 夜雨聆风
夜雨聆风





R软件实操|Meta回归与亚组分析:搞定Meta分析异质性的两大核心技巧

做Meta分析的小伙伴,大概率都遇到过这样的困境:
辛辛苦苦找齐文献、提取完数据,做异质性检验时却发现<I> I²</I> 值居高不下,固定效应模型根本用不了;明明是同一主题的研究,效应值却参差不齐,不知道该怎么解释这种差异;投稿时审稿人追问“是否存在效应修饰作用”“异质性来源是什么”,一时无从下手……
其实,破解这些难题的关键,就藏在两个核心分析方法里——Meta回归和亚组分析。
它们就像Meta分析的“异质性侦探”:一个擅长量化寻找异质性的“幕后推手”,一个擅长分组拆解差异的具体来源,搭配R软件实操,就能轻松搞定异质性,让你的Meta分析更严谨、更有说服力。
今天就用最通俗的语言+可直接复制的R代码,把这两个技巧讲透,新手也能快速上手!
先搞懂:为什么需要Meta回归和亚组分析?
在聊实操前,先明确一个核心前提:Meta分析的核心是“合并效应值”,但合并的前提是研究间具有同质性——也就是所有纳入的研究,本质上是在探讨同一个问题、研究人群和干预方式基本一致,效应值的差异只是随机误差导致的。
但实际研究中,完全同质性的情况很少见:比如研究对象的年龄、性别不同,干预剂量有差异,随访时间不一样,甚至研究质量高低不同,都会导致效应值出现系统性差异,这就是临床异质性或方法学异质性。
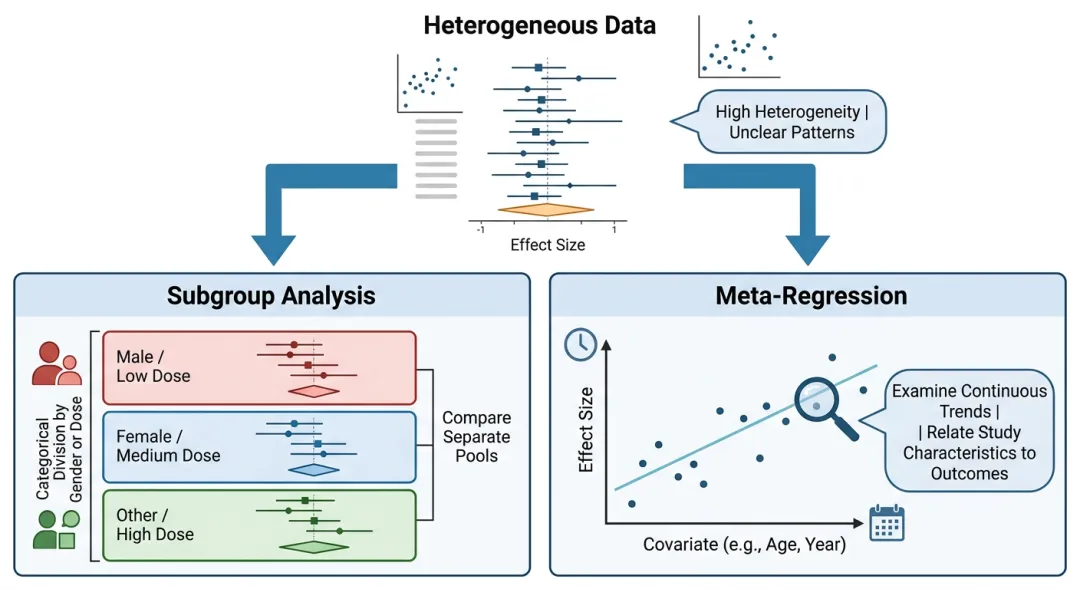
如果无视异质性强行合并,得到的合并效应值会偏差很大,甚至得出错误结论。而Meta回归和亚组分析,就是处理异质性的“黄金组合”:
-
亚组分析:相当于“分组对比”,把纳入的研究按某个特征(比如年龄、性别、干预剂量)分成几组,分别合并每组的效应值,看不同组之间的效应是否有差异,从而找到异质性的来源。
-
Meta回归:相当于“量化分析”,把可能导致异质性的因素(称为“协变量”)纳入回归模型,量化这些因素对效应值的影响程度,明确哪些因素是异质性的主要来源。
简单来说:亚组分析是“定性看差异”,Meta回归是“定量找原因”,两者结合,既能解释异质性,又能让研究结论更有针对性。比如探究某种药物的疗效时,亚组分析能看出“男性和女性疗效是否有差异”,Meta回归能量化“年龄每增加10岁,疗效效应值变化多少”。
核心区分:Meta回归 vs 亚组分析(新手必看)
很多新手会混淆这两种方法,其实只要抓住3个核心差异,就能快速区分,避免用错场景:
|
对比维度 |
亚组分析 |
Meta回归 |
|---|---|---|
|
核心目的 |
分组验证异质性,看不同组别效应差异 |
量化协变量对效应值的影响,找异质性来源 |
|
变量类型 |
多为分类变量(如性别、年龄分组、干预剂量分组) |
可是分类变量,也可是连续变量(如年龄、随访时间) |
|
结果呈现 |
各组合并效应值+森林图,直观对比 |
回归系数、P值、R²,量化协变量影响程度 |
|
适用场景 |
明确某个分类因素是否影响效应,适合简单异质性探索 |
多个因素共同影响,或需量化影响程度,适合复杂异质性分析 |
💡关键提醒:Meta回归本质上是“亚组分析的延伸”——当协变量是分类变量时,Meta回归的结果和亚组分析是一致的,但Meta回归能更精准地量化差异,还能控制多个协变量的影响,避免单一亚组分析的局限性。
R软件实操:Meta回归与亚组分析(全程复制可用)
本次实操用最常用的meta包和metafor包(两个包均可实现,按需选择),以“药物干预疗效的Meta分析”为例,假设我们纳入了10项研究,提取了效应值(OR值)、标准误(SE),以及可能的协变量(年龄、性别占比、干预剂量)。
先做好准备工作:安装并加载所需包,导入数据。
# 1. 安装并加载所需包(首次安装需运行install.packages)install.packages(c("meta", "metafor", "ggplot2", "PerformanceAnalytics"))library(meta) # 基础Meta分析、亚组分析library(metafor) # Meta回归、异质性分析library(ggplot2) # 可视化(可选)library(PerformanceAnalytics) # 检验多重共线性(Meta回归专用)# 2. 