 夜雨聆风
夜雨聆风





图文混合文档的轻量级多模态listwise重排框架:Rank-Nexus
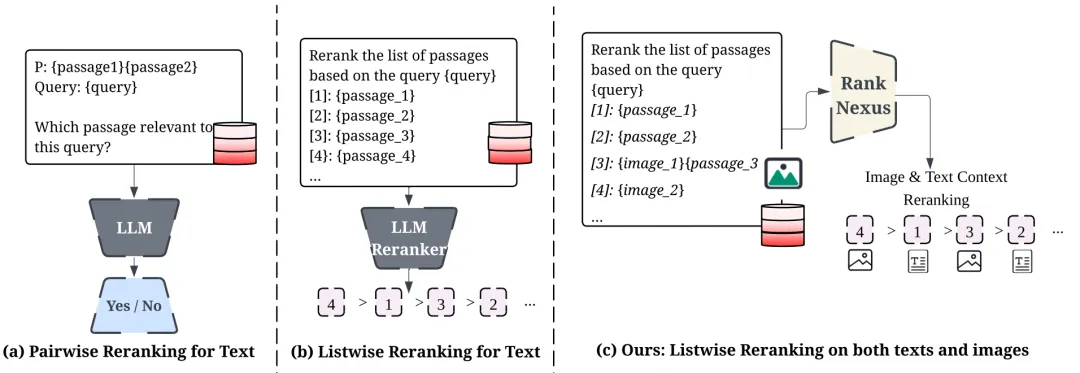
-
Pairwise:逐对比较文档,预测更相关的样本,累计得分后排序;仅关注局部两两关系。 -
Listwise:同时处理全部候选,基于Plackett-Luce概率模型直接输出全局排序;优化整体重排质量,是本文核心范式。
本文介绍的方法Rank-Nexus将Listwise重排序扩展至多模态场景,联合处理文本段落和图像,生成排序。
