 夜雨聆风
夜雨聆风





AI模型被抄袭,能告吗?全国首例生效判决:构成不正当竞争,赔160万
字数:约3090字 | 阅读时间:约7分钟
摘要:抖音投入千万研发的AI特效模型,被B612照搬——33层参数完全一致(91.7%)。全国首例生效判决认定:抄袭AI模型结构与参数构成不正当竞争,判赔160万。本文拆解法院的裁判逻辑,划出AI行业的三条法律边界,帮创业者看清如何保护自己的AI资产。
一、投入千万的模型被照搬,能告吗?
2020年夏天,抖音的工程师团队完成了一项耗时数月的攻坚:一款能把真人照片实时转化为日系漫画风格的AI特效。背后是超过两万张手绘素材的标注整理、千万级别的研发投入,以及一个36层卷积层的深度神经网络。
两个月后,B612(亿睿科)上线了功能几乎相同的”少女漫画特效”。
不只是效果相似——连人脸畸变、下巴缺失这些技术瑕疵都一模一样。
这不是巧合。北京知识产权法院在2026年4月发布的年度十大典型案例中,用这份判决给出了明确答案:抄袭AI模型的结构与参数,构成不正当竞争,需承担赔偿责任。 判赔金额:160万元。
这是全国范围内首例针对AI模型抄袭的生效判决,也是第一次由二审法院明确将”模型结构与参数”纳入反不正当竞争法的保护范围。
二、91.7%的相似度
先看事实。
2020年6月,抖音正式上线”变身漫画特效”。这款功能的背后,是一个经过反复调优的AI模型——36层卷积层构成的神经网络,训练数据包括两万余张人工手绘素材。从数据采集到模型上线,整个研发周期横跨数月,直接成本达到千万级别。
同年8月,B612推出了”少女漫画特效”。
两款特效的视觉输出高度雷同,这本身不罕见——同类产品功能趋同很正常。但问题在于细节:抖音模型中存在的特定技术瑕疵(比如某些角度下的人脸畸变、下巴区域缺失),在B612的输出结果中出现了完全一致的”复刻”。
技术比对的结果更说明问题。
两家模型均为36层卷积结构,其中33层参数完全一致,相似度达到91.7%。面对这一数据,被告方无法提供任何独立研发的过程性证据——没有训练日志、没有调参记录、没有版本迭代文档。

91.7%。
这个数字在一审(北京市朝阳区人民法院)和二审(北京知识产权法院)的审理中,都成为了核心事实依据。
两级法院均认定:亿睿科的行为构成不正当竞争,赔偿抖音160万元。
三、法院为什么认定不正当竞争
这个案件的法律逻辑,值得每一位AI从业者细读。
保护对象:模型结构与参数属于”竞争利益”
法院首先回答了一个前提问题:AI模型的结构与参数,能不能作为法律保护的对象?
判决书给出了肯定的答案。理由可以概括为一个链条:原告投入了大量人力、物力、财力,并在此基础上进行了创造性劳动,由此形成的模型结构与参数,为原告带来了创新优势和经营收益——这属于《反不正当竞争法》所保护的”竞争利益”。
换句话说,法院没有把AI模型看作一段”代码”或一组”数据”,而是将其视为企业通过实质性投入所获得的竞争优势。这种竞争优势,和传统意义上的商业秘密、客户名单、技术配方处于同一法律地位。
行为定性:直接复制违反AI领域商业道德
认定了保护对象,下一步是判断被告的行为是否”不正当”。
法院的核心论证是:被告直接复制了原告的模型结构与参数,跳过了本应投入的研发环节,在极短时间内推出了功能高度一致的产品,快速分流了原告的用户。这种行为违反了AI领域的商业道德,扰乱了市场竞争秩序。
值得注意的是,法院特别强调了”节省研发投入”这一要素。在AI行业,模型的研发成本(数据采集、标注、训练、调优)往往远超最终产品的开发和运营成本。抄袭者通过直接复制参数,实现了”零研发成本”的产品上线——这对原创者形成了一种结构性的不公平竞争。
为什么不是著作权侵权?
抖音在起诉时,同时主张了著作权侵权和不正当竞争。法院只支持了后者。
原因在于:由AI模型生成的漫画图像,并不构成著作权法意义上的”作品”。法院认为,这些图像是算法自动处理的结果,缺乏人类作者的独创性表达。
这个认定看似限制了保护范围,实际上揭示了一种更精准的法律路径:著作权保护的是”表达”,反不正当竞争法保护的是”投入”。当AI生成物本身难以获得著作权保护时,反不正当竞争法成为兜底——它保护的不是某一张漫画图片,而是创造这个漫画效果的模型背后的全部投入。
这也意味着,即使两个模型的输出效果相似,只要参数和结构不是抄袭的,就不构成不正当竞争。法律保护的是”你抄了我的模型”,而非”你做的东西和我长得像”。
四、三条边界:AI行业的法律红线
这个判决为AI行业划出了三条清晰的法律边界。
|
行为 |
法律定性 |
典型表现 |
|
抄袭模型结构/参数 |
构成不正当竞争 |
直接复制神经网络层数、权重参数、卷积核 |
|
独立研发自有模型 |
合法,受保护 |
自有训练数据、自主调参、独立架构设计 |
|
仅模仿功能效果 |
不构成侵权 |
用不同模型架构实现相似的视觉效果 |