导入数据(模拟数据,可替换为自己的真实数据)# 数据说明:study=研究编号,or=效应值,se=标准误,age=平均年龄(连续变量),sex=性别占比(连续变量),dose=干预剂量(分类变量:1=低剂量,2=高剂量)data <- data.frame(study = paste0("研究", 1:10),or = c(0.58, 0.62, 0.75, 0.81, 0.49, 0.68, 0.72, 0.55, 0.85, 0.78),se = c(0.26, 0.21, 0.18, 0.23, 0.25, 0.19, 0.20, 0.24, 0.17, 0.16),age = c(52, 48, 55, 49, 56, 50, 53, 47, 51, 49),sex = c(0.52, 0.48, 0.55, 0.47, 0.58, 0.50, 0.53, 0.46, 0.51, 0.49),dose = factor(c(1,1,2,2,1,2,1,2,1,2), levels = c(1,2), labels = c("低剂量", "高剂量")))# 查看数据head(data)
运行上述代码后,能看到数据结构,确保效应值、标准误和协变量都正确导入,分类变量(如dose)已设为因子类型。
第二步:先做异质性检验(判断是否需要进一步分析)
在做Meta回归和亚组分析前,必须先做异质性检验,确认存在异质性后,再进行后续分析(即使异质性检验不显著,也可进行探索性分析,因为异质性检验的检验效能较低)。
# 用meta包做基础Meta分析,同时检验异质性meta_model <- metagen(te = or, # 效应值(这里是OR值)seTE = se, # 标准误studlab = study, # 研究编号data = data, # 数据框sm = "OR", # 效应量类型(OR值,根据自己的数据调整:MD/SMD/RR等)fixed = FALSE, # 不做固定效应模型random = TRUE # 做随机效应模型(异质性存在时必用))# 查看结果(重点看异质性检验的I²和P值)summary(meta_model)# 输出异质性结果cat("异质性检验 I² =", meta_model$I2, "%, P值 =", meta_model$pval.Q)
结果解读:如果<I> I²</I> > 50%、P < 0.1,说明存在中重度异质性,需要进一步用亚组分析和Meta回归探索来源;如果<I> I²</I> ≤ 50%,可根据研究设计,选择是否进行探索性分析。
第三步:亚组分析(分组探索异质性)
这里以“干预剂量(dose)”为分组变量,做亚组分析,看低剂量和高剂量组的效应是否有差异,从而判断剂量是否是异质性来源。
# 用meta包做亚组分析(按dose分组)subgroup_model <- update(meta_model, by = dose) # by=分组变量# 查看亚组分析结果summary(subgroup_model)# 绘制亚组分析森林图(发表级质量,可直接用于论文)forest(subgroup_model,sortvar = te, # 按效应值排序prediction = TRUE, # 显示预测区间print.tau2 = FALSE, # 不显示tau²值leftlabs = c("研究", "OR", "SE"), # 左侧标签main = "不同干预剂量的亚组分析森林图", # 标题xlab = "OR值(OR<1表示干预有效)" # X轴标签)
结果解读:
-
看各组的合并效应值:如果低剂量组OR=0.65,高剂量组OR=0.78,说明高剂量组效应略弱(需结合95%CI判断是否有统计学差异);
-
看各组异质性:如果分组后,每组的<I> I²</I> 值明显降低,说明该分组变量(干预剂量)是异质性的主要来源;
-
森林图中,若两组的95%CI不重叠,说明两组效应存在统计学差异,即干预剂量对疗效有显著影响。
补充:如果需要按多个变量分组(如同时按剂量和年龄分组),可将分组变量合并为新的因子变量,再进行分析。
第四步:Meta回归(量化协变量影响)
假设我们怀疑“平均年龄(age)”和“干预剂量(dose)”是异质性来源,用Meta回归量化这两个协变量对效应值(OR)的影响,同时控制性别占比(sex)的干扰。
