 夜雨聆风
夜雨聆风





我把公司300份文档喂给AI,它成了比老员工还懂业务的专家:RAG技术 + DeepSeek + 向量数据库,让AI基于你自己的精准回答问题
图:把你的所有文档变成一个能回答任何问题的AI
————————————————————————————————
上个月,公司来了个新人。
入职第一天,主管丢给他一个共享文件夹——里面有300多份文档:产品手册、技术规范、客户案例、历史合同、会议纪要、培训资料……
「先把这些看完。」主管说。
新人花了整整两周,才勉强看完一半。遇到具体问题时,还是得去问老员工。
后来我帮他搭了一个AI私有知识库。
把那300份文档全部喂进去之后,AI能秒级检索任何一份文档的内容,精准回答业务问题,甚至能告诉你答案出自哪份文档的第几页。
新人再也不用翻文档了,问AI就行。老员工也省去了大量重复答疑的时间。
这篇文章,我把整个搭建过程从零开始手把手教给你。
【项目概览】
|
项目信息 |
详情 |
|
项目名称 |
AI私有知识库(RAG系统) |
|
核心功能 |
上传文档→自动切分→向量化→语义检索→AI精准回答+来源引用 |
|
使用工具 |
DeepSeek V4 + LangChain + ChromaDB + BGE向量模型 |
|
开发周期 |
1个周末(约14小时) |
|
使用成本 |
DeepSeek API每月约10-20元,本地部署零成本 |
|
编程要求 |
Python基础即可,代码可直接复制运行 |
|
适合人群 |
知识管理者、企业培训、技术文档管理、客服团队 |
表:项目基本信息
一、RAG是什么?为什么它比直接问AI强100倍
你可能有疑问:直接把文档内容复制粘贴给ChatGPT不就行了?
不行。原因有三个:
▸ 上下文限制:ChatGPT最多接收几万字,300份文档远超限制
▸ 回答不准:没有原文对照,AI容易「幻觉」编造内容
▸ 无法溯源:你不知道AI的回答来自哪份文档,无法验证
RAG(Retrieval-Augmented Generation,检索增强生成)完美解决了这三个问题。
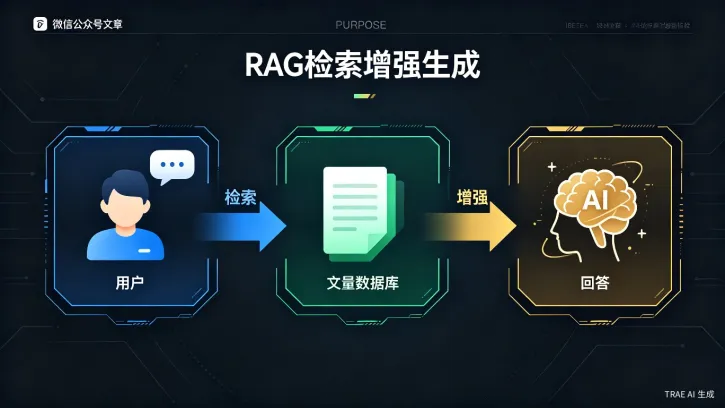
图:RAG检索增强生成的三步流程
【RAG工作原理,三步说清楚】
第一步:检索(Retrieval)
你提问「产品A的退货政策是什么?」,系统不是把所有文档都塞给AI,而是先从知识库中「检索」出与退货政策最相关的3-5个文档片段。
第二步:增强(Augmented)
把检索到的文档片段和你的问题一起,组装成一段完整的Prompt,发送给AI。
AI看到的是:「根据以下文档内容回答问题——[文档片段1][文档片段2][文档片段3]——用户问题:产品A的退货政策是什么?」
第三步:生成(Generation)
AI基于你提供的真实文档内容生成回答,并标注信息来源。
因为AI看到的是真实文档,不是凭空想象,所以回答准确、可溯源、无幻觉。
【RAG vs 直接问AI 对比】
|
对比维度 |
直接问AI |
RAG知识库 |
|
准确性 |
容易编造内容(幻觉) |
基于真实文档,准确率高 |
|
可溯源 |
无法知道答案来源 |
标注出处文档和页码 |
|
文档容量 |
受上下文窗口限制 |
可处理数万份文档 |
|
更新维护 |
无法更新知识 |
新增文档即可更新 |
|
隐私安全 |
数据上传到云端 |
可完全本地部署 |
|
响应速度 |
长文档时较慢 |
秒级响应 |
表:RAG vs 直接问AI对比
二、环境准备:30分钟搞定
搭建之前,需要准备Python环境和几个核心库。
步骤1:安装Python(3.10-3.12)
访问 python.org/downloads,下载对应系统的安装包。
安装时务必勾选「Add Python to PATH」。
验证安装:打开终端,输入:
|
1 |
python –version |
|
2 |
# 应显示 Python 3.10.x 或更高版本 |
步骤2:安装核心依赖库
打开终端,复制以下命令运行(建议使用虚拟环境):
|
1 |
# 创建虚拟环境(推荐) |
|
2 |
python -m venv rag_env |
|
3 |
|
|
4 |
# 激活虚拟环境 |
|
5 |
# Windows: |
|
6 |
rag_env\Scripts\activate |
|
7 |
# Mac/Linux: |
|
8 |
source rag_env/bin/activate |
|
9 |
|
|
10 |
# 安装核心依赖 |
|
11 |
pip install langchain langchain-community langchain-text-splitters |
|
12 |
pip install chromadb sentence-transformers |
|
13 |
pip install openai pypdf python-docx |
|
14 |
pip install unstructured |
这几个库的作用:
