 夜雨聆风
夜雨聆风





Anthropic自己把源码塞进了npm包!50万行Claude Code全曝光,48小时社区已分叉出「OpenClaude」多版本
Anthropic自己把源码塞进了npm包!50万行Claude Code全曝光,48小时社区已分叉出「OpenClaude」多版本
3342万人围观、近5万人点赞——安全研究员Chaofan Shou发现Anthropic把Claude Code的完整源码打进了npm包。还没等Anthropic反应过来,社区已经把这套顶级AI编程工具分叉成了三条路线:直接镜像、Python/Rust重写、支持任意模型的OpenClaude。最讽刺的是,Claude Code内部有一套专门防止泄密的「Undercover Mode」——结果Anthropic自己先把源码送了出去。
一个59.8MB的调试文件,撕开了闭源AI工具最大的遮羞布
3月31日,Anthropic照常推送了Claude Code的npm更新,版本号`2.1.88`。
一切看起来毫无异样。
但安全研究员Chaofan Shou(@Fried_rice)只用了23分钟就发现了问题:这个包里多了一个不该出现的东西——一份59.8MB的source map文件。
Source map是前端开发中用于调试的映射文件,它能把压缩后的代码还原成原始源码。更要命的是,这份source map直接指向了Anthropic自己云存储桶里的一个zip压缩包。点开链接,1900多个文件、超过51.2万行TypeScript源码,一览无余。
“Claude code source code has been leaked via a map file in their npm registry!”
「Claude Code的源码通过npm registry里的map文件泄露了!」
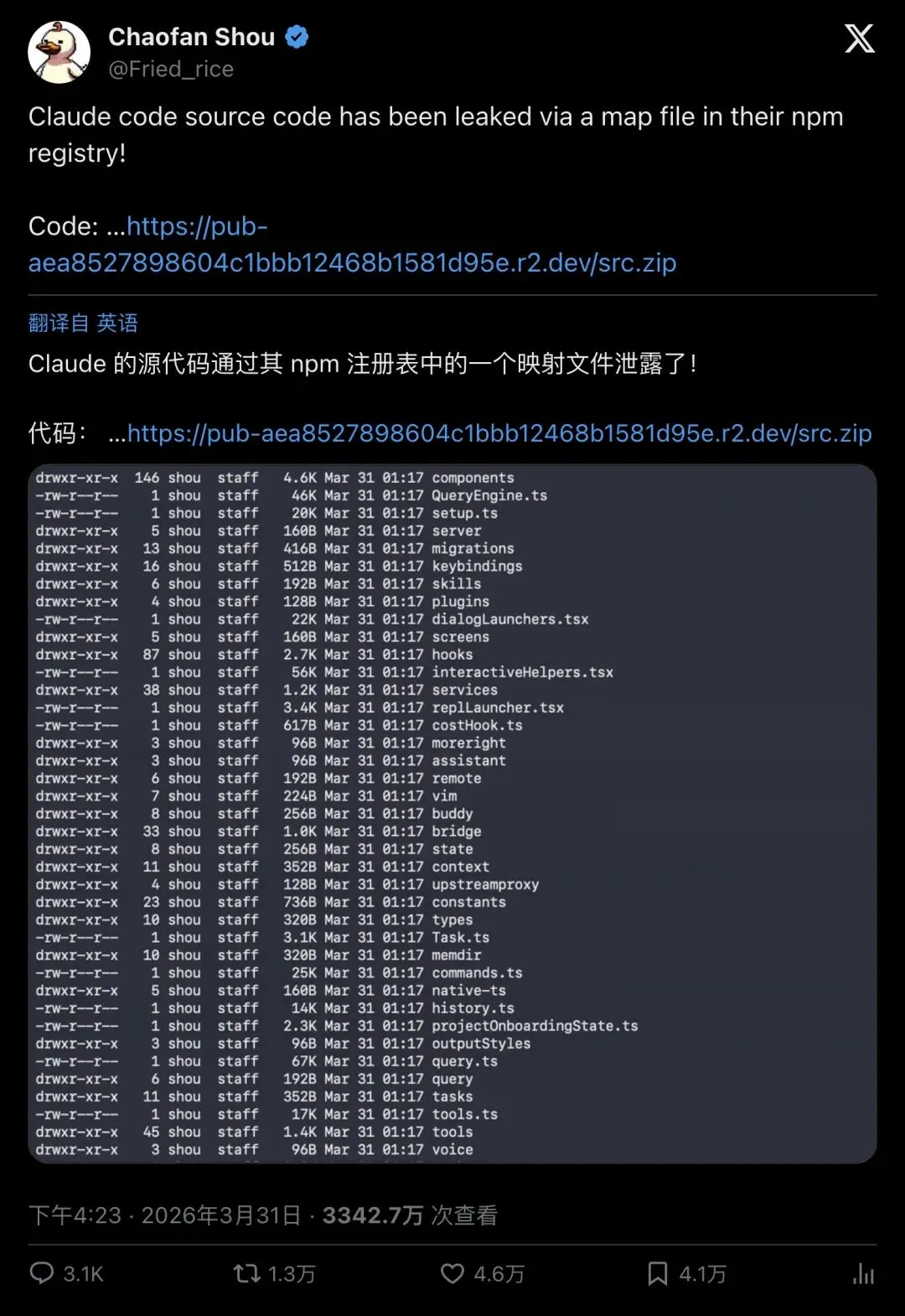
▲ Chaofan Shou的首爆帖——3342万次浏览,近5万人点赞,这是2026年AI圈迄今最大的一次源码曝光事件
这条帖子的传播速度堪称恐怖:6小时内浏览量突破300万,转发过万,评论区瞬间变成技术分析现场。
社区的反应不是「围观」,而是「直接动手」
如果这次泄露的只是一个普通前端项目,故事可能到此为止。
但Claude Code不是普通项目。它是目前最强的AI编程工具之一——一套完整的agentic coding harness(智能编程脚手架),内含bash执行、文件读写、grep搜索、子智能体调度、上下文记忆、MCP协议支持……这些正是全世界开发者最想知道「到底怎么做」的东西。