定义:给定查询 、第一阶段检索得到的候选文档集 (文档可含文本/图像/图文混合),目标是学习排序函数 ,输出按查询相关性从高到低的文档排列。
采用CLIP获取图文对齐表征:
-
图像嵌入 ,文本嵌入 -
用余弦相似度计算图文相关性:
Rank-Nexus 方法
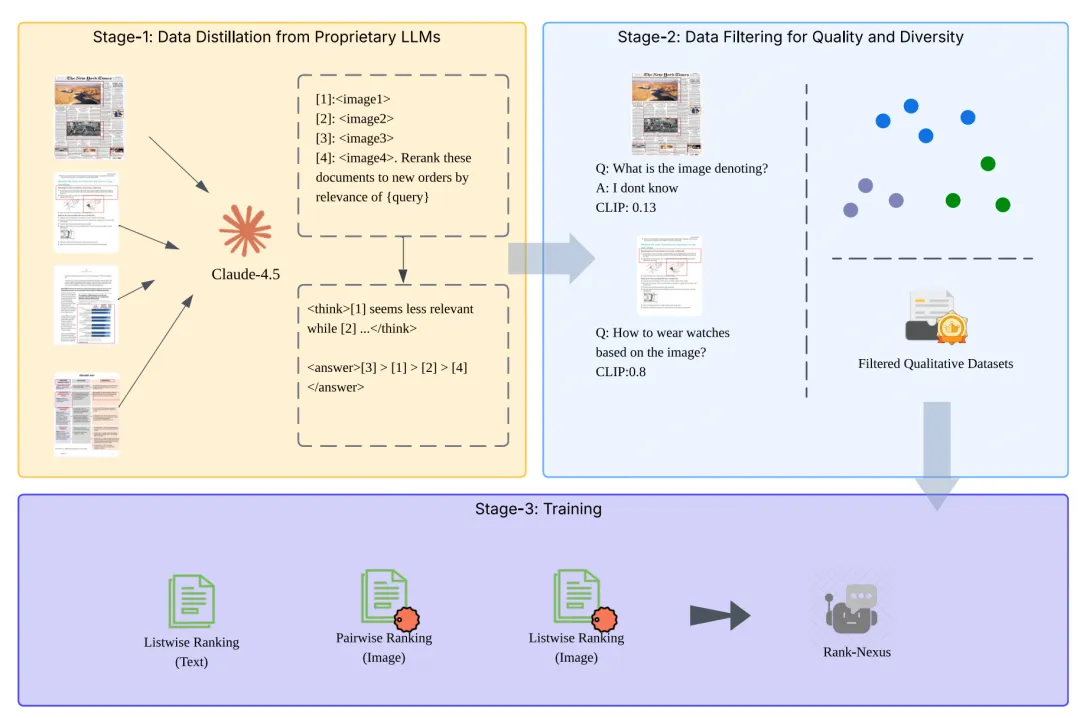
如上图,数据构造方面主要是蒸馏闭源模型和数据筛选策略:阶段1先从 Claude-4.5 中提炼多样多模态文档的成列表排序,生成包含相关性排序和解释的结构化输出。