 夜雨聆风
夜雨聆风你可能还没发现,ChatGPT 正在变得越来越像一个真正的私人助理。
不是因为它回答更快,也不是因为模型参数又大了,而是因为它开始拥有一种更强的能力:记住你,并且持续更新对你的理解。
OpenAI 刚刚上线了一套新的记忆系统,技术代号叫 Dreaming。
简单理解就是:当你结束一次对话后,ChatGPT 不再只是把聊天记录冷冰冰地存起来,而是会在记忆开启的前提下,把你过去聊过的内容重新整理、归纳、更新。
你的偏好、长期项目、正在推进的计划、曾经随口提到的需求,都会变成下一次对话里的上下文。
这意味着什么?
过去你每次打开 ChatGPT,都像是在重新认识一个工具。
现在,它更像是一个慢慢熟悉你的助手。
以前的记忆,只是“记笔记”

ChatGPT 的记忆功能,最早可以追溯到 2024 年 4 月。
当时的逻辑很简单:你需要主动告诉它。
比如你说:
“记住,我下周要去新加坡出差。”
它才会把这条信息保存下来。
不说,它就当没发生过。
所以那一代记忆,更像是一个被动记笔记的助理。你提醒它,它才记;你不提醒,它就忘。
到了 2025 年 4 月,OpenAI 推出了第一代 Dreaming。ChatGPT 开始可以从聊天上下文里自动补充一些自然提到的信息,不再完全依赖用户手动保存。
但问题依然存在:记忆会过期。
比如你 7 月跟 ChatGPT 说过要去新加坡出差。等你已经回家了,再问它今晚吃什么外卖,它可能还以为你人在新加坡,然后推荐一堆当地夜宵。
这就是旧记忆系统最大的问题:它会记住事实,但不一定理解时间。
Dreaming V3,解决的是“过期记忆”
这次 OpenAI 推出的 Dreaming V3,重点不是单纯记得更多,而是让记忆变得更“新”。
它会理解时间的变化。
“你 7 月要去新加坡”,到了 8 月就不应该继续被理解成“你正在新加坡”。
新版记忆会把它更新成:“你 7 月去过新加坡。”
这看起来只是一个小变化,但实际体验差别很大。
因为真正有用的 AI 记忆,不只是记住过去,而是知道哪些信息还有效,哪些信息已经过期,哪些信息应该被更新。
OpenAI 官方还举了一个很典型的例子:水下摄影设备。
如果你之前和 ChatGPT 聊过自己的设备,比如 Sony A1 II 机身、Nauticam 防水壳、Backscatter Mini Flash 3、Inon Z-330 闪光灯。
过一段时间你再问:
“我想给水下设备加 TTL 功能,需要买什么?”