所以社区的反应不是感叹「哇源码泄露了」,而是:拉下来,拆开来,改起来。
泄露后几个小时内,GitHub上已经出现了第一批镜像仓库。有人备份源码防止链接失效,有人开始逐行分析内部架构。
Sigrid Jin(@realsigridjin)是最早行动的人之一。这位据说去年消耗了250亿token的Claude Code重度用户,第一时间把源码备份到了自己的GitHub。
“i backed the source up on my github”
「我已经把源码备份到我的GitHub了。」
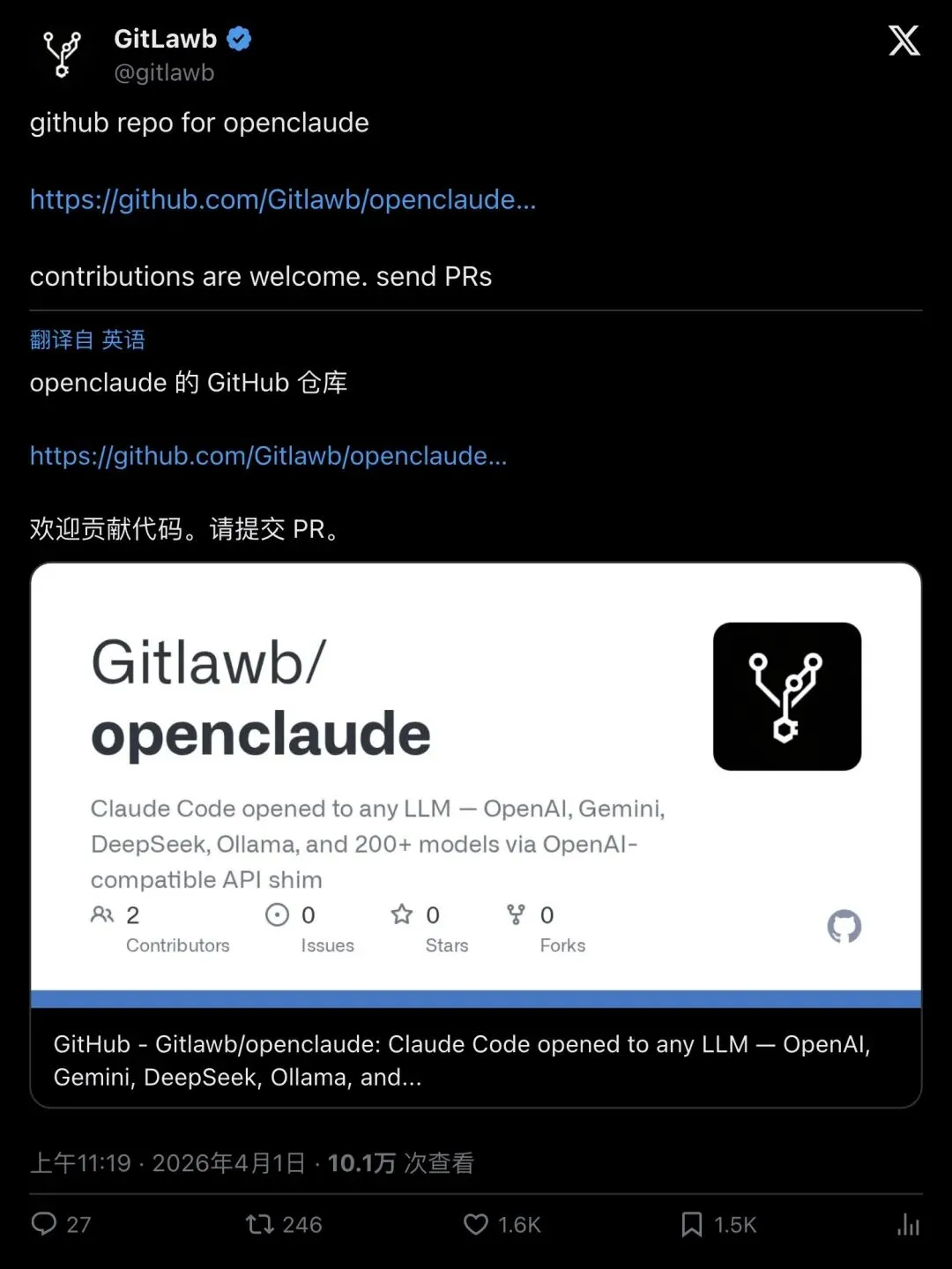
▲ Sigrid Jin的备份帖——近6000赞,216万次浏览。随后他发起的claw-code项目成为clean-room重写路线的代表
而这仅仅是开始。
三条分叉路线,48小时内全部成型
真正让这件事从「安全事故」变成「产业事件」的,是接下来发生的事情。
第一条路线:直接镜像。最简单粗暴——把泄露的源码原封不动搬到GitHub。但这条路走不远,Anthropic很快开始发DMCA下架通知,直接镜像的仓库陆续被删。
第二条路线:clean-room重写。Sigrid Jin主导的`claw-code`项目走了另一条路。仓库README明确声明自己不是「泄露源码档案馆」,而是一个重写项目(rewrite project)。他先用Python重写了一遍,然后又用Rust重写了一遍。