阶段2质量过滤通过 CLIP 得分阈值去除低置信度样本生成高质量的训练数据。
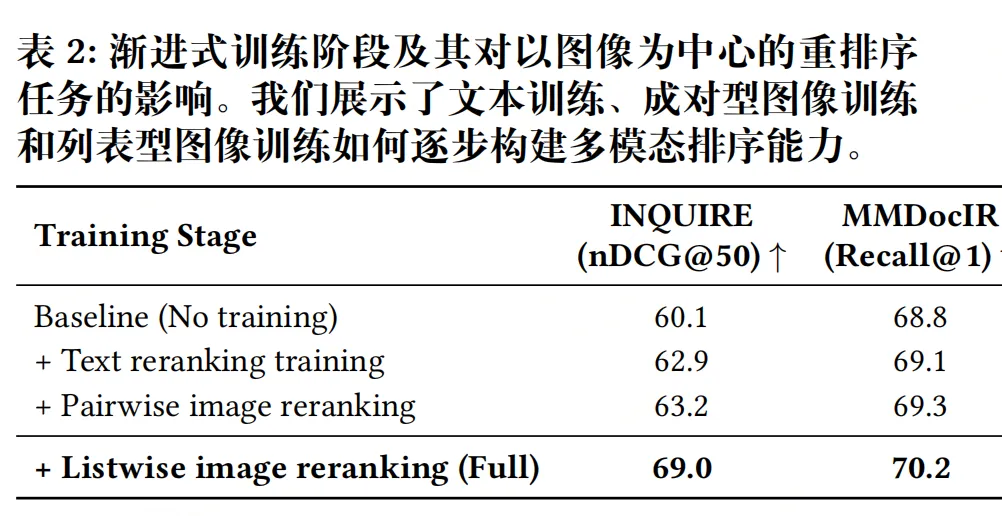
训练pipeline采用分模块训练方法(渐进式):首先分别在文本和图像模态上进行训练,然后进行联合多模态微调。
VLM backbone:InternVL-3-2B、Qwen3-VL-2B,保证轻量与性能平衡。
(1)文本重排:蒸馏 + 数据精选
解决文本重排的知识迁移与数据冗余问题:
知识蒸馏
-
