试真的很香,这个配置的 ECS 一小时一元左右,用完了还可以马上删除没后续负担)
AI 助手 OpenClaw (连接 deepseek-v4-pro 模型),版本 v2026.5.4;
为了简化一些环境配置,OpenClaw与两台ECS处于同一个VPC网络中。
END
(如果这篇文章对您有所帮助,请帮忙 关注 并 转发,谢谢!)