结果?claw-code仓库的star数在短时间内冲到了10万以上,有人称之为GitHub历史上增长最快的项目之一。
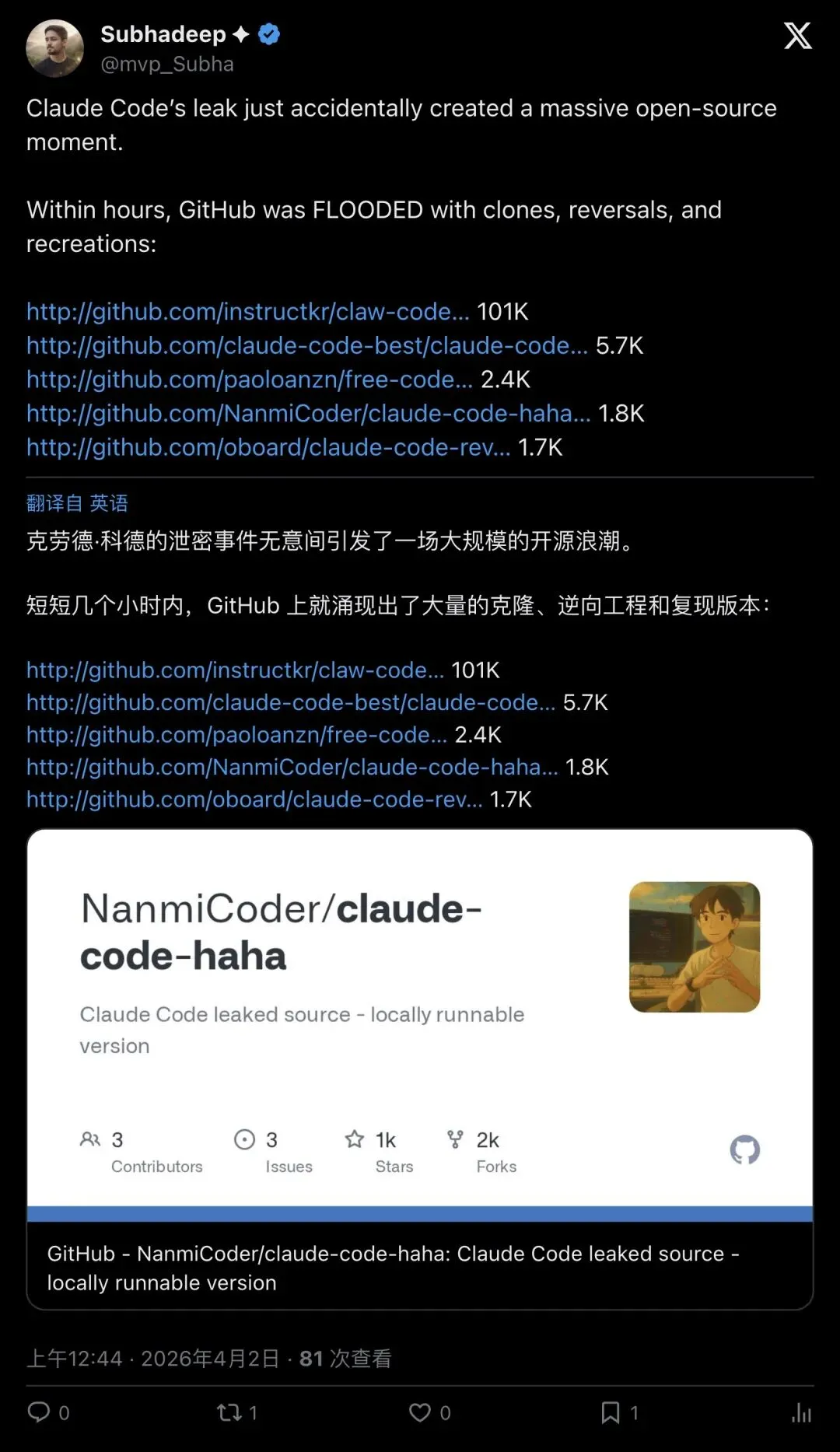
▲ 泄露后涌现的各种分叉和重写项目——claw-code以超过10万star领跑,多个独立版本并行发展
第三条路线:让Claude Code跑任意模型。这是最有想象力的一条——GitLawb(@gitlawb)把Claude Code的工具系统改造成了支持OpenAI兼容API的版本。GPT-4o、DeepSeek、Gemini、Llama、Mistral……随便挑。
“We forked the leaked Claude Code source and made it work with ANY LLM”
「我们fork了泄露的Claude Code源码,并让它能跑任何LLM。」
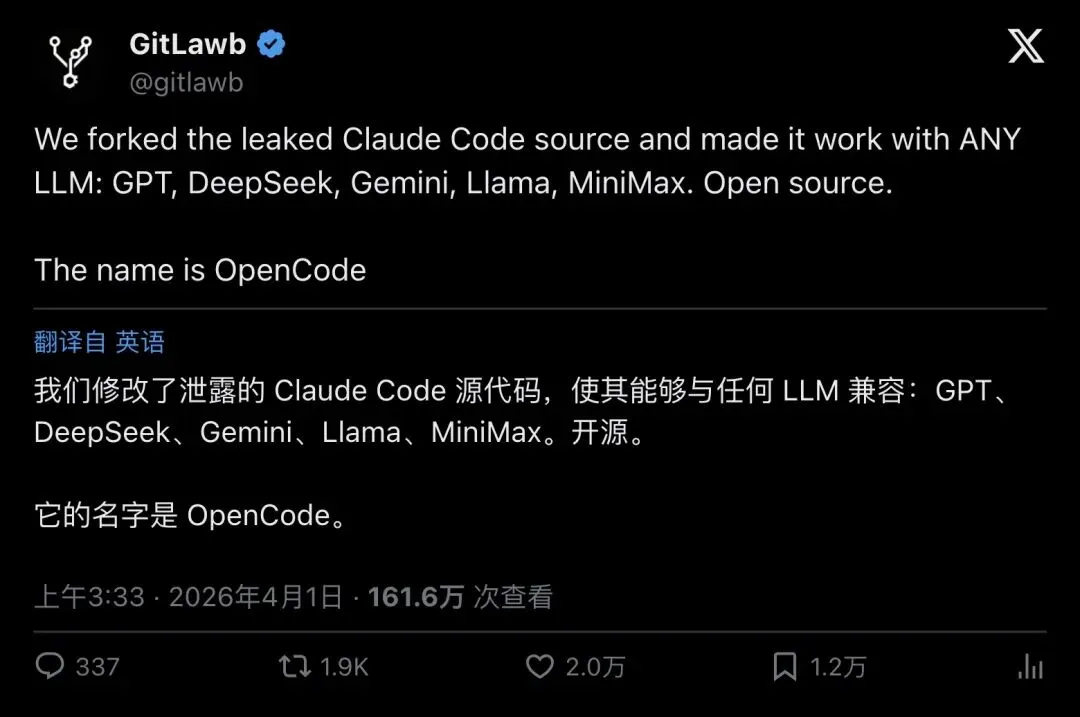
▲ GitLawb的爆款宣布帖——2万赞,161万次浏览。注意原文写的是「OpenCode」,后来改名为「OpenClaude」