教师模型:GPT-4、Claude3.5-Sonnet(生成最优列表级排序 );
-
学生模型:Rank-Nexus文本分支,拟合教师输出,最小化列表级文本重排损失:
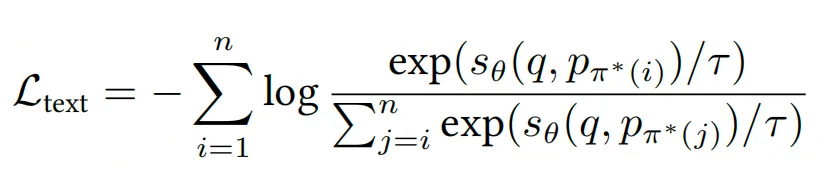
其中 为温度系数, 为模型相关性打分。
数据精选
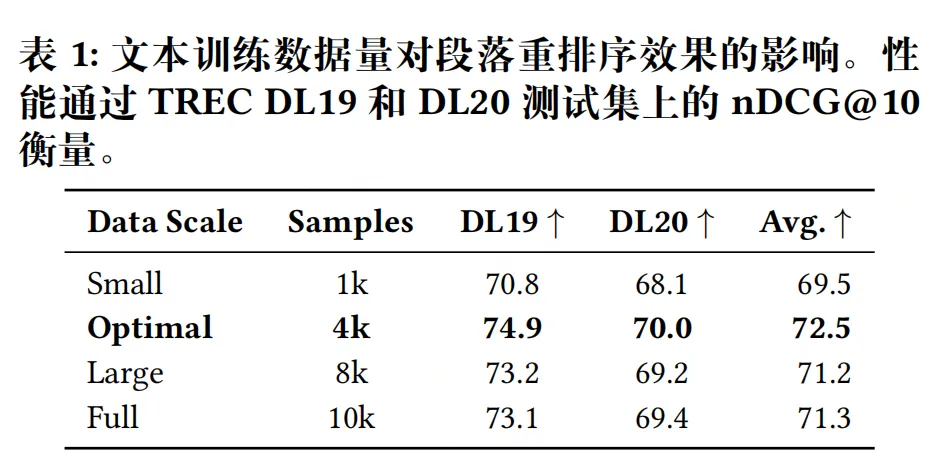
实验发现:文本训练数据并非越多越好,存在收益递减:
-
1k→4k样本:性能大幅提升; -
