 夜雨聆风
夜雨聆风





大模型训练全流程实战指南工具篇(九)——LLamaFactory大模型训练使用指南
前言
上篇文章《大模型训练全流程实战指南工具篇(八)——EasyDataset问答数据集生成流程》中,笔者系统介绍了如何构建高质量的问答对数据集。整个过程涵盖问题生成(支持单条/批量、三种算法)、答案生成(含思维链、多轮对话)、质量评估(采用“自动化初筛+人工抽检+迭代优化”策略)以及最终导出为Alpaca或ShareGPT标准格式,为模型训练提供了坚实的数据基础。
掌握了数据准备工具之后,本期内容开始将聚焦大模型训练环节。相比数据处理,大模型训练工具已经相当成熟。目前开源社区涌现出LLaMAFactory、Unsloth等优秀的训练框架,它们极大地降低了训练门槛,使广大中小企业和科研人员能够轻松训练出满足自身需求的专业模型。
本期内容笔者将以LLaMAFactory为例,详细介绍当前流行的大模型开源训练框架的使用方法,帮助读者快速上手并开展自己的模型训练项目。

《大模型训练指南》合集预计会有50期内容,将系统拆解从数据处理、模型训练到强化学习与智能体开发的全流程,并带大家从零实现模型,帮助大家掌握大模型训练的全技能,真正掌握塑造智能的能力!
PS:鉴于后台私信越来越多,我建了一些大模型交流群,大家在日常学习生活工作中遇到的大模型知识和问题都可以在群中分享出来大家一起解决!如果大家想交流大模型知识,可以关注我并回复加群
一、 为什么会出现大模型训练框架?