有意思的是传播链中的一个小插曲:GitLawb一开始把项目叫做OpenCode,但评论区多位用户指出应该叫OpenClaude。GitLawb随后回复:`OpenClaude is the final name :)` ,并单独发帖贴出了GitHub仓库链接。
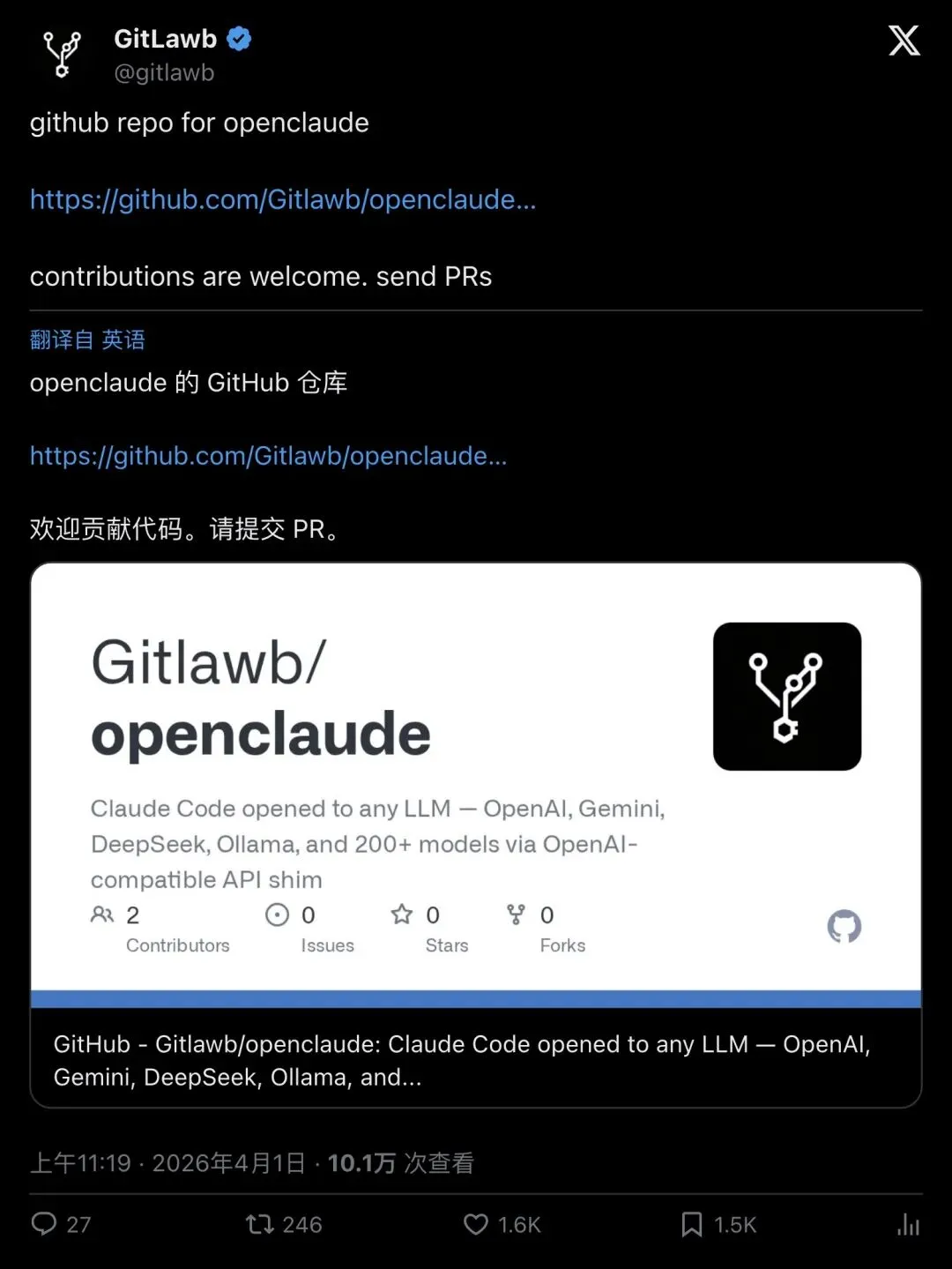
▲ OpenClaude正式落地——支持OpenAI、Gemini、DeepSeek、Ollama等200+模型的Claude Code分叉版
这个命名纠偏的过程本身就很有意思:从「OpenCode」到「OpenClaude」,社区不只是在给项目取名字,而是在定义一种新的品类——把闭源AI编程工具的能力框架开放化。
Anthropic的回应:「人为失误,不是安全入侵」
面对铺天盖地的传播,Anthropic的反应分两步:技术上修复,公关上灭火。
记者Alex Heath最先拿到了官方声明:
“This was a release packaging issue caused by human error, not a security breach. No sensitive customer data or credentials were involved or exposed.”