4k→10k样本:性能下降(冗余、噪声、过拟合)。 最终仅选取4k高质量样本(为标准100k数据的7.5%),通过置信度过滤保留教师模型高置信度排序结果。
(2)图像重排:稀缺数据的蒸馏与多样性筛选
解决图像列表级重排数据极度稀缺的问题,基于MMDocIR基准构建数据,分三步: 用CLIP计算查询-图像余弦相似度,过滤低相关样本,剔除噪声监督信号;使用贪婪最大多样性选择;图像数据蒸馏:用Claude-4.5-Haiku对每个查询的Top-20图像候选生成列表级重排标签。
(3)联合多模态微调
完成文本、图像单模态训练后,做图文混合文档联合微调:
-
初始化:加载图像训练后的模型权重(已融合文本排序能力); -
优化目标:混合模态列表级重排损失 (与文本损失形式一致,适配图文混合候选); -
伪标签生成:用闭源LLM对图文混合列表蒸馏排序标签。
各阶段输出(Prompt控制):
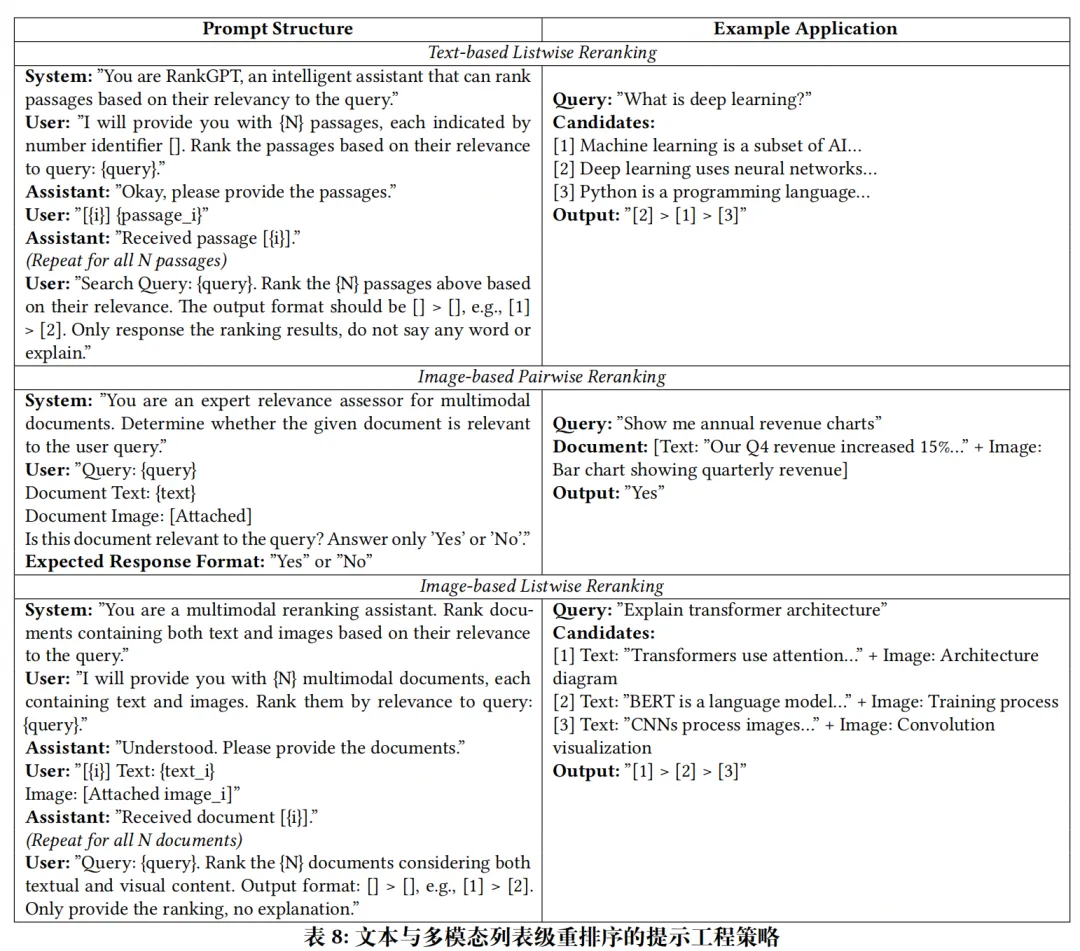
-
文本列表级:输出 [2] > [1] > [3]格式; -
图像成对:仅输出 Yes/No; -
图像列表级:同文本格式,融合图文信息排序。
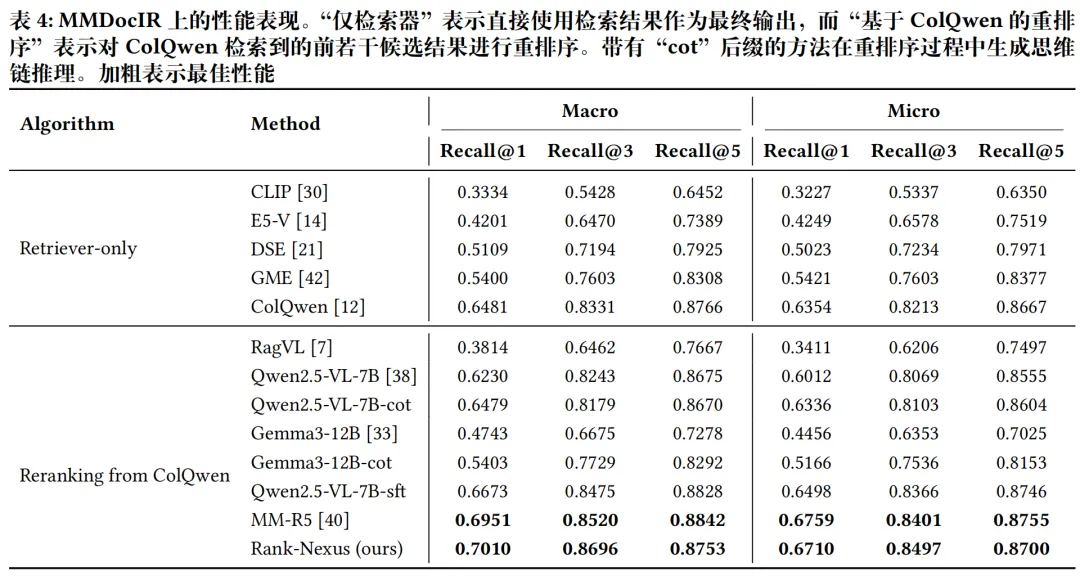
