 夜雨聆风
夜雨聆风





AI自进化?她让我后背发凉

凌晨 2 点到早上 6 点,她一刻都停不下来。
不是在加班。不是在赶 deadline。
是因为太兴奋了,根本睡不着。

说这话的人叫罗福莉。阿里达摩院出身,DeepSeek V2 核心作者之一,后来被小米千万年薪挖走,现在负责小米大模型团队 MiMo。
这种履历的人,平时惜字如金。但最近她接受了张小珺的深度访谈,将近两万字,这是她第一次接受技术访谈。
我通读了全文,把最核心的信息压成这篇。有些是技术判断,有些是行业洞察,有些是她个人的经历和直觉。
但最后有一句话,单独拎出来,我建议你认真想一想。
因为那可能关系到我们每个人的未来。
01 游戏规则变了,但 99% 的人还没反应过来

先说结论。
罗福莉最核心的判断是:AI 的范式已经发生了根本性转变。
从预训练主导的 Chat 时代,进入了后训练主导的 Agent 时代。
标志性事件是两个:OpenClaw 的发布,和 Claude Opus 4.6 的问世。
如果你没关注这两件事,我给你翻译一下——
行业的技术焦点,已经从“让模型更聪明”转向了“让模型能做事”。
听起来差别不大?其实是两个完全不同的工程问题。
让模型更聪明,核心是预训练:砸算力,堆数据,把模型做大。这条路大家已经跑了三四年,卷到今天,边际效益在急剧下降。简单说,就是投入越来越大,回报越来越少。
让模型能做事,核心是后训练和 Agent 框架:用强化学习教模型在具体场景中做决策,用精巧的编排让模型调用工具、规划步骤、完成复杂任务。
前者的天花板是模型的智力。
后者的天花板是框架的设计。
而罗福莉说,框架的天花板,比你想象的高得多。
高到什么程度?往下看。
02 春节凌晨 2 点,她像着了魔一样
回到文章开头那个场景。
春节期间,凌晨两点,罗福莉装上了 OpenClaw。然后一直用到早上六点。
不是在加班。不是在赶项目。是停不下来。
她自己是这么描述的:
第一天,她感受到的是产品的“灵魂感”——设计的温度和情商超出预期。
想想看,一个搞了大几年底层模型的技术大牛,用“灵魂”这个词来形容一个产品框架。这个冲击有多大?
第二天,她发现 OpenClaw 能帮她完成日常生活和工作中以前做不到的事。
第三天,她把研究任务交给它,一两个小时就做出了她以为要花很久的 User Agent 构建。
三天之内,她的认知被彻底刷新了。
但更震撼的还在后面。
她说,把自己的 MiMo 模型接进 OpenClaw 之后,一个中层模型借助好的框架,在 85% 的任务上就能接近 Claude Sonnet 的水准。
甚至一个 3B 的端侧小模型,在这套框架下也能做出超乎想象的事。
科普一下:3B 模型大概是你手机上能跑的模型级别。
这种模型,放在 Chat 时代,跟顶级模型的差距是天堑。但配上好的 Agent 框架之后,天堑变成了沟壑。
罗福莉由此得出了一个判断:
Agent 框架和模型能力必须同步进化,互相推动。单纯卷模型的时代,结束了。
03 “对话不到 100 轮就辞职”,她是认真的

回到小米之后,她做了一件很猛的事。
要求全团队必须用 OpenClaw。
原话是:如果第二天对话次数不超过 100 轮,就辞职。
她后来澄清说不会真的考核,只是想传递态度。但这个“态度”本身已经说明了一切——
她不是在建议团队试用新工具。
她是在用近乎暴力的方式,推动一场认知革命。
结果呢?
团队被彻底点燃了。
将近 100 个人在飞书群里疯狂探索,10 分钟不看就 999+。
她说这种群体智能的爆发,让他们三四周做完了以前三四十周的研究量。
三四十周是什么概念?
大半年的工作量,被压缩到不到一个月。
我读到这段的时候,脑子里闪过四个字:
组织范式转移。
你看,模型的技术范式在变——从预训练到后训练。
组织的协作范式也在变——从人写代码到人跟 AI 协作。
而且后者的速度可能更快。
为什么?
因为技术范式的转移需要算力和数据,但组织范式的转移只需要两样东西:
一个足够有感染力的人 + 一个足够好的工具。
罗福莉恰好是前者。OpenClaw 恰好是后者。
04 一组数据,暴露了行业的秘密
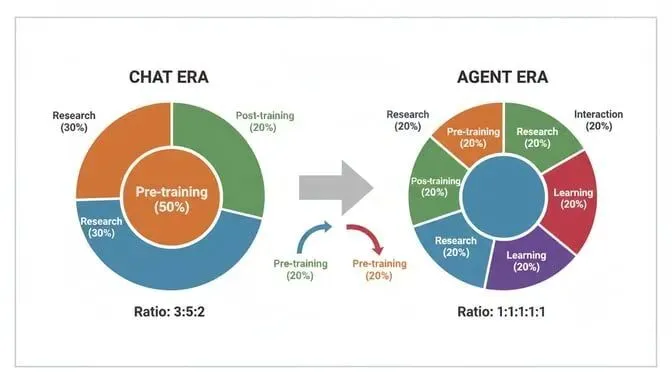
她透露了一个很能说明问题的数据。
在 Chat 时代,一个 AI 团队的算力分配是这样的:
研究:预训练:后训练 = 3:5:2
现在呢?
合理的比例变成了 3:1:1
预训练和后训练的算力投入已经持平。顶尖团队应该都是 1:1 了。
这个数字意味着什么?
行业花了三年时间、烧了无数张卡堆出来的预训练能力,现在跟后训练站到了同一条线上。
不是说预训练不重要了。
而是后训练的权重,被严重低估了。
以前后训练是锦上添花。
现在是半个江山。
05 为什么放弃“完美”,选择“弹性”?