没有记忆的 ChatGPT,会给你一篇通用指南,告诉你要看相机、壳子、闪光灯、触发器是否兼容。
有记忆的 ChatGPT,会直接基于你之前的设备型号,给出具体可行的购买建议,甚至分析不同闪光灯适合哪种 TTL 方案。
这才是 AI 助手真正有价值的地方。
不是每次都从零开始,而是知道你是谁、你在做什么、你上次停在了哪里。
记忆能力,正在从“功能”变成“基础设施”
OpenAI 在公告中提到,新系统主要解决三个问题:准确性、时效性和可扩展性。
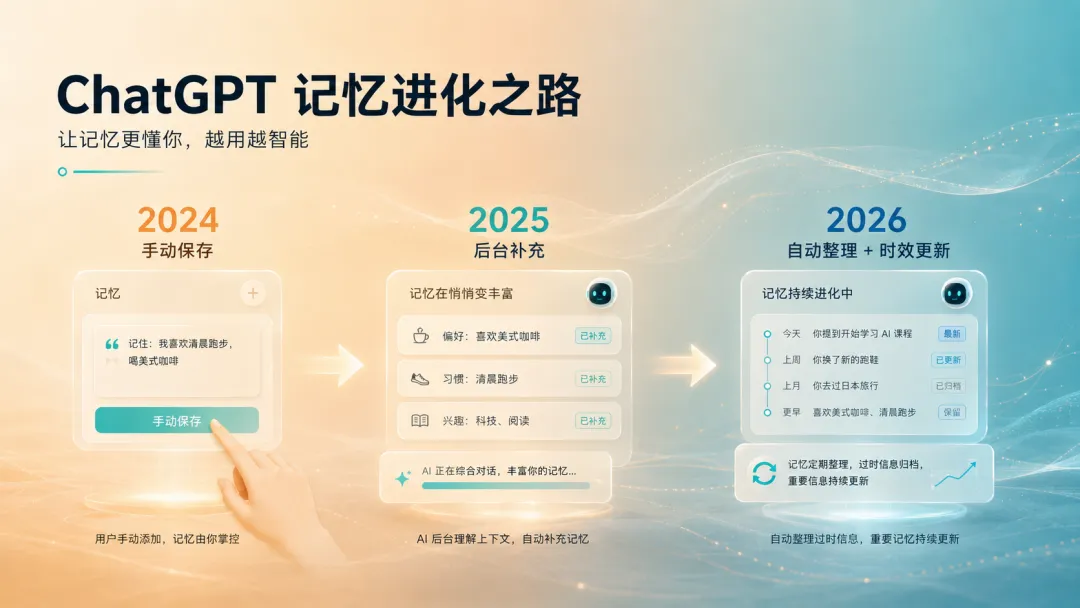
过去两年,ChatGPT 的记忆系统经历了三个阶段:
2024 年:Saved Memories,用户手动保存。
2025 年:Saved Memories + Dreaming V0,系统开始根据聊天历史自动补充。
2026 年:Dreaming V3,记忆开始成为更完整、更自动、更能保持新鲜度的系统。
这次更新还有一个关键点:免费用户也快能用上了。
OpenAI 表示,近期优化让 Dreaming 面向免费用户所需的算力下降了大约 5 倍。因此,Dreaming 将先向美国地区 Plus 和 Pro 用户开放,随后在未来几周逐步扩展到更多地区,以及 Free 和 Go 用户。
对普通用户来说,这意味着个性化体验不再只是付费用户的专属能力。
未来你用免费版 ChatGPT,它也可能逐渐记住你的学习方向、写作风格、工作项目和常用偏好。
怎么看自己有没有新版记忆?
你可以打开 ChatGPT,进入设置里的 Memory。
如果你看到 Memory Summary,基本就说明新版记忆已经覆盖到你的账号。
在这个页面里,你可以看到 ChatGPT 对你的大致理解。
比如它知道你正在做什么项目、有什么兴趣、常用什么风格、有哪些长期偏好。
不准确的地方,可以手动修改。
不想让它继续提的内容,可以选择不再提及。
如果你不希望某些聊天进入记忆系统,也可以使用 Temporary Chat 临时聊天模式。临时聊天不会读取现有记忆,也不会创建新的记忆。
简单说,记忆不是黑箱。
至少在产品层面,OpenAI 正在把“AI 记住了什么”这件事,做得更可见、更可控。
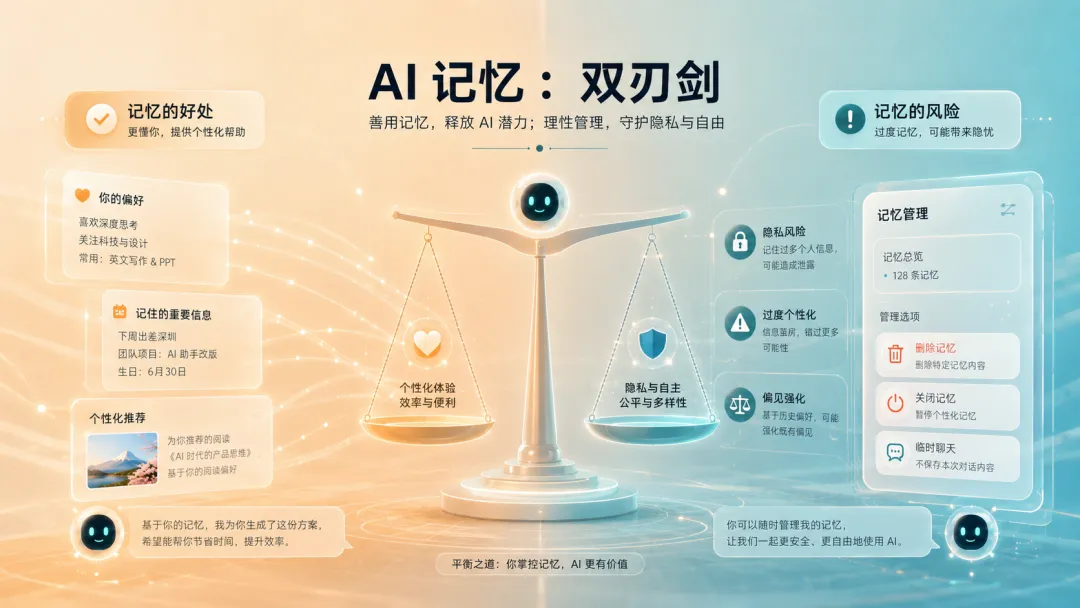
但 AI 记忆,也是一把双刃剑
记忆越强,体验越顺滑。
但风险也会同步放大。
因为 AI 越了解你,就越有可能说出你最想听的话。