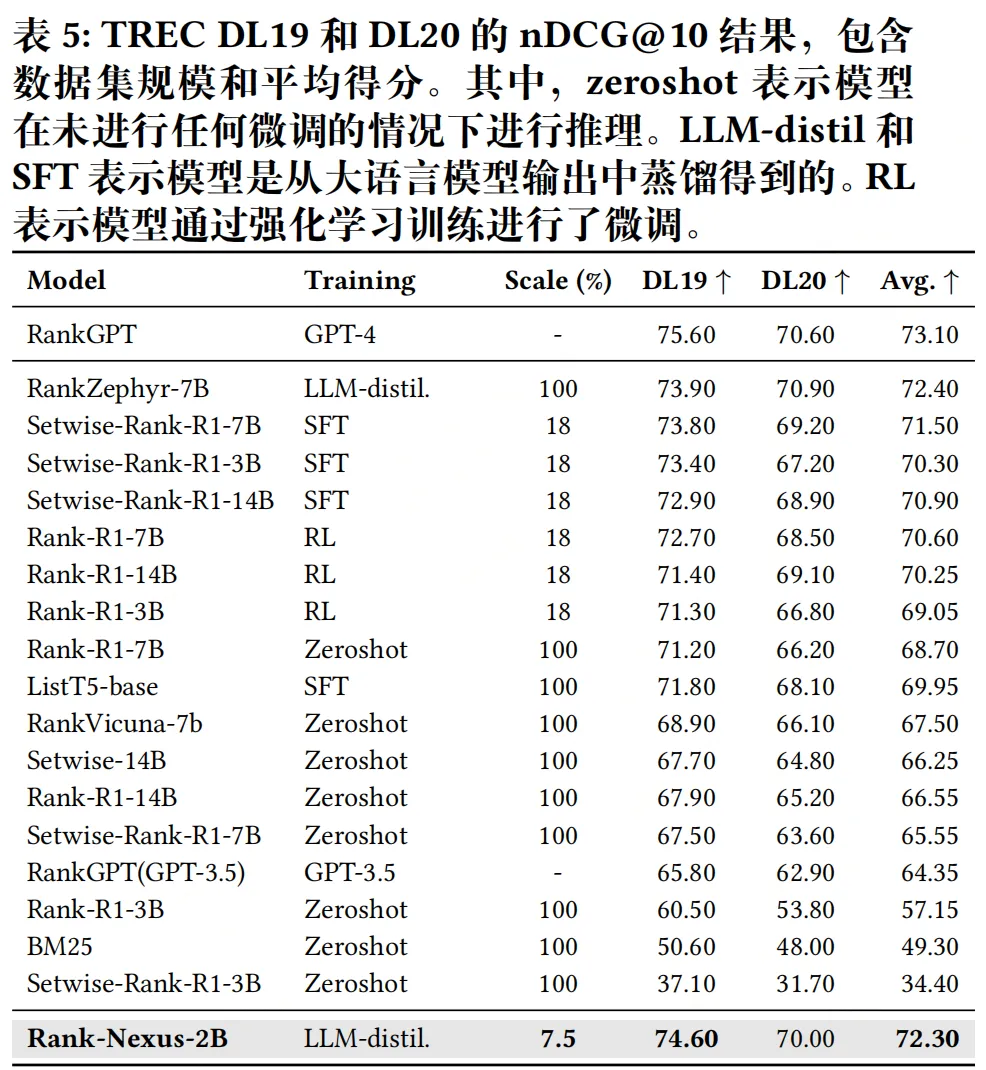
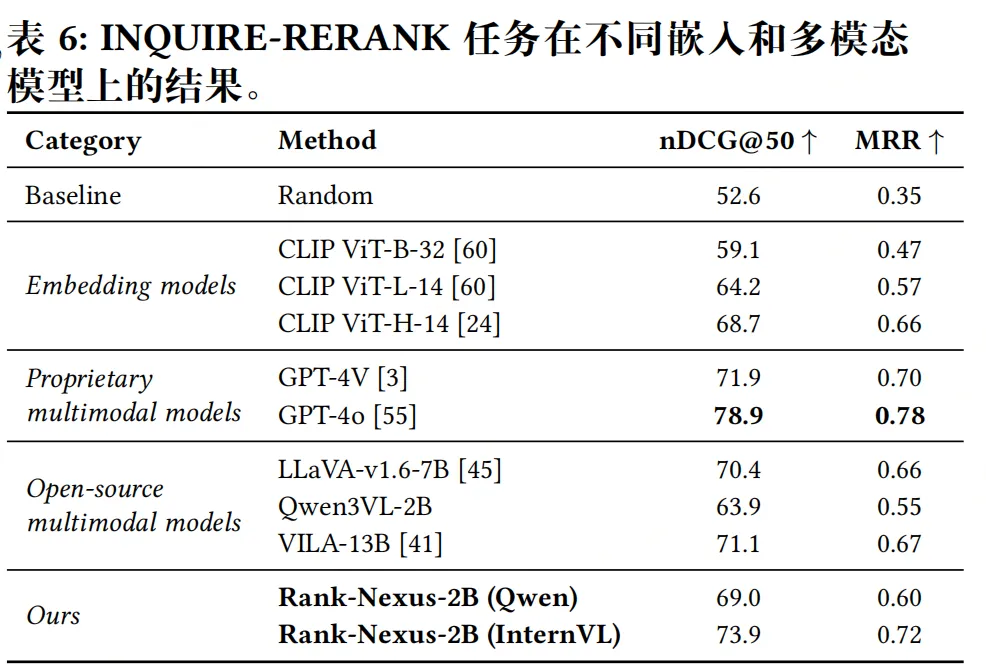
实验
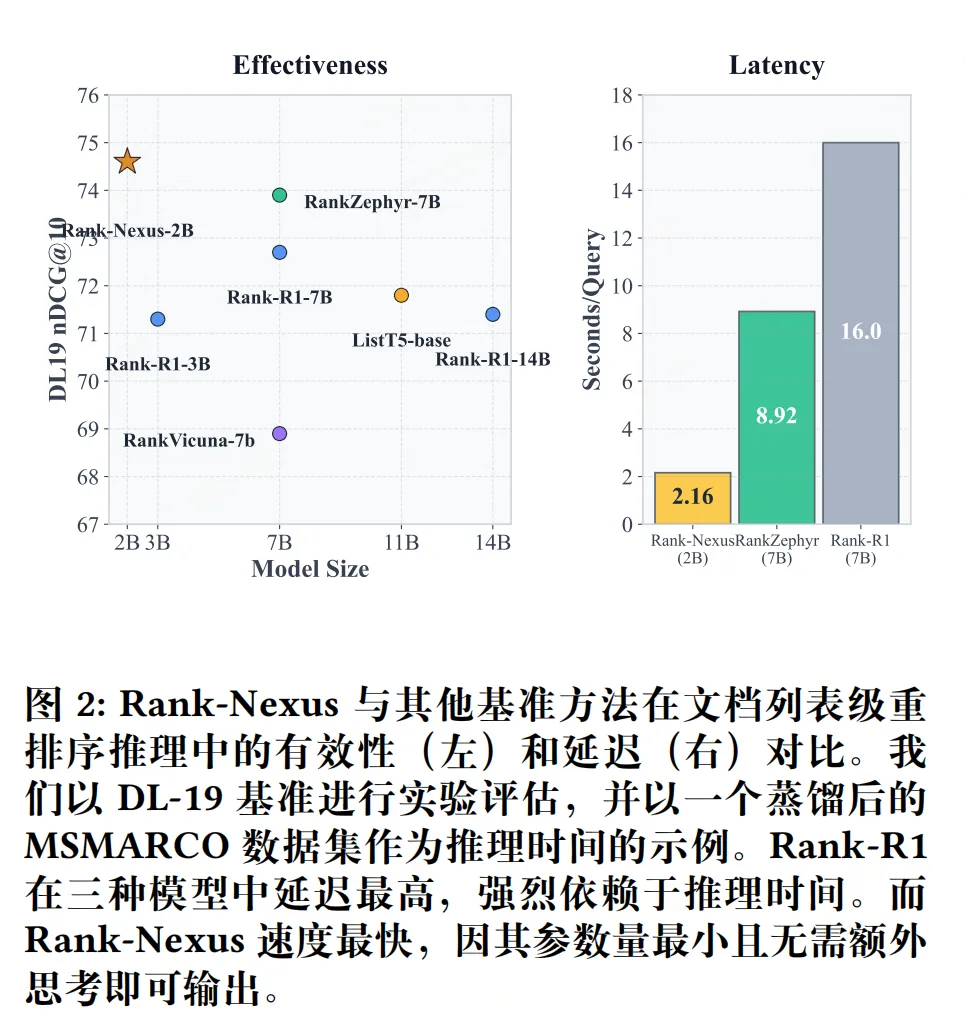
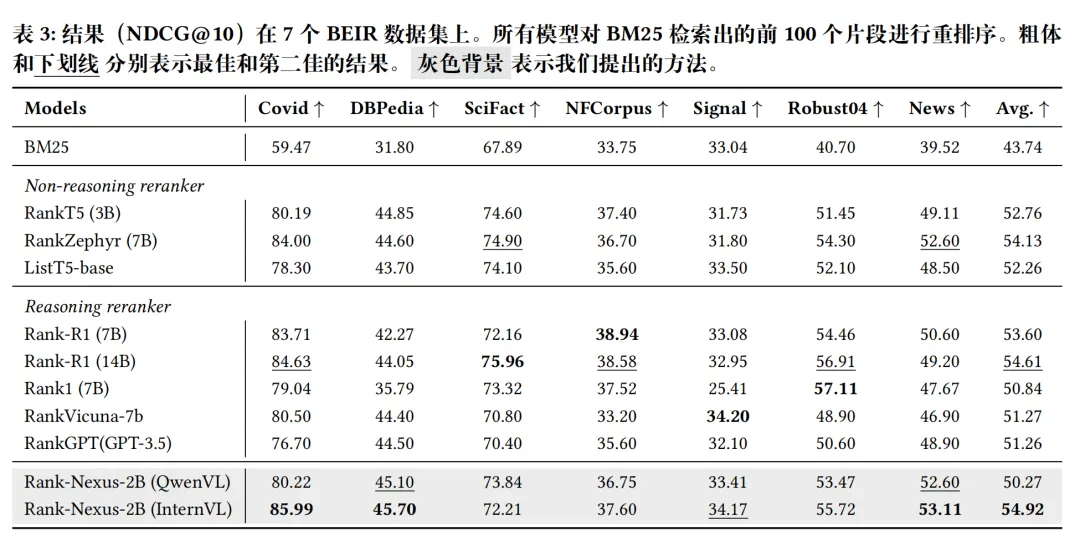
参考文献
When Vision Meets Texts in Listwise Reranking,https://arxiv.org/pdf/2601.20623