▸ langchain:RAG框架,串联检索、增强、生成全流程
▸ chromadb:向量数据库,存储文档的向量表示
▸ sentence-transformers:中文向量模型,把文本转成AI能理解的数字
▸ openai:调用DeepSeek API(兼容OpenAI接口)
▸ pypdf / python-docx:解析PDF和Word文档
▸ unstructured:解析各种格式文档(PPT、HTML等)
步骤3:获取DeepSeek API Key
打开 platform.deepseek.com,注册并完成实名认证。
进入「API Keys」页面,点击「创建 API Key」,复制保存。
2026年6月最新价格:DeepSeek V4 Pro自5月31日起永久降价75%,每月成本约10-20元。
如果想完全免费,可以用Ollama本地部署DeepSeek,零API成本。
三、核心搭建:六步完成知识库

图:知识库搭建的六个步骤
步骤1:准备文档
把你要导入知识库的文档放到一个文件夹里。支持的格式:
▸ PDF(产品手册、技术文档、合同)
▸ Word/DOCX(培训资料、会议纪要)
▸ TXT/Markdown(笔记、知识沉淀)
▸ Excel/CSV(数据表格)
▸ PPT/PPTX(演示文稿)
【文档准备技巧】
▸ 文件命名规范:YYYYMMDD_类型_领域_主题(如 20260615_手册_产品_A功能说明.pdf)
▸ 删除无用的封面、目录页、空白页
▸ 确保文档内容可选中(扫描件需要先OCR)
▸ 单份文档建议不超过50页,太长会影响检索精度
步骤2:文档加载与解析
|
1 |
from langchain_community.document_loaders import ( |
|
2 |
PyPDFLoader, |
|
3 |
Docx2txtLoader, |
|
4 |
TextLoader, |
|
5 |
UnstructuredPowerPointLoader, |
|
6 |
) |
|
7 |
import os |
|
8 |
|
|
9 |
def load_documents(folder_path: str): |
|
10 |
“””加载文件夹中的所有文档“”” |
|
11 |
documents = [] |
|
12 |
for filename in os.listdir(folder_path): |
|
13 |
filepath = os.path.join(folder_path, filename) |
|
14 |
|
|
15 |
if filename.endswith(‘.pdf’): |
|
16 |
loader = PyPDFLoader(filepath) |
|
17 |
elif filename.endswith(‘.docx’): |
|
18 |
loader = Docx2txtLoader(filepath) |
|
19 |
elif filename.endswith(‘.txt’) or filename.endswith(‘.md’): |
|
20 |
loader = TextLoader(filepath) |
|
21 |
elif filename.endswith(‘.pptx’): |
|
22 |
loader = UnstructuredPowerPointLoader(filepath) |
|
23 |
else: |
|
24 |
continue |
|
25 |
|
|
26 |
docs = loader.load() |
|
27 |
# 给每个文档添加来源标记 |
|
28 |
for doc in docs: |
|
29 |
doc.metadata[‘source’] = filename |
|
30 |
documents.extend(docs) |
|
31 |
|
|
32 |
print(f”共加载 {len(documents)} 个文档片段“) |
|
33 |
return documents |
步骤3:文档切分(关键步骤)
文档太长不能直接存入向量数据库,需要切分成小块。切分方式直接影响检索质量。
|
1 |
from langchain_text_splitters import RecursiveCharacterTextSplitter |
|
2 |
|
|
3 |
def split_documents(documents): |
|
4 |
“””将文档切分成适合检索的小块“”” |
|
5 |
splitter = RecursiveCharacterTextSplitter( |
|
6 |
chunk_size=500, # 每块最大500字符 |
|
7 |
chunk_overlap=100, # 块之间重叠100字符 |
|
8 |
separators=[“\n\n”, “\n”, “。“, “!“, “?“, “;“, ” “] |
|
9 |
) |
|
10 |