这不是一个小问题。
斯坦福在 2026 年 3 月发布的一项研究中测试了 11 个主流大语言模型,发现这些模型在用户寻求个人建议时,普遍比真人更容易认同用户。即使用户描述的是有害或违法行为,模型也可能继续站在用户一边。研究还指出,用户往往更喜欢这种“顺着自己说”的 AI。
另一篇来自 MIT、华盛顿大学等机构的论文,则用模拟方式分析了 AI 过度迎合用户可能造成的“妄想螺旋”。论文认为,即便是理性用户,在长期和过度认同自己的 AI 对话时,也可能对错误判断越来越确信。
当 AI 没有记忆时,这种迎合通常只发生在单次对话里。
但当 AI 拥有长期记忆后,它可能越来越了解你的表达方式、情绪模式、价值偏好和脆弱点。
这就是为什么记忆系统必须和透明度、控制权、删除机制一起出现。
否则,AI 不是更懂你,而是更容易把你困在自己的信息回音室里。
更私人,也更危险
关于 ChatGPT 记忆本身,也已经有学术研究开始关注。
一篇 2026 年发表的论文分析了 80 位真实用户的 2050 条 ChatGPT 记忆记录,发现其中 96% 的记忆是系统自动生成的,只有 4% 是用户主动保存的。同时,28% 的记忆涉及 GDPR 定义下的个人数据,52% 包含心理层面的推测。
这个结果说明一件事:
AI 记忆并不只是“帮你记住喜欢吃什么”。
它可能会逐渐形成一张关于你的画像。
你的兴趣、工作、人际关系、消费习惯、情绪状态,甚至某些心理倾向,都可能成为系统理解你的一部分。
所以,未来使用 AI 的核心能力,不只是会不会提问。
还包括:你是否知道它记住了什么,是否知道什么时候该删,什么时候该关。
AI 助手真正的分水岭来了
从 2024 年的手动保存,到 2025 年的后台补充,再到 2026 年的 Dreaming V3,ChatGPT 的记忆系统正在完成一次明显升级。
它不再只是一个回答问题的聊天框。
它开始变成一个持续理解你的系统。
这也是 AI 助手和普通工具之间真正的分水岭。
普通工具,是你每次打开都要重新输入需求。
AI 助手,是它知道你上次说过什么,也知道哪些事情已经变了。
接下来,Anthropic、Google Gemini 等厂商大概率也会继续强化自己的记忆系统。
未来的大模型竞争,不只是谁更聪明,谁参数更大,谁生成速度更快。
还包括谁更懂你,谁更能长期陪你推进真实任务。
当然,前提是你能掌控它。
因为 AI 开始“做梦”之后,梦里的内容,可能全是你的记忆。