「这是人为失误导致的发布打包问题,不是安全入侵。没有涉及或泄露任何敏感的客户数据或凭证。」
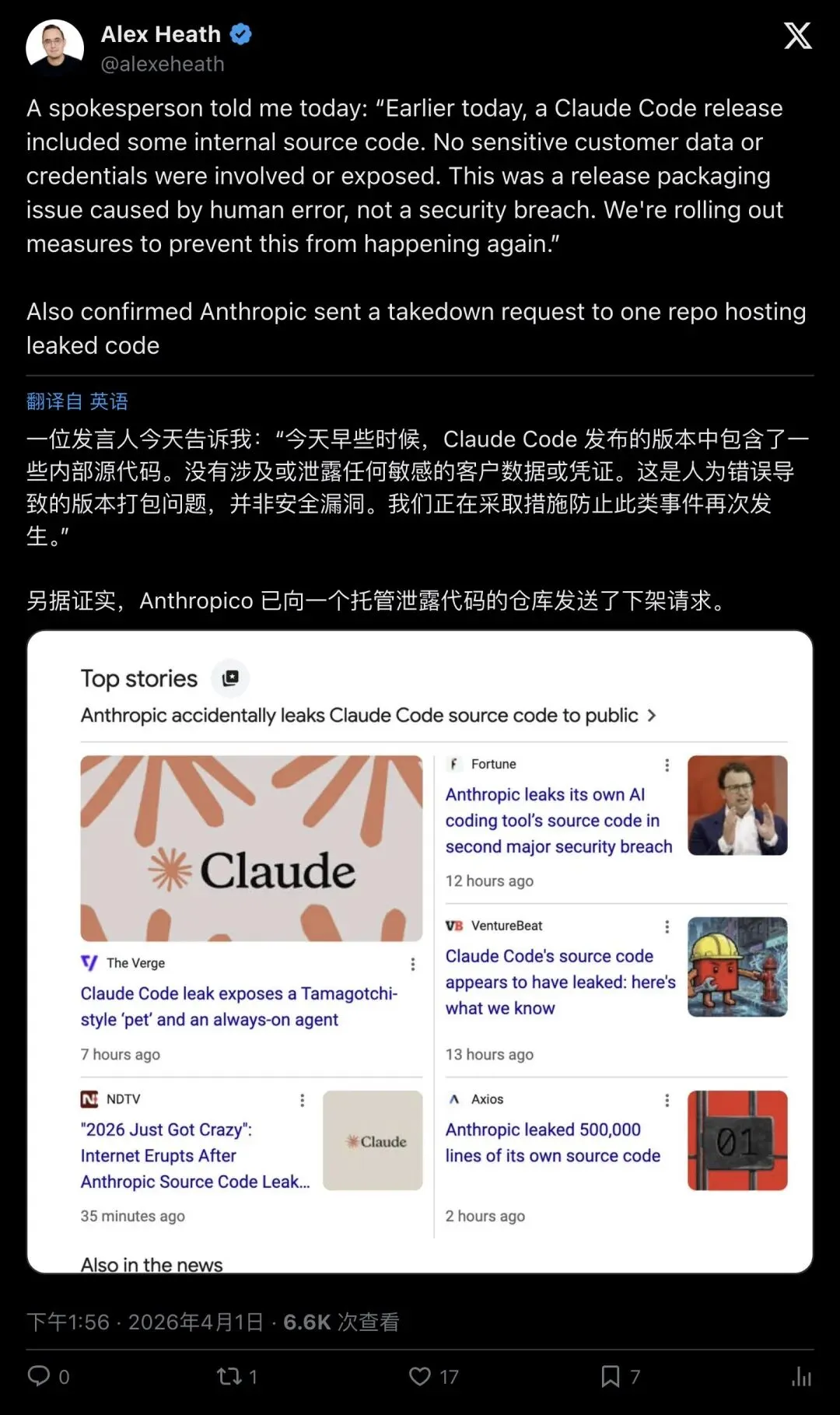
▲ 记者Alex Heath转述的Anthropic官方声明——The Verge、Fortune、Axios、VentureBeat等主流科技媒体同步跟进报道
▲ Bloomberg也跟进报道:Anthropic高管将泄露归咎于「流程错误」
Anthropic的定性很明确:这不是被黑客攻破,而是发布流程中的`.npmignore`配置失误,加上Bun打包工具默认生成source map的行为,导致调试文件被错误地推送到了公共registry。
说白了,就是有人忘了在发布配置里排除调试文件。
这个口径在技术上站得住脚。但问题是——等Anthropic醒过来的时候,代码已经被fork了几万次。
逆向拆解:社区从源码里看到了什么?
