 夜雨聆风
夜雨聆风





别让GPT-4o干杂活:OpenClaw多Agent独立模型配置指南

图 1:多Agent混合模型编排概览
做过AI应用开发的朋友大概都有过这种体会:刚开始写Agent,为了图省事,直接把所有任务都挂载到GPT-4o或者Claude-4.5-Sonnet上。跑demo的时候确实丝滑,但一旦上了生产环境,面对真实流量,月底拿到API账单的那一刻,心脏总会漏跳半拍。
更要命的是,很多场景根本用不着“航空发动机”。比如,你让一个千亿参数的大模型去做单纯的文本提取、格式化JSON,这就好比开法拉利去楼下买葱——能到吗?能。划算吗?想都别想。
最近在折腾OpenClaw,发现它在多Agent编排上有一个非常讨喜的设计:支持给每个Agent独立配置底层大模型。这意味着你可以真正实现“好钢用在刀刃上”。今天就把这套配置方法论揉碎了分享出来。
为什么要拆分模型?
在讲怎么配之前,先理清一个架构逻辑。一个成熟的AI工作流,通常包含三种角色:
●大脑(路由/决策):需要极强的逻辑推理和意图识别能力。
●手脚(执行/搜索):需要稳定输出特定格式,比如调用API、写SQL。
●门面(总结/润色):需要出色的语言组织能力,但不需要太深的逻辑。
在OpenClaw里,你可以把这三者拆开。大脑用贵的,手脚用便宜且快的,门面用擅长写作的。这种混合模型编排,才是企业级Agent该有的样子。
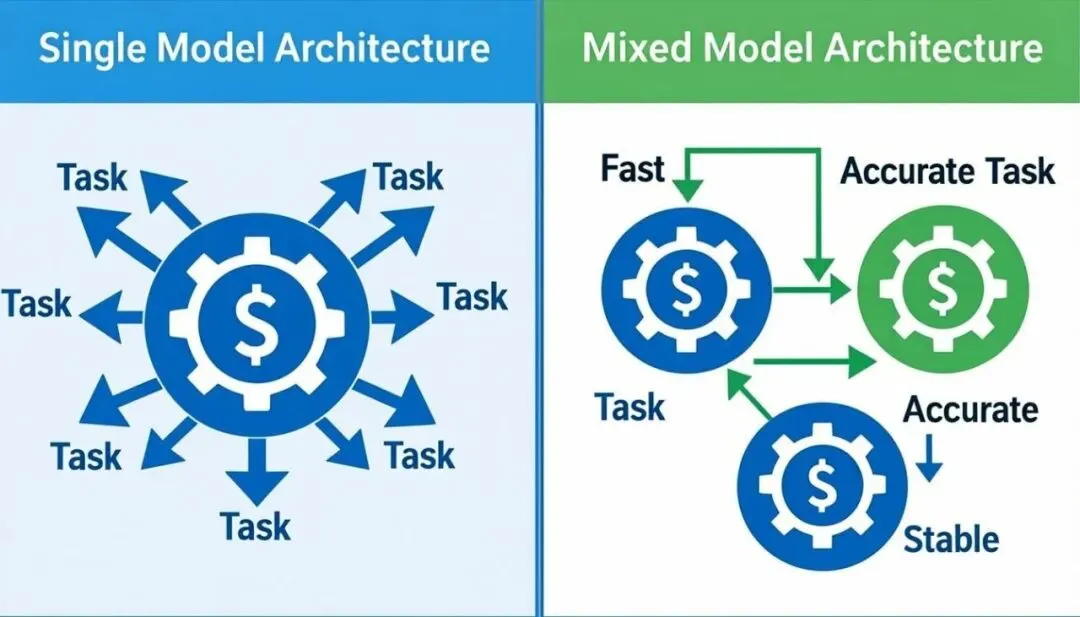
图 2:单模型架构 vs 混合模型架构对比
核心配置:三步走
OpenClaw的配置逻辑很清晰,主要分为“定义模型池”、“绑定Agent”、“组装工作流”三步。我们直接上干货。
第一步:在全局配置里注册模型池
打开项目的核心配置文件(通常是 config.yaml 或在管理后台的系统设置里),你需要先把手上有的模型都注册进去。重点是给它们起好别名(Alias),后面全靠这个来调用。
# 模型池配置示例
llm_providers:
openai:
api_key:“${YOUR_OPENAI_KEY}”
models:
–name: “gpt-4o”# 别名:超强大脑
max_tokens:4096
–name: “gpt-4o-mini”# 别名:廉价双手
max_tokens:4096
deepseek:
api_key:“${YOUR_DEEPSEEK_KEY}”
base_url:“https://api.deepseek.com/v1”
models:
–name: “deepseek-v3”# 别名:理科状元