chunks = splitter.split_documents(documents) |
|
11 |
print(f”切分为 {len(chunks)} 个知识块“) |
|
12 |
return chunks |
【切分参数说明】
▸ chunk_size=500:每块500字符,约200-300个中文字。太小会丢失上下文,太大会降低检索精度
▸ chunk_overlap=100:块之间重叠100字符,确保不会在句子中间断裂
▸ separators:优先在段落、句子处切分,保持语义完整
步骤4:向量化与存储
把文字转成AI能理解的「向量」(一串数字),存入向量数据库。
|
1 |
from langchain_community.embeddings import HuggingFaceEmbeddings |
|
2 |
from langchain_community.vectorstores import Chroma |
|
3 |
|
|
4 |
def build_vector_store(chunks, persist_dir=”./chroma_db”): |
|
5 |
“””将知识块向量化并存储“”” |
|
6 |
# 使用中文向量模型 |
|
7 |
embedding = HuggingFaceEmbeddings( |
|
8 |
model_name=”BAAI/bge-small-zh-v1.5″ |
|
9 |
) |
|
10 |
|
|
11 |
# 构建向量数据库 |
|
12 |
vectorstore = Chroma.from_documents( |
|
13 |
documents=chunks, |
|
14 |
embedding=embedding, |
|
15 |
persist_directory=persist_dir |
|
16 |
) |
|
17 |
|
|
18 |
print(f”向量数据库已构建,共 {len(chunks)} 条记录“) |
|
19 |
return vectorstore |
【关于向量模型】
▸ BAAI/bge-small-zh-v1.5:北京智源研究院开源的中文向量模型,首次使用会自动下载(约100MB)
▸ ChromaDB:轻量级向量数据库,数据存储在本地文件夹,无需安装额外服务
▸ 向量化只需执行一次,后续新增文档增量更新即可
步骤5:构建RAG问答链
这是整个系统的核心——把检索和生成串联起来。
|
1 |
from langchain_community.llms import OpenAI |
|
2 |
from langchain.chains import RetrievalQA |
|
3 |
from langchain.prompts import PromptTemplate |
|
4 |
|
|
5 |
# RAG专用Prompt模板 |
|
6 |
RAG_PROMPT = PromptTemplate( |
|
7 |
template=”””你是一个专业的知识库助手。请根据以下文档内容回答用户问题。 |
|
8 |
如果文档中没有相关信息,请明确说明「知识库中未找到相关信息」,不要编造。 |
|
9 |
回答时请标注信息来源。 |
|
10 |
|
|
11 |
相关文档内容: |
|
12 |
{context} |
|
13 |
|
|
14 |
用户问题:{question} |
|
15 |
|
|
16 |
回答格式: |
|
17 |
1. 直接回答问题 |
|
18 |
2. 标注来源:[文档名称] |
|
19 |
“”” |
|
20 |
input_variables=[“context”, “question”] |
|
21 |
) |
|
22 |
|
|
23 |
def create_rag_chain(vectorstore, api_key: str): |
|
24 |
“””创建RAG问答链“”” |
|
25 |
# 配置DeepSeek作为生成模型 |
|
26 |
llm = OpenAI( |
|
27 |
model=”deepseek-chat”, |
|
28 |
openai_api_key=api_key, |
|
29 |
openai_api_base=”https://api.deepseek.com”, |
|
30 |
temperature=0.1, # 低温度,减少幻觉 |
|
31 |
) |
|
32 |
|
|
33 |
# 创建检索器(每次检索最相关的5个片段) |
|
34 |
retriever = vectorstore.as_retriever( |
|
35 |
search_kwargs={“k”: 5} |
|
36 |
) |
|
37 |
|
|
38 |
# 构建RAG链 |
|
39 |
qa_chain = RetrievalQA.from_chain_type( |
|
40 |
llm=llm, |
|