泄露不只是让人「看到了源码」,而是让整个社区获得了一份生产级AI编程工具的完整蓝图。
技术社区最兴奋的发现包括:
- 子智能体系统
:Claude Code内部有一套隔离上下文的子智能体调度机制,支持KV cache继承,实现并行任务处理,据称可以削减60%以上的成本 - 上下文压缩
:当对话上下文接近token上限时,系统会自动摘要和丢弃部分数据 - 工具限制
:文件读取上限约2000行,工具结果会被截断 - 内部feature flags
:一些功能被标记为仅限Anthropic员工使用
有开发者甚至把泄露的源码和自己几十亿token的使用日志做了交叉对比,发现Anthropic给员工和普通用户开放的能力并不一样。
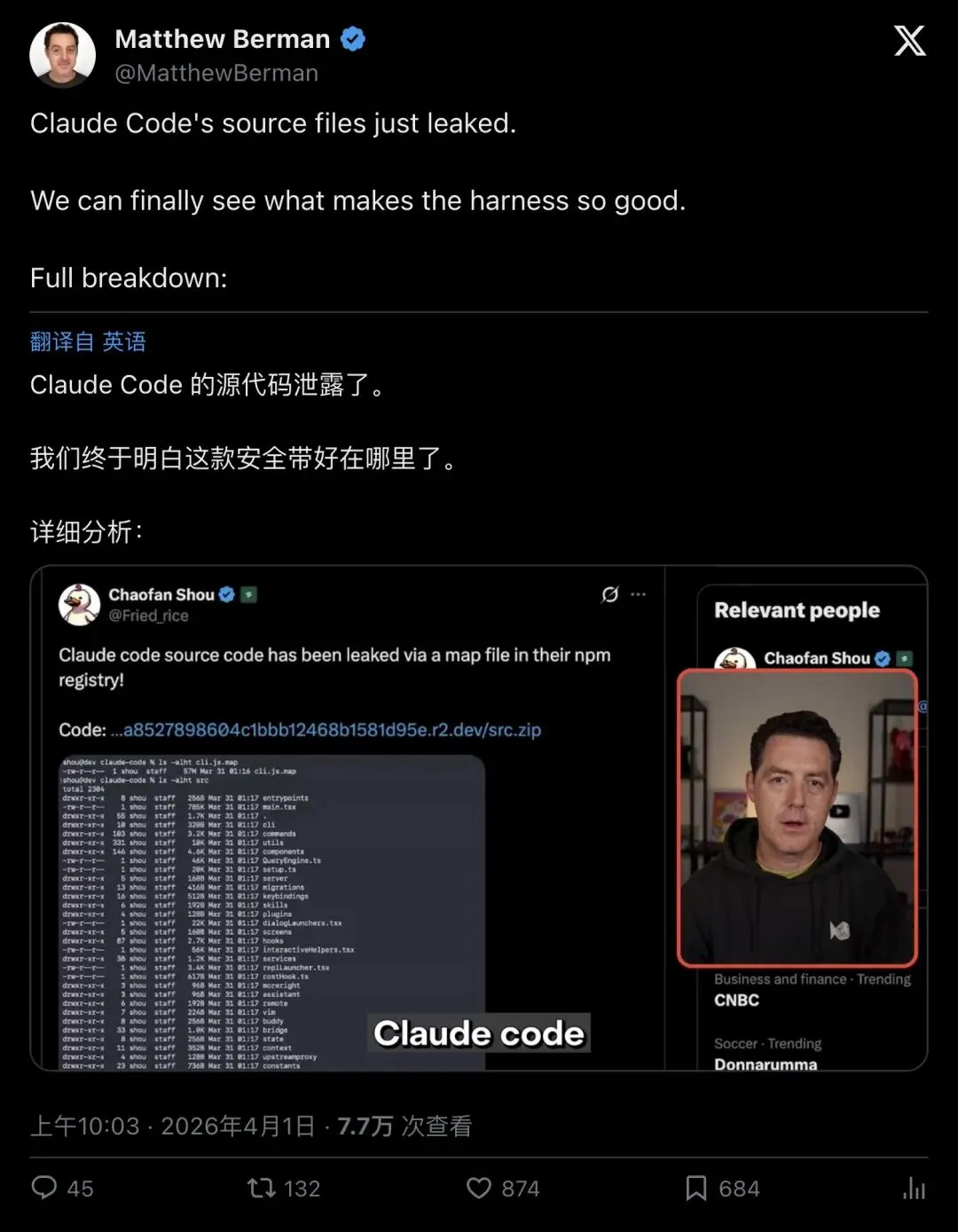
▲ 技术社区对Claude Code源码的深度拆解引发大量讨论
有人评论说:「这不是围观,这是整个行业在上课。」
最讽刺的反差:Undercover Mode
在所有被挖出来的内部功能中,有一个细节让整个事件变得格外讽刺——Undercover Mode(卧底模式)。
这是Claude Code内置的一套安全系统,专门用来防止泄密。
它的工作原理是:当Claude Code被用于向公开或开源仓库提交代码时,系统会自动激活Undercover Mode,禁止AI在commit信息和PR描述中泄露以下内容:
-
内部模型代号(比如Capybara、Tengu等动物名) -
未发布的模型版本号 -
内部仓库名称 -
甚至「Claude Code」这个名字本身
换句话说,Anthropic花了大量精力构建了一套防止AI泄露公司机密的系统。
然后他们自己,因为忘了在发布配置里排除一个调试文件,把包含这套反泄密系统在内的全部源码一起送了出去。
网友的总结一针见血:
“They shipped an entire anti-leak system in their own product. Then leaked their own source code in a .map file. Irony is beautiful.”
「他们在自己的产品里装了一整套反泄密系统。然后通过一个.map文件泄露了自己的全部源码。讽刺真美。」
真正的问题:闭源AI工具的护城河到底在哪?
这次事件让一个早就存在的争论彻底浮出水面:AI编程工具的壁垒,到底在哪里?