关于 MiMo 的技术选择,她讲了一个很有意思的故事。
MiMo 为什么选择 MTP(多词元预测)而非 MLA(多头潜在注意力)?
要知道,MLA 在 Chat 时代确实非常优秀。DeepSeek V2 用的就是 MLA,她作为核心作者当然清楚。
但她说了一句话:MLA 把计算和访存的比例优化到了极致临界点。
极致是什么意思?
就是好到没有调整空间了。
没有调整空间就意味着没有弹性。
而 Agent 时代需要的恰恰是弹性——长上下文、快速推理、灵活的架构适配。
MiMo 选择的 Hybrid Attention 加 MTP 组合,天然适合这个场景:
-
长上下文成本低
-
推理速度快
-
架构有弹性
她说这个选择当时有一定偶然性,但回头看恰好完美适配了 Agent 时代的需求。
很多伟大的技术决策,当事人在做的时候并不是因为看到了未来,是因为某种直觉。
但事后看,那种直觉恰好对了。
06 100 个人的团队,没有职级,没有 deadline

MiMo 团队大约 100 人。
没有职级。没有小组划分。没有 deadline。
训练 1T 模型的核心团队只有几个人。
她招人更看重好奇心和热爱,甚至开始倾向招大二大三的本科生——
不是因为便宜,是因为他们的想象力没有被禁锢。
她说团队成员之间像“互相蒸馏”一样快速成长。
“互相蒸馏”这个词用得妙。
科普一下:蒸馏在模型训练里是一个核心概念——用大模型的知识训练小模型,让小模型在保持能力的同时变得更快更轻。
但这个概念用在人身上,含义更丰富:
每个人都在从周围人身上吸收知识、方法、思维方式,然后内化成自己的。
在一个没有层级的环境里,信息的流动没有摩擦。
-
你不需要“汇报”给谁,你只需要“分享”给所有人
-
你不需要等待审批,你只需要直接行动
这种组织模式能不能适用于所有团队?我不确定。
但我知道,在一个快速变化的领域里,传统的层级制和 deadline 驱动,确实会压制最稀缺的东西:创造力。
07 AGI 还有多远?她给出了一个时间表

她对 AGI 的时间判断很激进。
目前走到 20%。
今年年底能到 60% 到 70%。
两年内应该能实现。
先颠覆工作模式,然后才是生活模式。后者需要等机器人技术跟上。
这些数字我没有办法验证。
但她的逻辑链条是清晰的:5555
如果 Agent 框架能弥补模型短板,如果模型和框架同步进化,如果强化学习的 scaling 还能继续——
那这个速度确实有可能。
前提是这些“如果”全部成立。
08 最后这句话,让我后背发凉
整个访谈里最让我印象深刻的一句话,不是关于技术路线的,不是关于算力分配的。
是这句。
她说自己以前认为,训模型这种工作足够有创造力,不会被 Skill 化和 Workflow 化。
但现在发现,AI 竟然也能做到。
然后她问了一个问题:
“那它能不能自己训出更强的模型?自己左脚踩右脚就提升了?”
她说这是一两年内会发生的事情。
这句话听起来很平静。你甚至可以说她只是在陈述一个技术判断。
但你仔细想想。
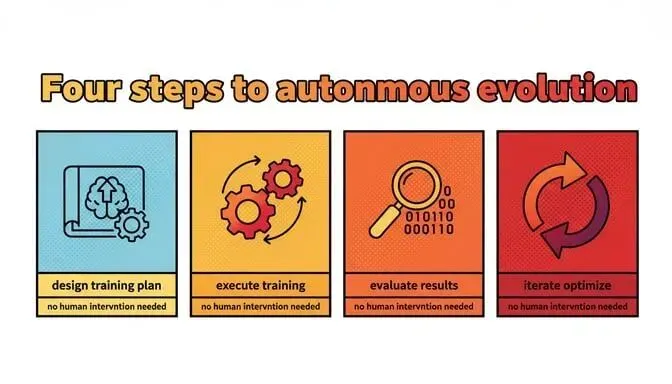
一个 AI 系统,能够:
-
自己设计训练方案
-
自己执行训练
-
自己评估结果
-
自己迭代优化
不需要人类介入。
不需要人类告诉它怎么做得更好。
它自己就能让自己变得更强。
然后更强的自己,再去训练下一个更强的自己。
左脚踩右脚。一个闭环。
如果这真的在一两年内发生,那我们面对的就不是“AI 替代某项工作”的问题了。
是“AI 能不能替代自己进化的过程”的问题。
而这,可能才是 AGI 真正的定义。
写在最后:
我不知道罗福莉的判断是否准确。
但我知道,当一个训出 DeepSeek V2 的核心作者,一个被小米千万年薪挖走的技术大牛,说出这样的话时——
至少值得我们认真想一想。
因为这可能关系到我们每个人的未来。
你怎么看?欢迎在评论区聊聊你的想法。
· END ·
本文内容整理自张小珺对罗福莉的深度访谈。如果你对 AI 行业的技术趋势感兴趣,建议关注这两位的动态。
点个“在看”,让更多人看到这篇文章👇