# 1. 检验协变量间的多重共线性(避免协变量高度相关,导致结果偏差)# 选择要纳入的协变量(age、sex、dose)covariates <- data[, c("age", "sex")] # dose是分类变量,单独处理chart.Correlation(covariates) # 绘制相关性图,若相关系数>0.7,需剔除一个协变量# 2. 用metafor包做Meta回归(rma函数更灵活,支持多协变量)# 先将OR值转换为log(OR)(Meta回归需用连续效应值,OR值需对数转换)data$logor <- log(data$or)data$logor_se <- data$se / data$or # log(OR)的标准误# 构建Meta回归模型(mods=纳入的协变量,连续变量直接放入,分类变量需设为因子)meta_reg <- rma(yi = logor, # 转换后的效应值(logOR)sei = logor_se, # 转换后的标准误data = data, # 数据框method = "ML", # 最大似然法(常用)mods = ~ age + sex + dose, # 纳入的协变量(age、sex为连续变量,dose为分类变量)test = "knha" # 稳健性检验,减少小样本偏倚)# 查看Meta回归结果summary(meta_reg)# 3. 可视化Meta回归结果(以年龄为例,看年龄对效应值的影响)# 提取回归系数,绘制散点图+回归线reg_df <- data.frame(age = data$age,logor = data$logor,se = data$logor_se)ggplot(reg_df, aes(x = age, y = logor)) +geom_point(size = 3) + # 散点图(代表每个研究)geom_errorbar(aes(ymin = logor - 1.96*se, ymax = logor + 1.96*se), width = 0.5) + # 95%CIgeom_abline(intercept = meta_reg$b[1], slope = meta_reg$b[2], color = "red", lwd = 1.2) + # 回归线labs(x = "平均年龄(岁)",y = "log(OR)值",title = "年龄对干预疗效的Meta回归分析",subtitle = paste0("回归系数 = ", round(meta_reg$b[2], 3), ", P值 = ", round(meta_reg$pval[2], 3))) +theme_minimal()
结果解读(重点看3点):
-
回归系数(coefficient):正值表示协变量增大,效应值(logOR)增大(即OR值增大,干预疗效减弱);负值表示协变量增大,效应值减小(干预疗效增强)。比如年龄的回归系数为0.012,说明年龄每增加1岁,logOR增加0.012,OR值增加exp(0.012)≈1.012,即疗效轻微减弱;
-
P值:P < 0.05说明该协变量对效应值有显著影响,是异质性的主要来源;P > 0.05说明该协变量对效应值无显著影响;
-
R²值:表示该模型能解释的异质性比例,R²越大,说明纳入的协变量越能解释异质性(比如R²=0.6,说明60%的异质性可由这些协变量解释)。
实操避坑指南(新手必看)
很多小伙伴实操时容易出错,这里总结4个高频坑,帮你避坑:
-
协变量选择别“贪多”:Meta回归的纳入研究数量至少是协变量数量的10倍,否则会导致模型不稳定,结果不可靠。比如纳入10项研究,最多纳入1个协变量;纳入20项研究,最多纳入2个协变量。
-
分类变量需“因子化”:做亚组分析或Meta回归时,分类协变量(如性别、剂量)必须设为因子类型(factor),否则R会将其当作连续变量处理,导致结果错误。
-
效应值转换要正确:如果效应值是OR/RR值,做Meta回归时必须转换为log(OR)/log(RR),标准误也要对应转换,否则回归结果会严重偏差。
-
避免“数据挖掘”:协变量最好在研究设计阶段就预先设定,不要为了“找到异质性来源”,反复尝试不同的协变量组合,否则会增加假阳性风险。如果确实需要探索多个协变量,可采用多模型推理的方法,全面评估模型性能。
最后总结
Meta回归和亚组分析,是Meta分析中处理异质性、深化研究结论的核心方法——亚组分析“定性分组找差异”,Meta回归“定量建模找原因”,两者结合,能让你的Meta分析从“简单合并”升级为“深度分析”,更易通过审稿。
本次实操的代码的可直接复制,替换为自己的数据(效应值、协变量)即可运行;如果需要更复杂的分析(如交互效应、稳健性检验),可以在评论区留言,后续再补充。
记住:异质性不可怕,只要用对方法,就能把“麻烦”变成“亮点”,让你的Meta分析更有学术价值~