从表面上看,Claude Code的竞争力似乎在于它那套精密的工具系统——bash执行、文件操作、智能搜索、子智能体调度、上下文管理……但这次泄露证明了一件事:这套工程实现可以被复制,而且可以被非常快地复制。
48小时。
从源码曝光到出现可运行的多模型版本,只用了48小时。

▲ 社区讨论:Anthropic最大的护城河已经被正式分叉了吗?
但很多冷静的声音也在指出:源码从来就不是真正的护城河。
“the source was never the actual moat anyway”
「源码从来就不是真正的壁垒。」
真正难复制的是什么?模型质量、训练反馈数据、企业分发渠道、品牌信任、迭代速度。这些东西不在那51.2万行TypeScript里。

▲ 有开发者用「大坝决堤」的梗图形容这次泄露——经典的供应链失误
这次事件还引发了另一个前沿讨论:AI辅助的clean-room重写,在版权法上到底怎么定性?
传统的clean-room实现要求重写者从未看过原始源码,靠独立理解功能规格来重新实现。但在AI时代,你可以让大模型「看」着测试用例和行为描述来重新生成代码——这算clean-room吗?
目前没有法院对此做出过判决。但`claw-code`和`openclaude`的存在,正在把这个问题从理论讨论推向现实。
48小时:从意外到生态
回头看这48小时发生的事情:
第0小时——Anthropic发布Claude Code 2.1.88。
第0.4小时——Chaofan Shou发现source map,发帖曝光。
第6小时——帖子浏览量突破300万,源码镜像遍布GitHub。
第12小时——Anthropic发表声明,开始DMCA下架。社区转向clean-room重写。
第24小时——claw-code(Python重写版)和OpenClaude(多模型fork版)先后上线。
第48小时——claw-code star数突破10万,Rust版启动开发。OpenClaude支持200+模型。舆论焦点从「泄露」转向「闭源AI工具的商品化速度」。

▲ 社区对这次事件的深度复盘——从泄露到分叉到法律争议,每一层都在加速
一次发布流程的失误,意外按下了闭源AI工具商品化的快进键。
Anthropic花了几年时间构建的agentic coding harness,社区用48小时就把它的能力框架铺设到了几乎所有主流大模型上。
这件事的真正教训或许不在于「怎么防止source map泄露」——而在于:当你的产品壁垒建立在工程实现而非模型能力之上时,一次意外就足以改变整个竞争格局。
下一个被「意外开源」的,会是谁?
— END —