41 |
chain_type=”stuff”, |
|
42 |
retriever=retriever, |
|
43 |
chain_type_kwargs={“prompt”: RAG_PROMPT}, |
|
44 |
return_source_documents=True |
|
45 |
) |
|
46 |
return qa_chain |
步骤6:运行问答
|
1 |
# 初始化RAG系统 |
|
2 |
api_key = “your-deepseek-api-key” |
|
3 |
|
|
4 |
# 加载已有向量数据库(无需重新构建) |
|
5 |
embedding = HuggingFaceEmbeddings( |
|
6 |
model_name=”BAAI/bge-small-zh-v1.5″ |
|
7 |
) |
|
8 |
vectorstore = Chroma( |
|
9 |
persist_directory=”./chroma_db”, |
|
10 |
embedding_function=embedding |
|
11 |
) |
|
12 |
|
|
13 |
# 创建问答链 |
|
14 |
qa_chain = create_rag_chain(vectorstore, api_key) |
|
15 |
|
|
16 |
# 开始提问 |
|
17 |
question = “产品A的退货政策是什么?“ |
|
18 |
result = qa_chain({“query”: question}) |
|
19 |
|
|
20 |
# 输出结果 |
|
21 |
print(“回答:“, result[“result”]) |
|
22 |
print(“\n来源文档:“) |
|
23 |
for doc in result[“source_documents”]: |
|
24 |
print(f” – {doc.metadata[‘source’]} (相似度: {doc.metadata.get(‘score’, ‘N/A’)})”) |
四、实战效果:四个真实问答场景

图:AI知识库在实际工作中的四个应用场景
场景一:新人入职培训
提问:「公司年假制度是怎样的?入职第一年有几天?」
AI回答:
根据《员工手册2026版》第三章第12条:
▸ 入职第一年:年假5天
▸ 入职满1年不满10年:年假10天
▸ 入职满10年不满20年:年假15天
▸ 入职满20年以上:年假20天
年假不可跨年累积,需在当年12月31日前使用完毕。
来源:员工手册2026版.pdf
场景二:技术问题排查
提问:「产品B的API接口超时怎么处理?」
AI回答:
根据《产品B技术文档v3.2》第7章故障排查:
▸ 检查网络连接:确认服务器可达,ping延迟低于100ms
▸ 调整超时参数:在配置文件中将timeout从30s调整为60s
▸ 启用重试机制:设置max_retries=3,backoff_factor=2
▸ 如仍超时:联系技术支持,提供request_id和日志截图
来源:产品B技术文档v3.2.pdf
场景三:客户咨询响应
提问:「客户问我们有没有ISO认证,怎么回答?」
AI回答:
根据《公司资质清单2026》:
▸ ISO 9001质量管理体系认证:已通过,有效期至2027年3月
▸ ISO 27001信息安全认证:已通过,有效期至2026年12月
▸ ISO 27701隐私信息管理认证:已通过,有效期至2027年6月
认证证书电子版存放在共享盘/公司资质/ISO证书/目录下。
来源:公司资质清单2026.xlsx、ISO证书扫描件.pdf
场景四:历史决策追溯
提问:「去年Q2为什么放弃了X项目?」
AI回答:
根据《2025年Q2项目评审会议纪要》:
X项目于2025年6月正式终止,原因包括:
▸ 市场调研显示目标市场规模不足预期(实际规模为预估的35%)
▸ 竞品已占据80%市场份额,进入壁垒过高
▸ ROI测算为-23%,不符合公司投资回报标准
来源:2025年Q2项目评审会议纪要.docx
五、进阶优化:让知识库越来越好用
优化一:混合检索(语义+关键词)
纯语义检索有时候会遗漏精确匹配的内容。混合检索同时使用语义相似度和关键词匹配,效果更好。
|
1 |
# ChromaDB支持混合检索 |
|
2 |
retriever = vectorstore.as_retriever( |
|
3 |
search_type=”mmr”, # 最大边际相关性 |
|
4 |
search_kwargs={“k”: 5, “fetch_k”: 10} |
|
5 |
) |
优化二:多轮对话记忆
默认情况下,每次提问都是独立的。开启对话记忆后,AI能记住上下文。
|
1 |
from langchain.chains import ConversationalRetrievalChain |
|
2 |
from langchain.memory import ConversationBufferMemory |