这意味着什么?
对AI创业者来说,第一条红线最有现实意义:你花了几百万甚至几千万训练出来的模型,如果有人照搬,现在有了明确的法律依据去追责。赔偿金额(本案160万)可能无法完全覆盖研发投入,但”抄袭=违法”这个定性的信号价值远超数字本身。
第二条线同样重要——它划出了安全区。只要你用的是自有数据、自主调参、独立架构,哪怕最终产品和别人”撞脸”,法律上也站得住脚。
第三条线则说明,法律保护的不是”效果”本身,而是实现效果的”路径”。功能模仿是市场竞争的常态,法律不禁止你做出一个更好的同类产品;法律禁止的是跳过研发、直接偷走别人模型的”捷径”。
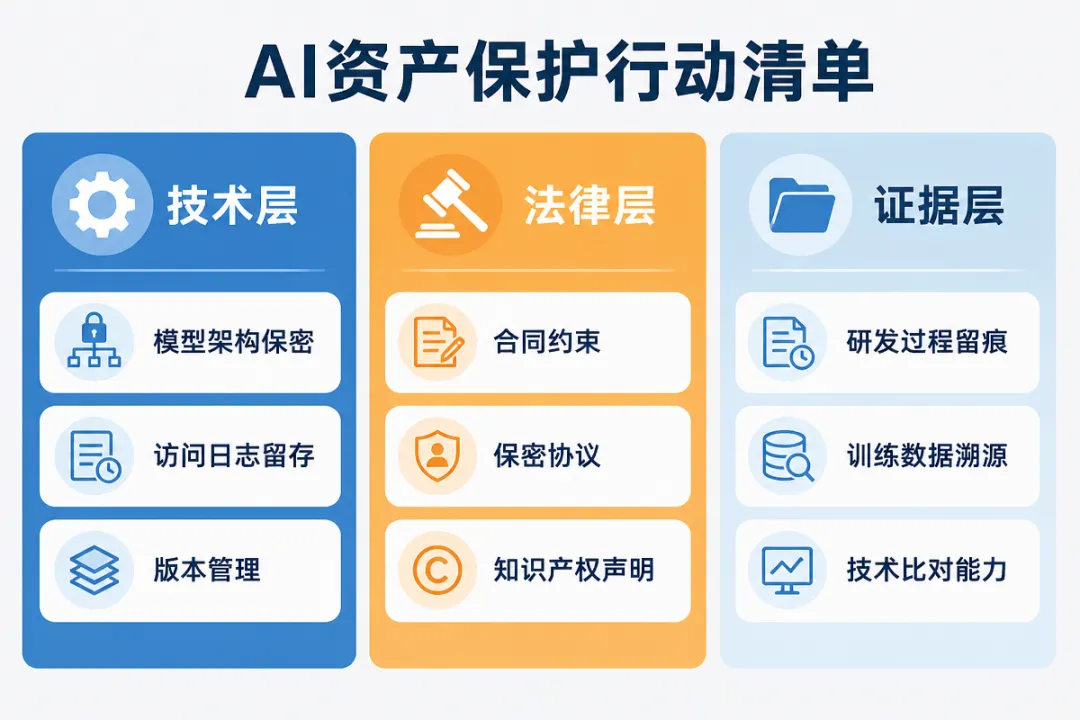
五、创业者行动指南:如何保护你的AI资产
判决给出了规则,但规则能否发挥作用,取决于你有没有做好准备工作。以下是三个层面的实务建议。
技术层面
模型架构和参数是核心资产,访问权限应当严格管控。内部的模型文件不应部署在开放环境中,对外提供的API接口也应避免泄露模型结构信息。同时,训练过程的日志、版本迭代的记录、参数调优的历史——这些看似琐碎的技术文档,在诉讼中可能成为证明”独立研发”的关键证据。
法律层面
在合作开发、技术外包、员工入职等场景中,通过合同条款和保密协议明确约定AI模型相关知识产权的归属和保密义务。员工离职时,模型参数的交接和清理流程同样需要制度化。
证据层面
这一条最容易被忽略,也最关键。如果有一天你需要证明”别人抄了我的模型”,你需要先证明”这个模型是我做的”。研发过程中的会议纪要、代码提交记录、数据采购合同、训练日志——这些材料构成了一个完整的证据链。没有证据链,再好的法律规则也帮不了你。
六、AI模型保护的序幕才刚拉开
抖音诉B612案的意义,不在于160万的赔偿金额——对两家公司来说,这个数字不算大。真正重要的是,法院第一次用生效判决确认了:AI模型的结构与参数,是受法律保护的无形资产。
这个规则在2026年之前是不明确的。很多AI创业者的共识是”模型参数没法保护,被抄了只能认”。现在,这个共识被打破了。
当然,一个判例解决不了所有问题。赔偿标准如何量化、开源模型的保护边界在哪里、跨境抄袭如何追责——这些都还有待后续案件和立法来回答。但至少,第一步已经迈出去了。
对于每一个在AI赛道上投入真金白银的创业者,这个判决传递的信号足够清晰:你的模型,法律开始保护了。前提是,你得先做好自己的功课。
—
景桁法律观察 | 守正·合规避坑,让法律意识成为商业直觉
懂商业的法律观察者,法学背景+创业经验
从商业角度解读法律,帮助创业者避坑
—
#AI模型抄袭#不正当竞争#AI知识产权保护#反不正当竞争法#AI创业法律风险
—
本文内容基于公开判决信息整理分析,不构成法律意见。如需具体法律咨询,请后台联系。
景桁 | 构架愿景,创造未来
闻道·致知·格物·见智·守正·明医
—— 景桁法律观察 ——
守正·让法律意识成为商业直觉
本文由 景桁法律观察 原创,欢迎转发分享
转载请注明出处,商业合作请联系作者
如果觉得有用,请点个“在看”,让更多人看到
本文配图由 AI 辅助生成