在正式介绍LLaMAFactory之前,先来探讨一个问题:为什么会出现大模型训练框架?这主要源于大模型微调过程中普遍存在的 “碎片化” 与 “高门槛” 两大痛点。传统方式下,针对不同模型需要分别实现各类微调算法,不仅代码工作量大,而且高度分散,难以复用和维护。大模型训练框架正是为解决这一问题而生——它们通过提供统一且高效的平台,使用户能够灵活地定制和训练上百种大模型,显著降低了技术门槛。
LLaMAFactory作为其中的佼佼者,其核心优势主要体现在以下两点:
- 极简操作,近乎零代码
用户无需编写代码,仅通过简单的配置即可完成数据集加载、参数设置并启动训练,极大提升了实验效率。此外,LLaMAFactory还提供了直观的WebUI界面,真正实现了“零代码”训练大模型。(笔者在日常工作中多采用配置文件的方式进行训练,本系列分享为了帮助大家深入理解大模型训练中的超参数设置,也将沿用配置文件的方式展开讲解。) - 广泛的模型与算法覆盖
支持包括LLaMA、Qwen、ChatGLM等在内的100余种主流模型,并集成了LoRA、QLoRA、GaLore、DoRA等前沿高效微调技术,满足不同场景下的定制需求。
二、LLaMAFactory 操作实战
本节笔者将带领大家一步步完成 LLaMAFactory 的实操演练,涵盖环境搭建、模型下载、数据准备、微调训练以及模型合并与部署的全过程。
2.1 LLamaFactory 环境搭建
在使用 LLaMAFactory 之前,需要安装 CUDA 驱动、PyTorch、metrics、transformers 等一系列依赖。为避免环境冲突,建议使用 Anaconda 管理 Python 环境。这里提供两种快速搭建环境的方式
方法一:使用 Lab4AI 大模型实验室平台(推荐)
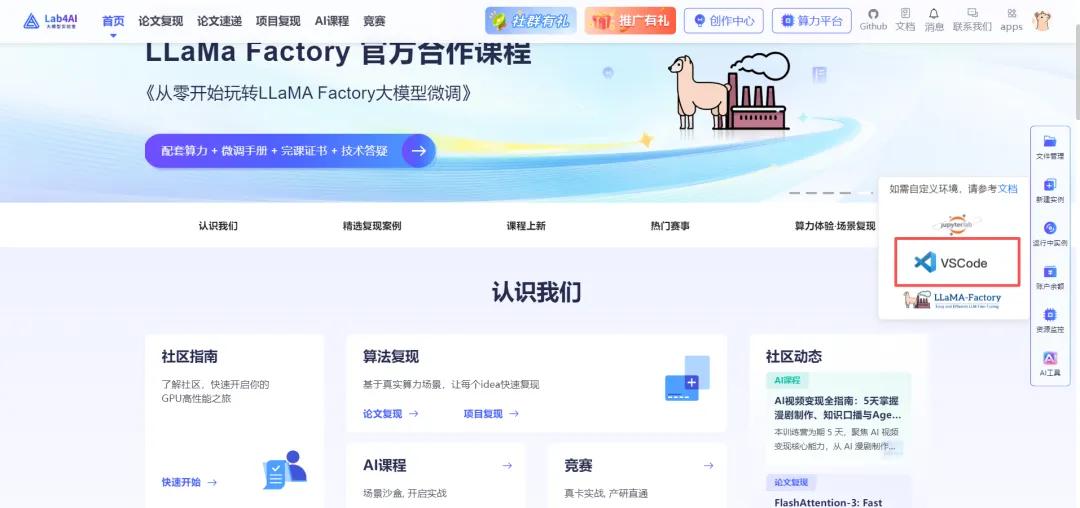