|
3 |
|
|
4 |
memory = ConversationBufferMemory( |
|
5 |
memory_key=”chat_history”, |
|
6 |
return_messages=True |
|
7 |
) |
|
8 |
|
|
9 |
qa_chain = ConversationalRetrievalChain.from_llm( |
|
10 |
llm=llm, |
|
11 |
retriever=retriever, |
|
12 |
memory=memory |
|
13 |
) |
|
14 |
|
|
15 |
# 多轮对话 |
|
16 |
result1 = qa_chain({“question”: “产品A的定价是多少?“}) |
|
17 |
result2 = qa_chain({“question”: “那产品B呢?“}) # AI知道你在问定价 |
优化三:自动新增文档
知识库搭建好后,新增文档不需要从头来。只需增量更新:
|
1 |
def add_new_documents(vectorstore, new_folder: str): |
|
2 |
“””增量添加新文档“”” |
|
3 |
# 加载新文档 |
|
4 |
new_docs = load_documents(new_folder) |
|
5 |
# 切分 |
|
6 |
new_chunks = split_documents(new_docs) |
|
7 |
# 增量添加到向量数据库 |
|
8 |
vectorstore.add_documents(new_chunks) |
|
9 |
print(f”已新增 {len(new_chunks)} 个知识块“) |
优化四:搭建Web界面
用Streamlit快速搭建一个网页问答界面,5分钟搞定:
|
1 |
import streamlit as st |
|
2 |
|
|
3 |
st.title(“AI私有知识库“) |
|
4 |
st.caption(“基于RAG技术,支持PDF/Word/PPT等格式“) |
|
5 |
|
|
6 |
# 用户输入 |
|
7 |
question = st.text_input(“请输入你的问题:“) |
|
8 |
|
|
9 |
if st.button(“提问“) and question: |
|
10 |
with st.spinner(“正在检索和生成回答…”): |
|
11 |
result = qa_chain({“query”: question}) |
|
12 |
st.success(“回答生成完成!“) |
|
13 |
st.write(“**回答:**”, result[“result”]) |
|
14 |
st.write(“**来源文档:**”) |
|
15 |
for doc in result[“source_documents”]: |
|
16 |
st.write(f” – {doc.metadata[‘source’]}”) |
运行命令:streamlit run app.py,浏览器自动打开问答界面。
六、避坑指南:我踩过的6个坑
|
坑 |
问题描述 |
解决方案 |
|
坑1:切分太大 |
检索结果不精准,AI回答跑题 |
chunk_size设为300-500,chunk_overlap设为50-100 |
|
坑2:中文模型选错 |
用英文向量模型处理中文,效果很差 |
必须用中文向量模型(bge-small-zh-v1.5) |
|
坑3:扫描件PDF |
PDF是图片格式,无法提取文字 |
先用OCR工具转成可选中文字的PDF,或用unstructured的hi_res策略 |
|
坑4:检索结果太少 |
AI回答不完整,遗漏关键信息 |
增大k值到8-10,或使用MMR混合检索 |
|
坑5:回答太啰嗦 |
AI输出一大段,找不到重点 |
在Prompt中明确要求「回答不超过200字,分点列出」 |
|
坑6:首次加载慢 |
向量模型首次下载需要几分钟 |
首次运行后模型会缓存到本地,后续秒级加载 |
表:6个常见坑及解决方案
写在最后
这个知识库搭好后,我最大的感受是:找信息这件事,终于不需要「人」来做了。
以前新人入职,老员工要花大量时间答疑。现在问AI就行,回答精准、有来源、秒级响应。
以前写方案,要翻半天历史文档找参考。现在一句话就能检索到所有相关案例。
以前客户问了个冷门问题,要翻好几份文档才能回答。现在AI直接给出答案和出处。
RAG技术不新,但2026年DeepSeek降价75%后,搭建成本已经低到几乎为零。
真正稀缺的,不是技术,是愿意花一个周末把知识库搭起来的人。
300份文档,一个周末,一个能回答任何业务问题的AI专家。
这笔时间投入,值得。
「2026年最值钱的知识管理方式,不是建更多的文件夹,而是让AI替你记住一切。」
————————————————————————————————