当Excel遇见鸢尾花:一个数据分析小白的探索之旅(一)
数据来源:https://www.kaggle.com/datasets/himanshunakrani/iris-dataset
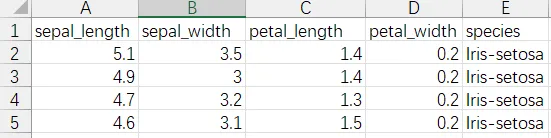
150朵花,4个测量指标,3个品种——数据里藏着怎样的秘密?
表格里面有四个五个字段,分别是sepal_length(萼片长度)、sepal_width(萼片宽度)、petal_length(花瓣长度)、petal_width(花瓣宽度)、species(品种分类标签)等,总150条没有异常值。
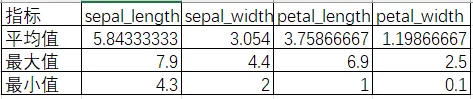
首先计算出来了平均数、最大值、最小值等,发现萼片长度最大可以达到7.9cm,最小为4.3cm,花瓣长度最大为6.9cm,最小为1cm,最主要的是花瓣长度的均值为3.76cm最大长度是6.9cm,说明数据比较分散的可能,可能可以看长度区分花的品种。
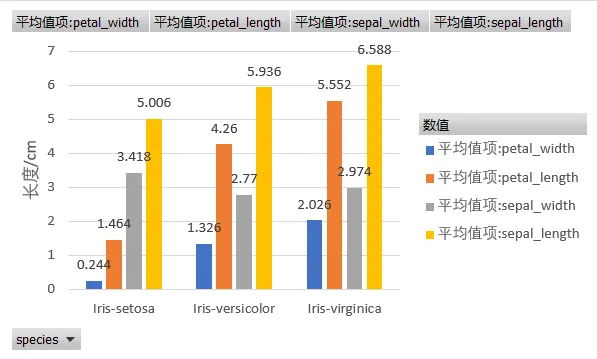
当我看到柱状图的那一刻,Setosa和另外两种的差距比我预想的还要大,真的很惊讶。Setosa的花瓣简直像小指甲盖,而Virginica像小勺子。如果只看花瓣长度,Setosa根本混不进另外两个品种的圈子。
但是,平均值会不会掩盖个体差异?有没有可能存在‘长花瓣但窄花瓣’的怪胎?下一节我们用标准差和散点图来回答。
 夜雨聆风
夜雨聆风