lf0.9.4 字样,说明该镜像已预装 0.9.4 版本的 LLaMAFactory,省去了手动安装的麻烦。根据需要选择显卡型号与数量,点击启动即可: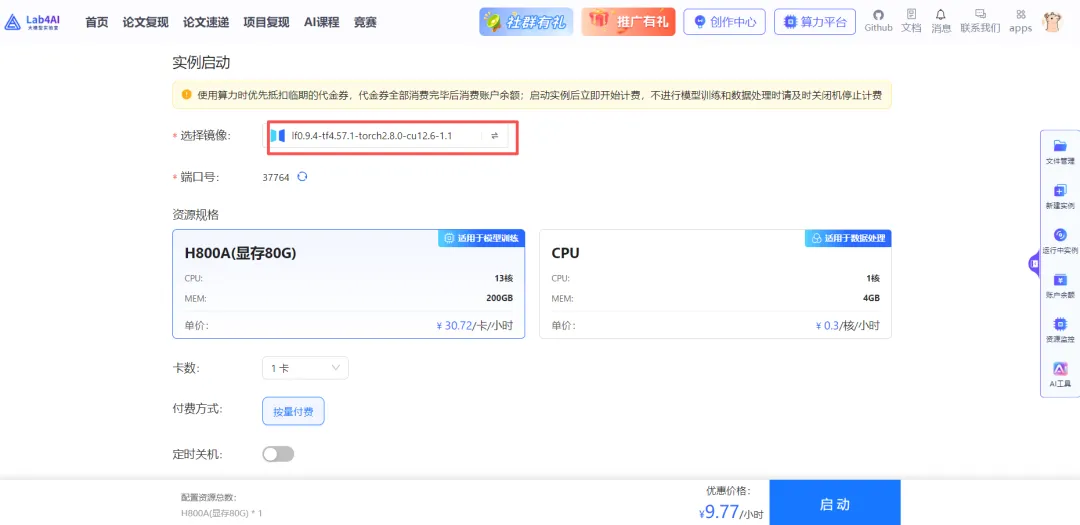
方法二:在自有 GPU 服务器上手动安装
若已有带显卡的 Linux 服务器(建议使用 Linux,Windows 也可但推荐 Linux可以减少安装依赖的复杂程度),可按照以下步骤从源码安装:
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.gitcd LlamaFactorypip install -e .pip install -r requirements/metrics.txt -r requirements/deepspeed.txt

注意:虽然 LLaMAFactory 支持 CPU 训练和推理,但速度会比 GPU 慢数百甚至数千倍,因此务必使用带显卡的服务器。
为避免环境配置困扰,本期实战推荐使用 Lab4AI 大模型实验室 平台进行学习。
2.2 LLamaFactory模型训练实战
为快速演示,下面笔者将以 Qwen2.5-0.5B-Instruct 模型为例,演示从模型下载到微调、合并、部署的完整流程。
Qwen2.5-0.5B-Instruct 模型。使用 ModelScope 命令下载(ModelScope 的使用可参考 大模型训练全流程实战指南基础篇(三)——大模型本地部署实战(Vllm与Ollama))modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir ./Qwen2_5_0_5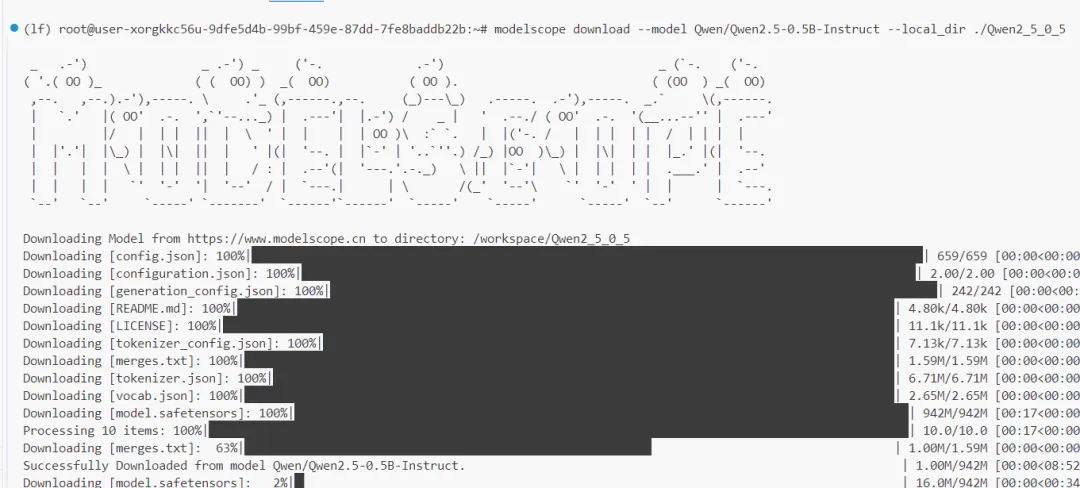