max_tokens:8192
moonshot:
api_key:“${YOUR_MOONSHOT_KEY}”
models:
–name: “moonshot-v1-8k”# 别名:长文本处理机
max_tokens:8192
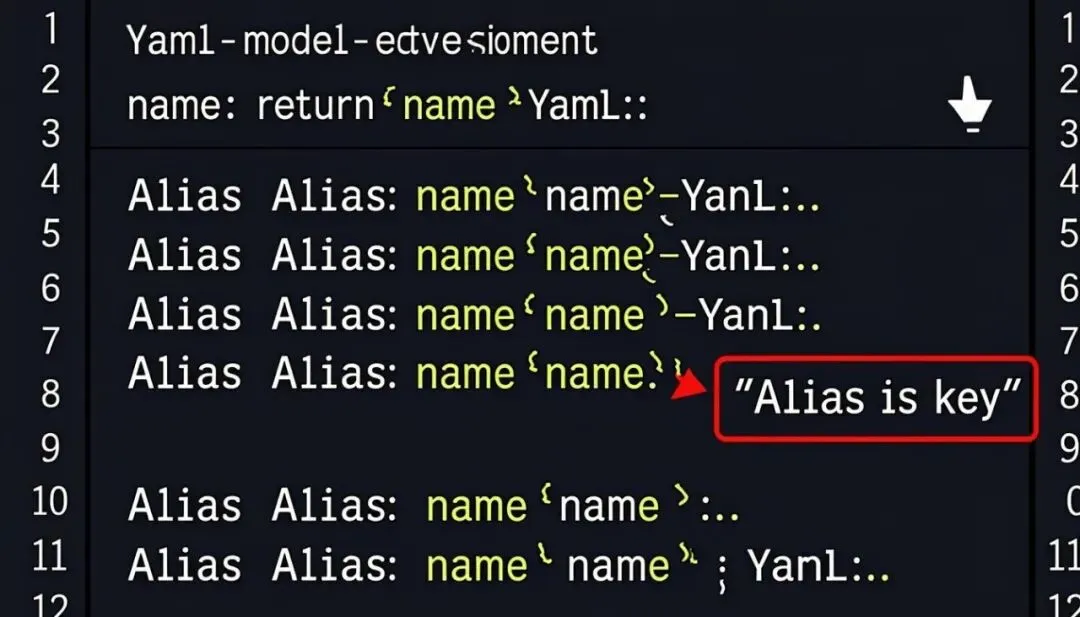
图 3:模型池配置示例,别名是关键
第二步:给每个Agent分配专属模型
这是最核心的一步。在OpenClaw中定义Agent时,不再是默认继承全局模型,而是显式指定 model 字段。我们模拟一个“竞品分析助手”的场景,看看怎么配:
Agent 1:情报分析员(负责理解需求、拆解搜索关键词)
agents:
analyst:
name:“情报分析员”
model:“gpt-4o”# 关键:用最聪明的模型做路由
system_prompt:|
你是一个资深商业分析师。用户会给你一个竞品分析需求,
你需要将其拆解为5-8个精准的搜索关键词组。
严格按照JSON格式输出。
tools:[]# 纯逻辑推理,不需要工具
Agent 2:信息采集员(负责拿关键词去搜索,提取网页内容)
scraper:
name:“信息采集员”
model:“gpt-4o-mini”# 关键:用便宜模型干苦力,降本90%
system_prompt:|
你只需要做一件事:阅读提供的网页文本,提取与“{keyword}”相关的核心数据,
剔除广告和无关信息。
输出格式:[{“fact”:“…”, “source”: “…”}]
tools:
–web_search
–page_reader
Agent 3:研报主笔(负责把零散信息写成连贯的报告)
writer:
name:“研报主笔”
model:“deepseek-v3”# 关键:DeepSeek在中文长文写作上性价比极高
system_prompt:|
你是一位拥有10年经验的券商研究员。你会收到一堆碎片化的调研事实,
请将它们组织成一份结构严谨、逻辑清晰的竞品分析报告。
要求:有摘要、有数据对比表格、有趋势判断。
tools:[]
图 4:Agent与模型的一对一绑定关系
第三步:在Workflow中串起来
有了独立的Agent,接下来就是在OpenClaw的工作流里把它们像乐高一样拼起来。
workflows:
competitor_analysis:
trigger:“user_input”
steps:
–agent: “analyst”
output_key:“keywords”# 把分析员的输出存起来
