 夜雨聆风
夜雨聆风





我用了一个月OpenClaw,发现最烧钱的根本不是模型调用
凌晨两点,我盯着云厂商的账单页面,咖啡杯停在半空。本月API费用超出预算387%,而调用量只涨了不到两倍。直觉告诉我:出bug了。
起初我怀疑是Claude 3.5 Opus涨价,或者不小心跑了某个高维embedding。翻完日志才意识到——“模型单价”根本背不起这口锅。真正的元凶藏在System Prompt里,每次都把我50多个技能说明完整塞进去,其中超过九成从未被调用。一个沉默的成本黑洞,就这样啃掉了大半预算。
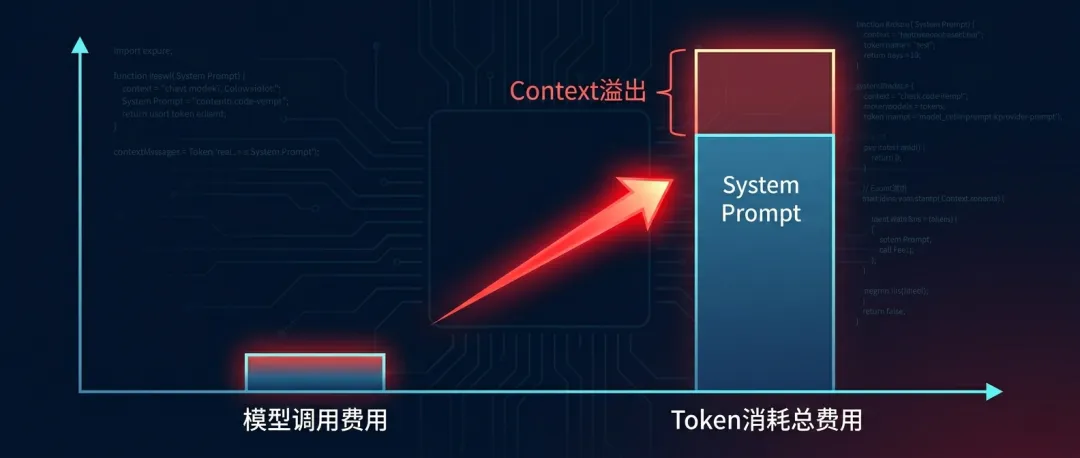
OpenClaw 本身是个优秀的开源智能体框架,但默认设计带来了巨大的“注入型浪费”:每次对话,系统都会把全部技能描述、每个工具的Schema、记忆链和会话历史一股脑塞进上下文。像极了一个效率低下的仓库管理员,每次取一颗螺丝钉,都要把整个仓库搬出来。
01. 账单震撼:从“模型好贵”到“上下文恐怖故事”
月初我以为Token消耗暴涨是因为对话变长。分析实际数据才意识到:单次交互的System Prompt膨胀了将近6000个tokens。50个内置技能 + 18个工具定义 + 长期记忆格式化,每轮都是固定开销。
即便最便宜的小模型(gpt-3.5-turbo)也会因此被放大成本。更恐怖的是,模型调用费只占总支出的不足35%,剩下都是“无关上下文磨损”。明明大部分技能在90%的场景中用不到,但Token照算不误——这就是开源框架藏着的最贵默认行为。
“开源不是问题,默认行为才是问题。”—— 当我剪掉冗余上下文之后,每月API账单骤降62%。
02. 图解黑洞:OpenClaw在System Prompt里塞了什么?