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.gitcd LlamaFactory
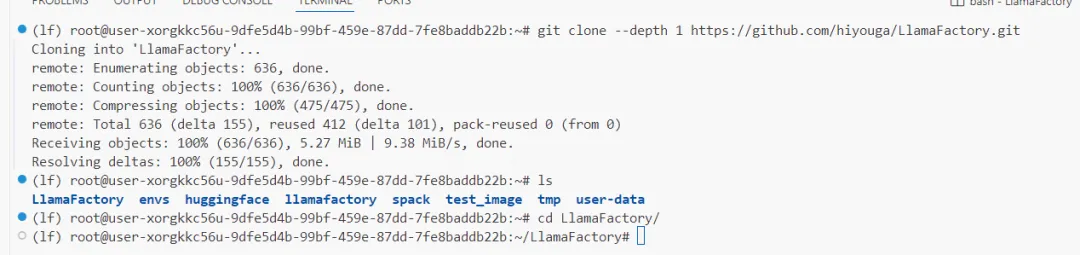
LlamaFactory/data 目录,打开 alpaca_zh_demo.json 文件,可见其为 Alpaca 格式的问答数据。后续实战中,大家也可以将自己的数据集整理为相同格式。为了让 LLaMAFactory 识别该数据集,需要在 data/dataset_info.json 中注册。检查该文件,发现示例数据集已被默认注册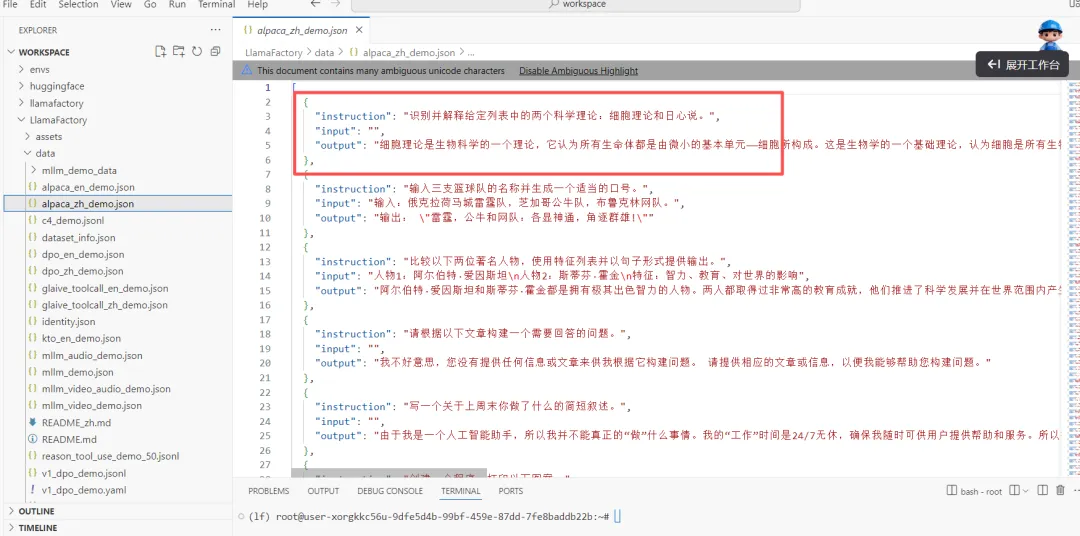
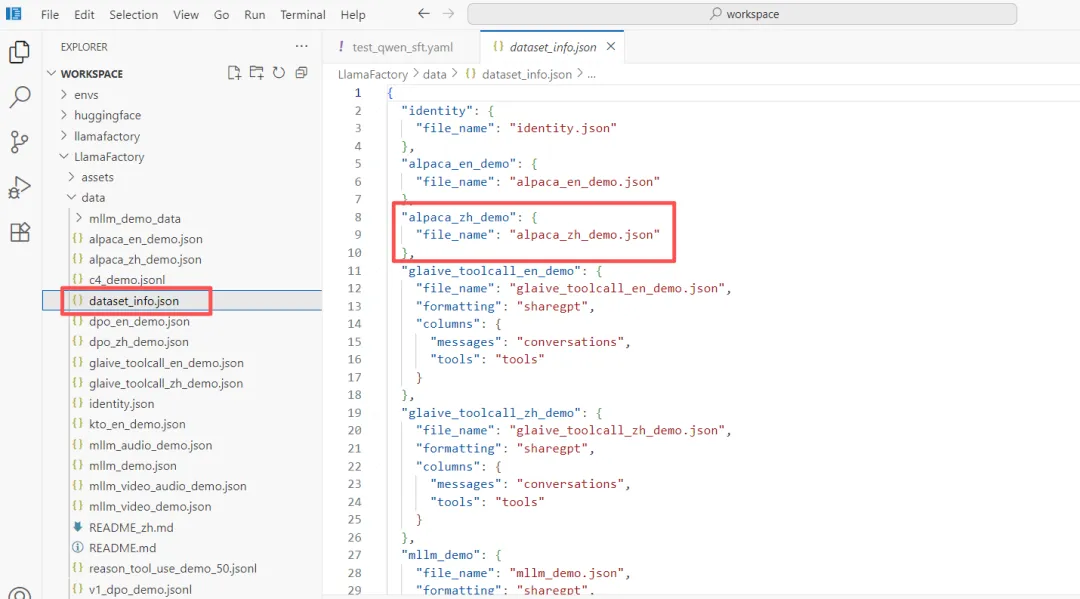
4. 编写训练配置文件: LLaMAFactory 通过“命令行 + 配置文件”的方式启动训练。官方提供了大量示例配置,位于 examples/train_lora/ 目录下。以 qwen3_lora_sft.yaml 为例,其中包含众多超参数。初学者可能感到陌生,后续笔者将专门用一期内容详细解读每个参数的含义。本期目标是跑通流程,因此只需修改关键参数即可。
在工作目录下新建项目文件夹 test_sft,将示例配置复制到该目录下并重命名为 test_qwen_sft.yaml,然后修改以下关键字段:
model_name_or_path
指定模型路径,改为 /workspace/Qwen2_5_0_5dataset
使用在 dataset_info.json中注册的数据集名称,保持示例中的名称(如alpaca_zh_demo)template