–agent: “scraper”
input_key:“keywords”# 把关键词喂给采集员
output_key:“raw_facts”# 存原始事实
loop:true# 循环执行直到搜完所有关键词
–agent: “writer”
input_key:“raw_facts”# 把事实喂给主笔
output_key:“final_report” # 最终输出
避坑指南:给不同模型写Prompt的潜规则
很多新手照着上面的配完,一跑就报错。原因往往出在提示词没有适配模型能力。这是一个很容易被忽略的细节:
你给便宜模型写Prompt,必须更加死板。
●给GPT-4o写Prompt:你可以写“请帮我分析一下这段话的意思,尽量输出JSON”。它能懂。
●给GPT-4o-mini写Prompt:你必须写“你必须且只能输出JSON,不要输出任何解释性文字。格式为:{“result”: “”}。如果无法解析,请输出 {“error”: “null”}。” 一步都不能错,否则它容易跟你扯闲篇。
另外,要注意上下文窗口的对齐。如果你让一个只支持4K上下文的小模型去读一份8K的研报,它只会读到一半然后胡说八道。在OpenClaw里配置时,遇到长文本流转的节点,务必检查上游Agent的输出长度和下游模型的 max_tokens 是否匹配。

图 5:对不同模型,态度要不一样
算一笔账
我们拿上面那个竞品分析的流程算笔账(按单次请求估算):
传统单模型方案(全用GPT-4o):分析约2000 token + 5次搜索提取约10000 token + 写作约4000 token ≈ 每次约0.35美元。
OpenClaw混合模型方案:GPT-4o分析约2000 token(0.06美元) + Mini提取约10000 token(0.015美元) + DeepSeek写作约4000 token(0.01美元) ≈ 每次约0.085美元。
成本直接降到原来的四分之一。而且因为轻量级模型的响应速度更快,整体延迟反而降低了。
写在最后
做AI应用,很容易陷入“模型崇拜”的误区,觉得只要上了最强的模型,业务问题就能迎刃而解。但现实是,生产环境拼的从来不是单点能力,而是工程化编排的精度。
OpenClaw这种把模型选择权下放到Agent级别的架构设计,其实是把复杂的AI开发拉回了软件工程的老本行——合适的组件做合适的事。
下次再搭工作流前,不妨先停下来问问自己:“这个Agent,真的配得上GPT-4o吗?”

图 6:AI工程的本质,依然是工程
—END—
我是老卢,一个越来越不想写代码,只想做产品的独立开发者。