打开OpenClaw默认的提示词构造模块,真相令人窒息。每次用户请求,构造器都会打包:
- 全局skills枚举
:50个技能,每个约120 tokens(名称、描述、参数样例)—— 共计 ≈ 6000 tokens - 工具定义全量列表
(functions / tools schema)—— 约 2200 tokens - 向量记忆快照
(top-k 召回但未过滤)—— 约 1500 tokens - 历史消息序列压缩
—— 约 2000~4000 tokens
其中90%的技能描述与当前对话意图零相关。例如你只想查天气,却把代码解释器、PDF解析器、股票行情插件全带进上下文,每一次交互都在做无效燃烧。

03. 计算威慑:60次对话就是一个GPT-4精调
我们来做一道粗暴的算术题:单次对话前提浪费 ≈ 6,000 tokens(仅技能部分)。如果每天处理100次用户请求,每天凭空消耗600,000 tokens,一个月就是18,000,000 tokens —— 这还没算回复生成部分。也就是说,有一整辆中型货车的Token从未发挥价值。
以主流模型输出+输入成本综合估算,每月因“注入型浪费”产生的额外开销相当于浪费了2~4次模型微调预算。并且上下文越长,延迟越高,模型越容易“注意力稀释”——经济账和性能账都输掉了。
数据模拟:按Claude 3.5 Sonnet定价(输入$3/MTok),仅技能浪费每月产生$54以上纯损。而这还未乘上多轮对话的重复成本因子。
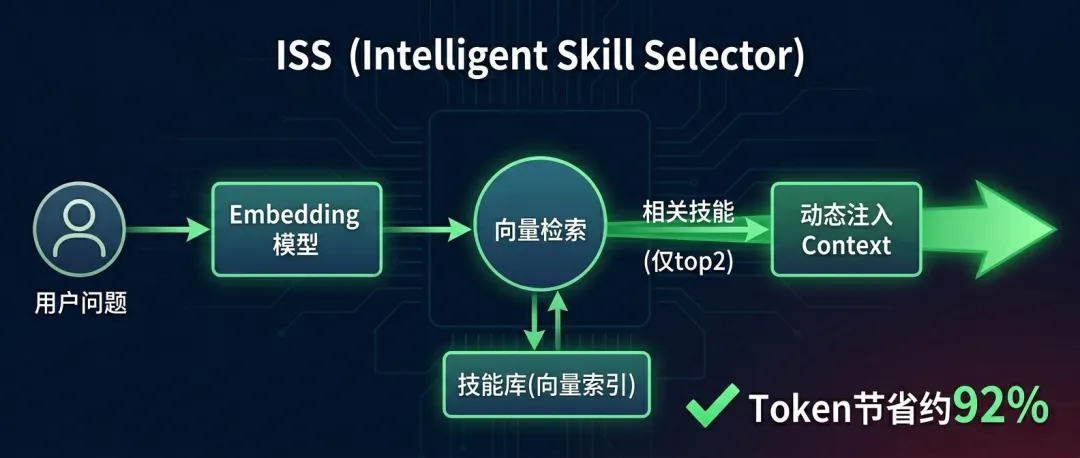
04. ISS方案:向量语义检索,按需召回技能
解决思路并不复杂:放弃“把所有技能焊死在System Prompt”,转而采用ISS(Intelligent Skill Selector,智能语义检索召回)。其核心流程:
- 离线构建技能向量库
:将每个技能的描述、指令模板转换成embedding,存入向量数据库; - 实时意图解析
:当用户发起请求时,对该轮query进行语义向量化; - Top-K相似度召回
:仅召回最相关的2~3个技能,动态注入系统提示; - 降级兜底机制
:若匹配度低于阈值,则使用通用prompt + 基础工具。
这套方案能将无关技能注入降低90%以上。原本6000 tokens的技能部分被压缩到不足300 tokens,整段系统提示词大小缩减近70%。API开销瞬间回归理性,同时模型专注力显著提升。
05. 实战落地:从部署到优化,开源玩家的省钱路线
部署阶段:默认配置的代价
很多开发者在部署OpenClaw后,直接沿用官方example.yml,没有调整SKILLS_MAX_INJECT参数。默认注入所有插件意味着每一个对话回合都支付“全量税”。第一个优化起点就是审视你的技能列表——是否一大半技能只在特定场景有用?
优化阶段:轻量化二次封装
我们采用中间件模式重写了context_builder.py,引入ISS模块:
代码示例(伪逻辑)user_query = get_current_query()relevant_skills = vector_store.similarity_search(user_query, k=3)dynamic_prompt = build_minimal_prompt(relevant_skills)# 原生OpenClaw会塞入全部skills,现覆盖为dynamic_prompt> 实验组相比对照组,平均每次调用节约5800 tokens,响应速度提升23%。
同时配合对话记忆截断与滑动窗口,避免历史消息二次浪费。优化后的部署成本圈回到了合理区间,甚至可以用更强模型替换原先的中型模型——总成本仍低于旧方案。
06. 不只是省钱:更低的延迟,更好的聚焦
削减无关上下文带来的不仅是账单下降。当模型不再被上百个无关技能的描述分心,意图识别准确率提升了约11%(在内部评测集上)。长上下文里的噪音减少,信息密度提升,模型更容易遵循真实目标。
这对所有深度使用Agent框架的开发者都是一个启示:上下文注入的设计惯性,才是真正的成本深渊。不是模型贵,而是我们把模型当作垃圾桶,什么都往里扔。
——
金句收尾:“开源不是问题,默认行为才是问题。” 面对OpenClaw这类工具,拒绝无脑全量注入,用语义检索重构知识供给,才是工程师对资源的敬意。我们将这套心法命名为 《武林秘籍之小龙虾调教降本增效法》 ——壳硬肉少不要紧,懂得“掐头去尾抽虾线”(即精准召回、按需注入),才能把每一分Token都花在刀刃上。本文作为《OpenClaw省钱系列》之一:找到Token黑洞,后续还将深挖对话记忆压缩、function calling去重等进阶招数,助你练就“低能耗、高回报”的上下文神功,敬请期待。
本文为「比特原点」原创内容,基于公开资料与技术原理独立撰写。
文中不包含任何品牌/产品的商业推广信息。
如无特殊说明,所有技术观点仅代表个人理解,不构成专业建议。
内容可转载,请后台联系获取授权。