根据模型选择对话模板。对于 Qwen 系列,通常设为 qwen(原示例中为qwen3_nothink,需修改)output_dir
训练输出目录,设为 /workspace/test_sft/Qwen2_5_sftnum_train_epochs
训练轮数,为快速演示设为 1
其余参数可暂时保持默认,修改后的配置文件内容大致如下(只展示关键行):
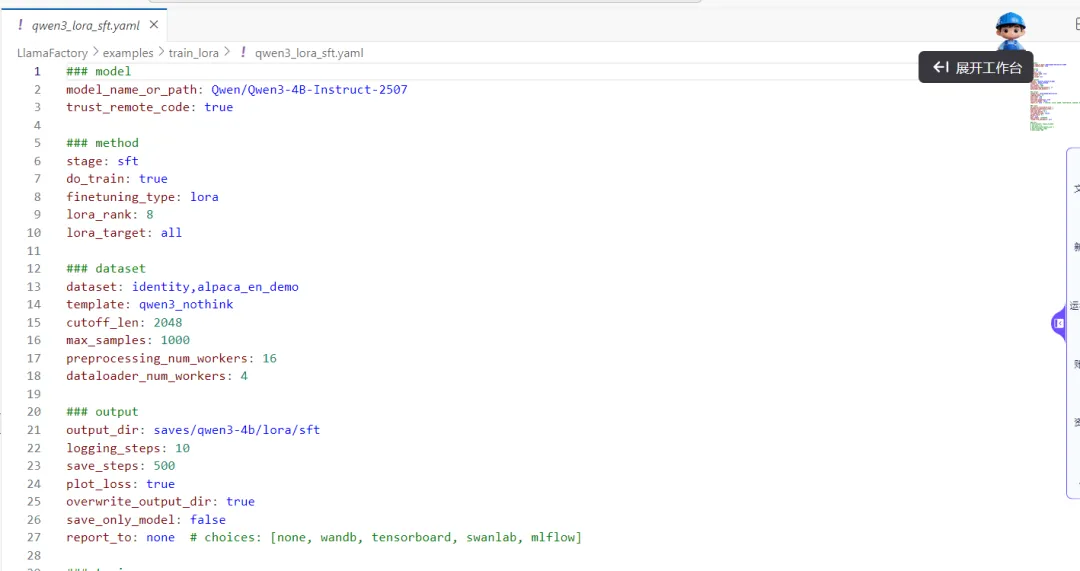
LlamaFactory 目录下执行以下命令开始微调:llamafactory-cli train /workspace/test_sft/test_qwen_sft.yaml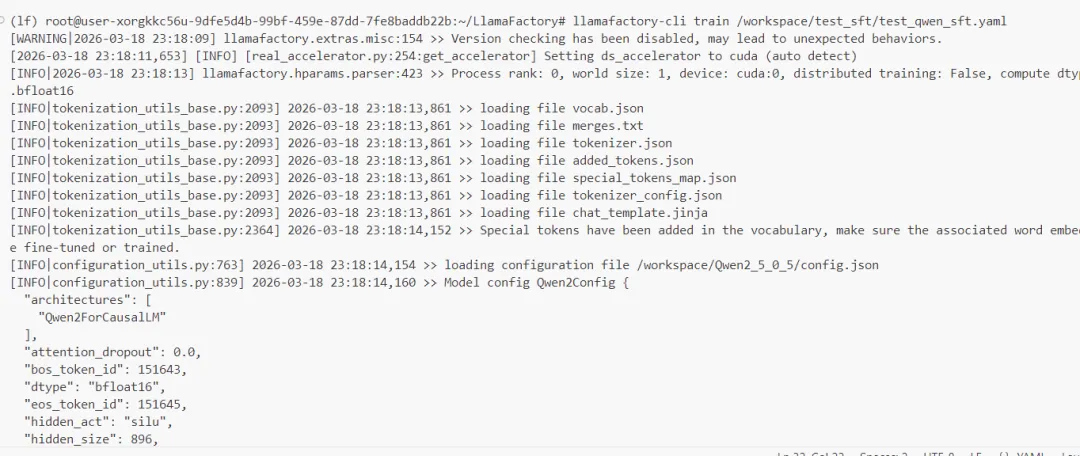
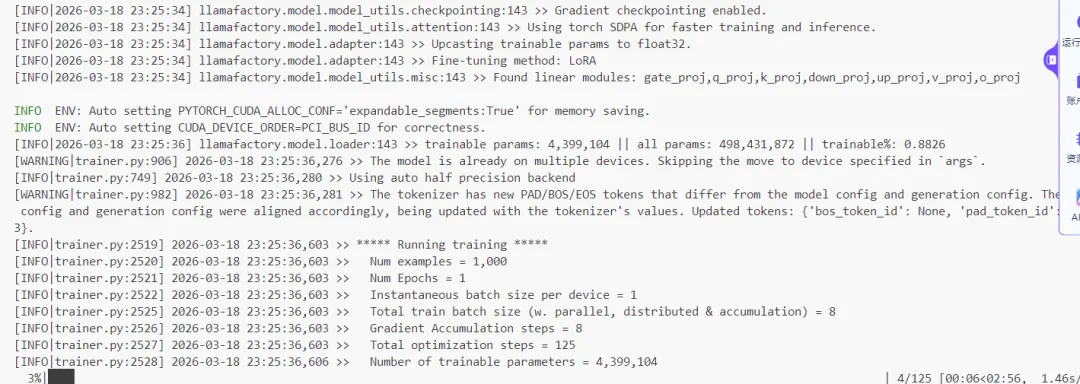
/workspace/test_sft/Qwen2_5_sft 下保存了 LoRA 适配器权重及中间检查点: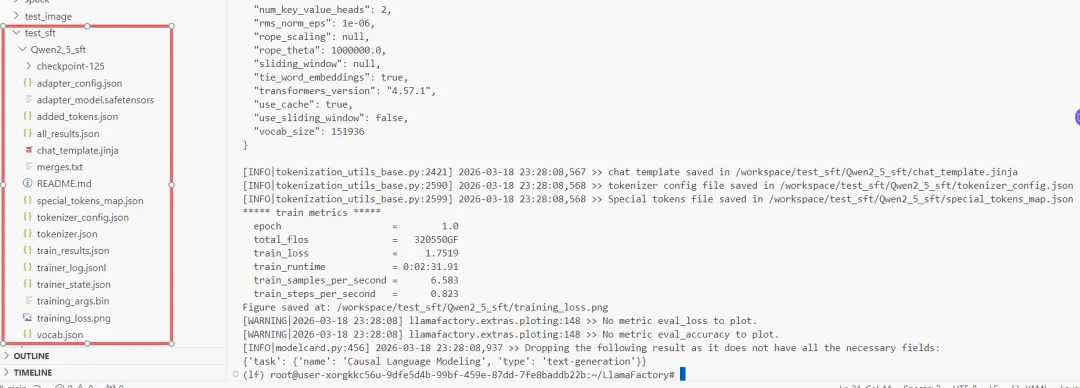
examples/merge_lora/qwen3_lora_sft.yaml。将其复制到 /workspace/test_sft/test_qwen_merge_sft.yaml,并修改参数如下:### Note: DO NOT use quantized model or quantization_bit when merging lora adapters### modelmodel_name_or_path: /workspace/Qwen2_5_0_5adapter_name_or_path: /workspace/test_sft/Qwen2_5_sfttemplate: qwentrust_remote_code: true### exportexport_dir: /workspace/test_sft/Qwen2_5_sft_allexport_size: 5export_device: cpu # choices: [cpu, auto]export_legacy_format: false
LlamaFactory 目录下执行合并命令:llamafactory-cli export /workspace/test_sft/test_qwen_merge_sft.yaml/workspace/test_sft/Qwen2_5_sft_all 目录下,大小与原始模型相当(约 1g):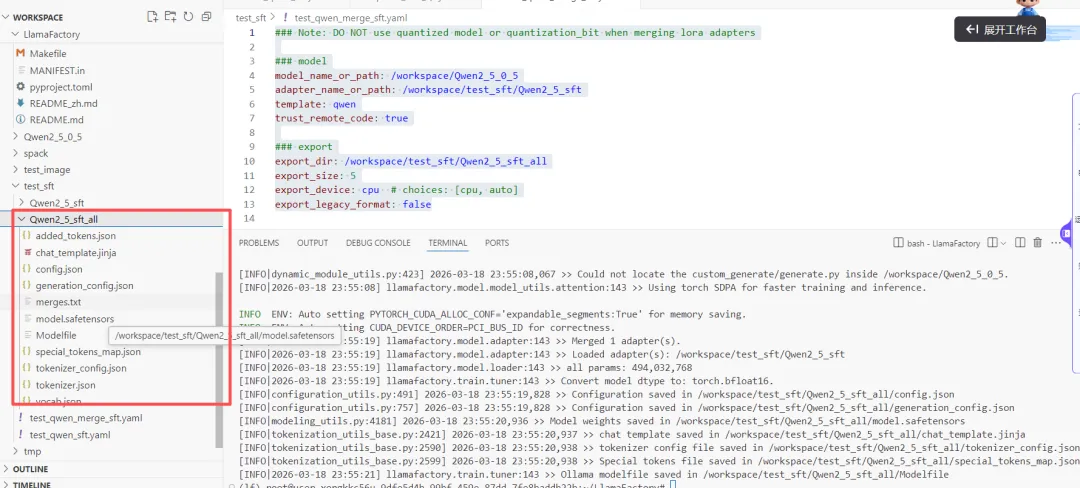
vllm serve /workspace/test_sft/Qwen2_5_sft_all --served-model-name Qwen2_5 --max-model-len 8096 --gpu-memory-utilization 0.9 --port 6666from openai import OpenAIclient = OpenAI(base_url="http://localhost:6666/v1", api_key="EMPTY")response = client.chat.completions.create(model="Qwen2_5", messages=[{"role": "user", "content": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。"}])print(response.choices[0].message.content)

三、总结
本期分享以 LLaMAFactory 大模型训练框架 为例,从环境搭建到模型下载、数据准备、微调训练、权重合并及部署测试,完整演示了 Qwen2.5-0.5B 的实战流程,充分展现了 LLaMAFactory 极简操作与广泛模型兼容的核心优势。通过本文大家可快速上手大模型微调,并掌握从训练到部署的全链路方法。下一期笔者将深入解析训练配置文件中的各项参数,帮助大家真正成为调参高手,敬请期待!
要想完全学懂还是需要亲手实践一下,大家可以照着笔者的教程亲手实践一遍。为降低大家学习门槛,笔者与国内主流云平台合作,大家可以通过扫描下方二维码 ,体验H100 GPU 6.5小时的算力。本系列所有实战教程均将在该平台上完成,帮助大家低成本上手实践。

除大模型训练外,笔者也在同步更新《深入浅出LangChain&LangGraph AI Agent 智能体开发》免费专栏,要说明该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 40讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的微信公众号大模型真好玩,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
PS:鉴于后台私信越来越多,我建了一些大模型交流群,大家在日常学习生活工作中遇到的大模型知识和问题都可以在群中分享出来大家一起解决!如果大家想交流大模型知识,可以关注我并回复加群